elasticsearch介绍
我们建立一个网站或者程序,希望添加搜索功能,发现搜索工作很难:
- 我们希望搜索解决方案要高效
- 我们希望零配置和完全免费的搜索方案
- 我们希望能够简单的通过json和http与搜索引擎交互
- 我们希望我们的搜索服务器稳定
- 我们希望能够简单的将一台服务器扩展到上百台
这个时候,就引出了 elasticsearch。
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
关系数据搜索缺点:
- 无法打分,也就无法排序
- 无分布式
- 无法解析搜索请求
- 效率低
- 分词
elasticsearch实际上就是一个Nosql数据库,在update操作较少的情况下,可以代替mongodb使用。
windows环境下 elasticsearch安装
一、安装elasticsearch-rtf
1.elasticsearch是基于java开发的,所以首先要安装jdk
进入java官网 https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
下载相应的版本(一定要安装java8以上):

安装完之后,查看java的版本:
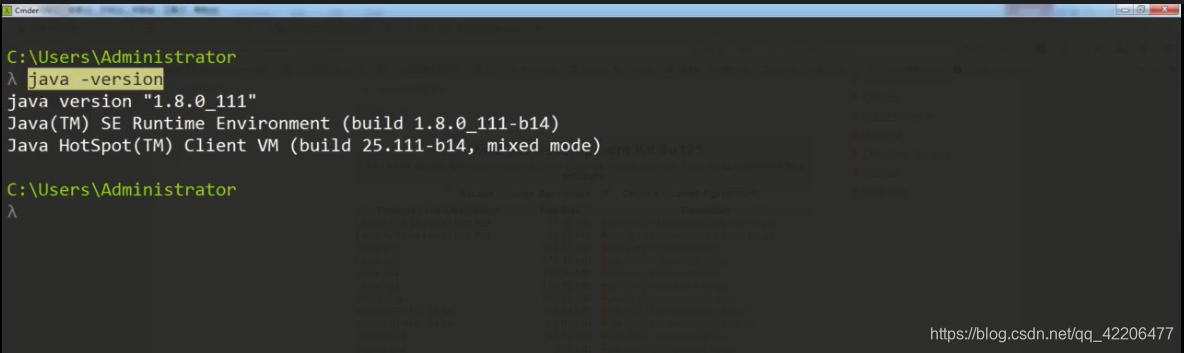
2.下载elasticsearch-rtf
elasticsearch-rtf是elasticsearch中文发行版,针对中文集成了相关插件,方便新手学习测试。
在github上下载elasticsearch-rtf https://github.com/medcl/elasticsearch-rtf
下载后解压,文件目录如下:
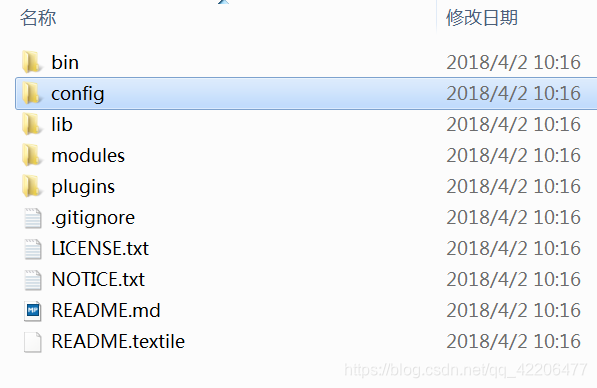
然后在elasticsearch-rtf-master\bin文件夹中 按住shift 右键打开命令窗口,运行命令:elasticsearch.bat
如果遇到“Could not find any executable java binary ……install java in your path or set JAVA_HOME”,可以参考这个解决方案 https://blog.csdn.net/javakklam/article/details/80070418

在浏览器中打开127.0.0.1:9200,如果出现以下信息,则说明elasticsearch安装完成
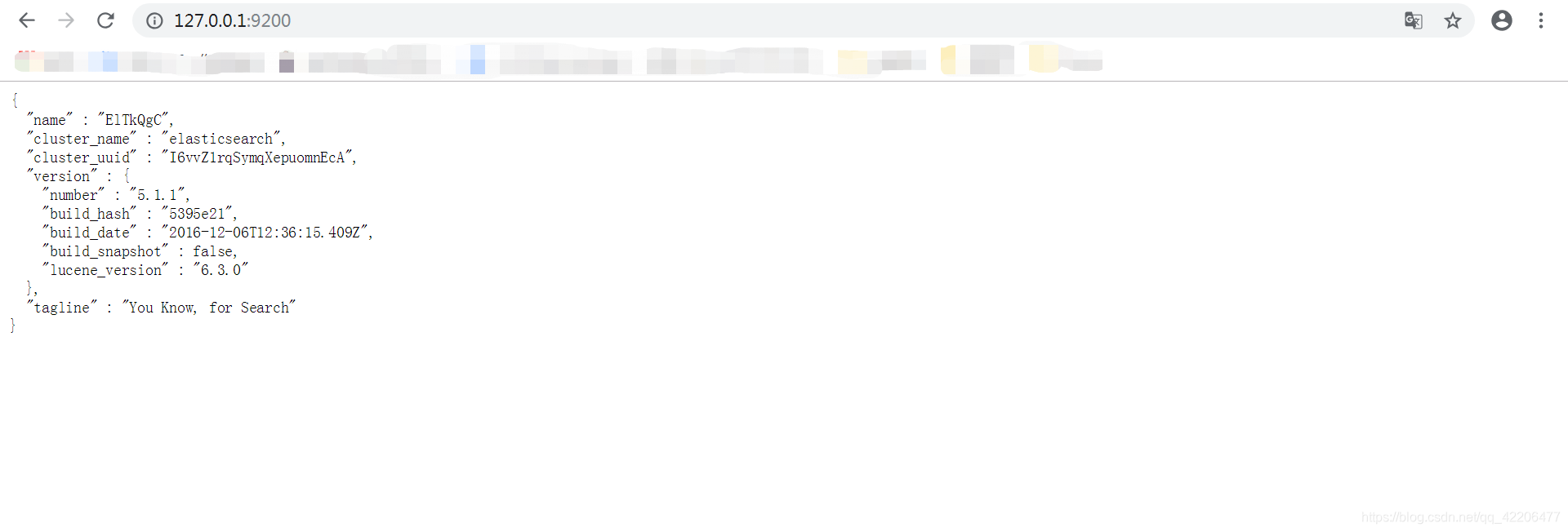
二、安装head插件
打开elasticsearch-head的github地址 https://github.com/mobz/elasticsearch-head
可以看到elasticsearch-head的安装步骤:
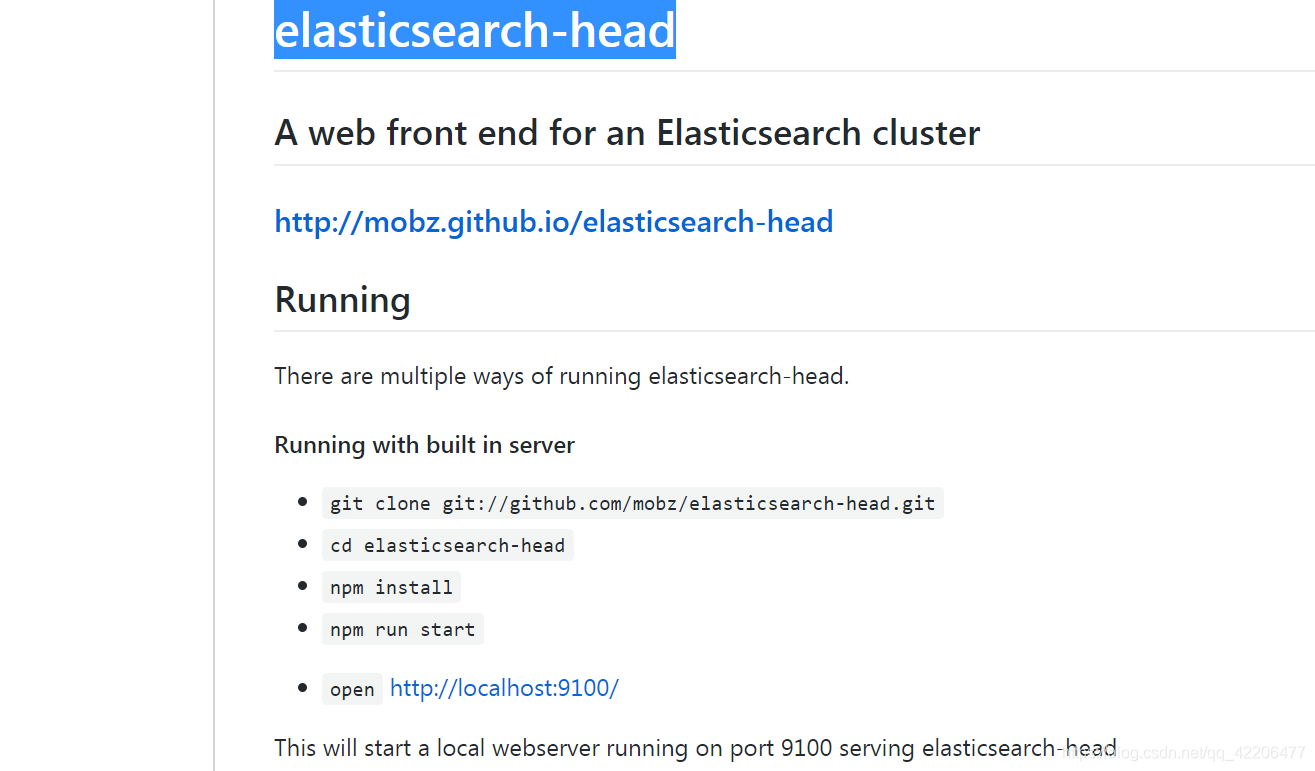
由于安装过程需要用到npm命令,所以我们要先安装node.js。
进入node.js官网 https://nodejs.org/en/,下载并安装。
由于npm十分慢,所以这里我们用cnpm(https://npm.taobao.org/)来代替npm,运行下面的命令就可以使用cnpm了:
npm install -g cnpm --registry=https://registry.npm.taobao.org
确保cnpm命令可以使用后,我们就可以开始安装elasticsearch-head了。
首先将elasticsearch-head-master下载或者clone下来。cd进入elasticsearch-head文件夹后,运行命令:
cnpm install
cnpm run start
打开http://127.0.0.1:9100/:
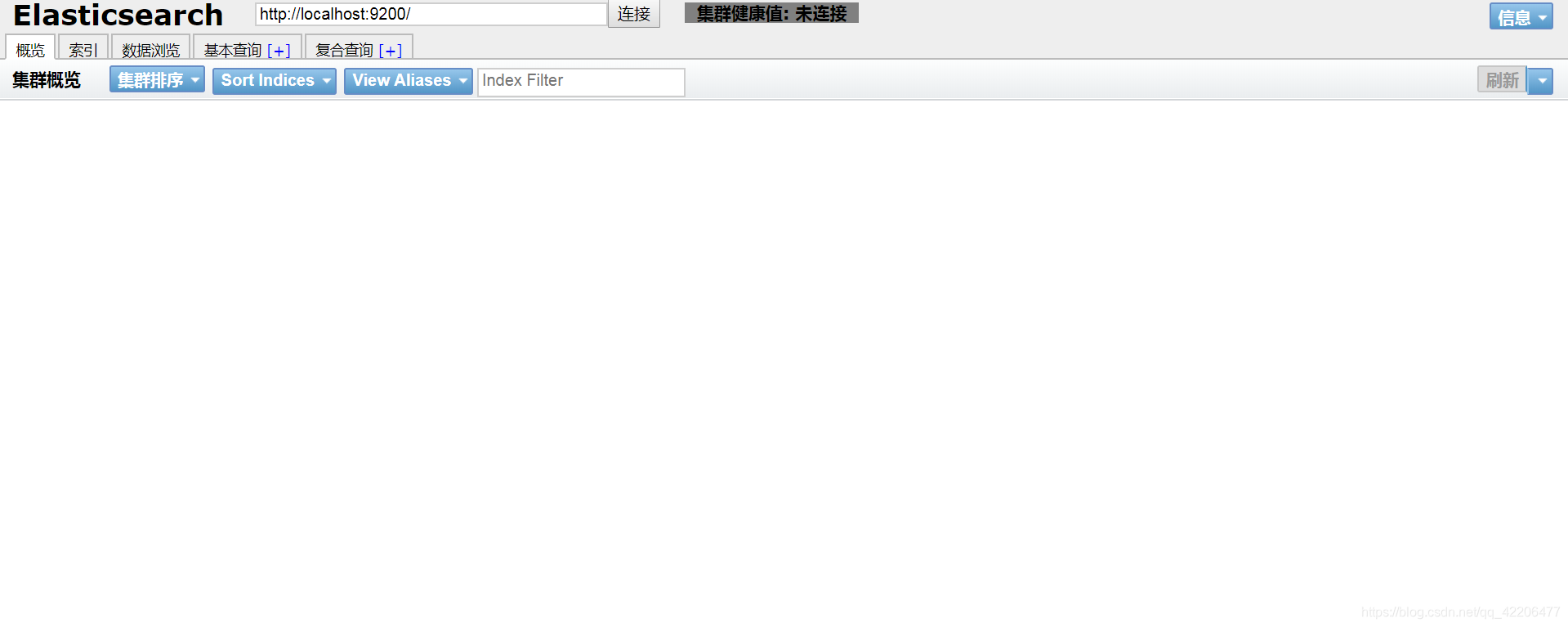
但是当前还是未连接状态,这是因为elasticsearch不允许第三方插件连接,所以我们要修改下elasticsearch的安全配置。
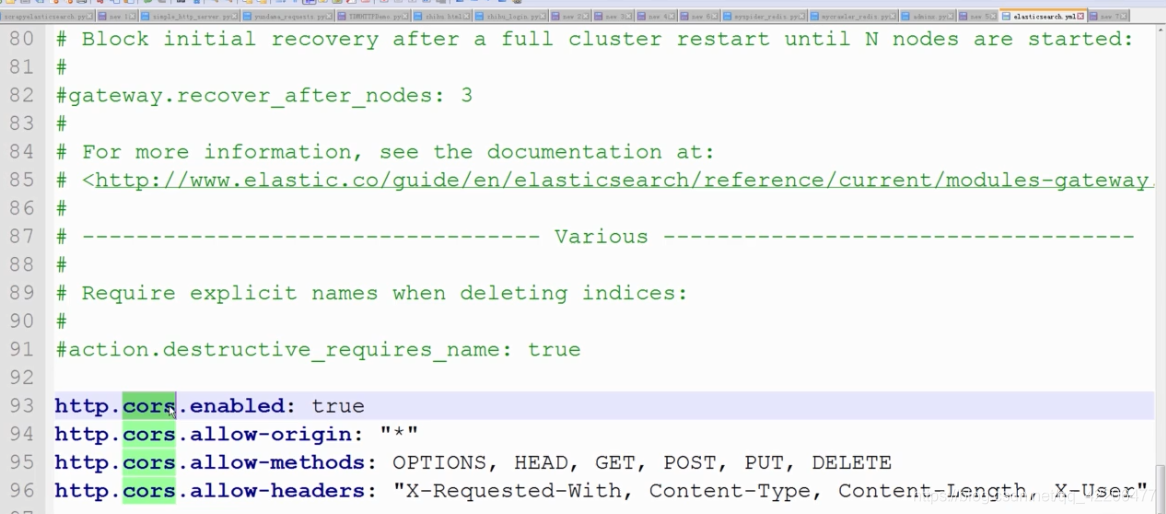
在elasticsearch.yml中添加以下配置代码:
http.cors.enabled:true
http.cors.allow-origin:"*"
http.cors.allow-methods:OPTIONS,HEAD,GET,POST,PUT,DELETE
http.cors.allow-headers:"X-Requested-With,Content-Type,Content-
Length,X-User"
然后重启elasticsearch.bat,再重新刷新下http://127.0.0.1:9100/,就可以成功连接了:

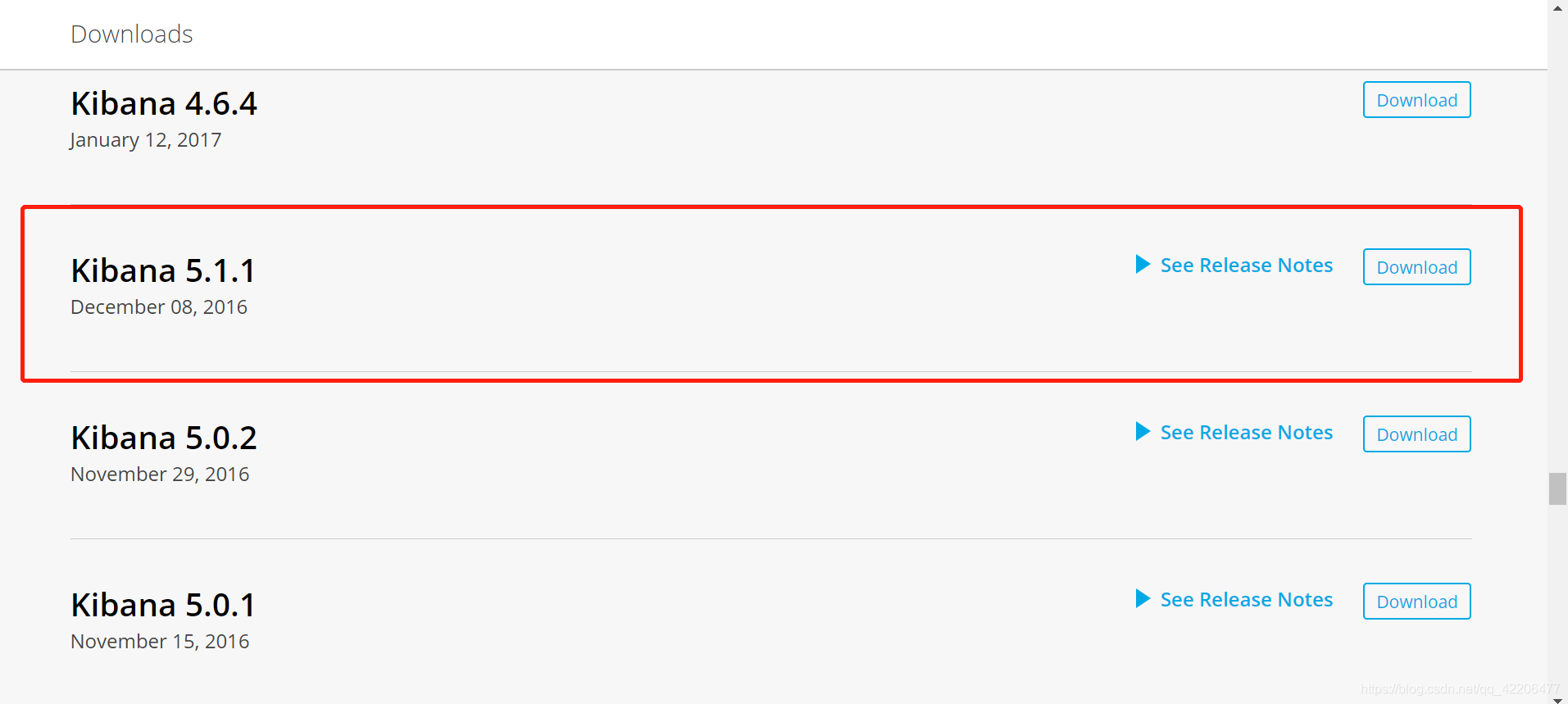
三、安装kibana
下载kibana,注意一定要下载5.1版本的(要与elasticsearch-head版本保持一致):
解压后,在bin文件夹中打开命令窗口,运行kibana
然后在5601端口运行:
elasticsearch基础概念
- 集群:一个或者多个节点组织在一起
- 节点:一个节点是一个集群中的一个服务器,由一个名字来标识,默认是一个随机的漫威角色的名字
- 分片:将索引划分为多份的能力,允许水平分割和扩展容量,多个分片响应请求,提高性能和吞吐量
- 副本:创建分片的一份或多份的能力,在一个节点失败,其余节点可以顶上
elasticsearch不是一个中间库,它是一个集合了数据保存与数据分析的服务,下表是 elasticsearch与mysql的一些概念类比: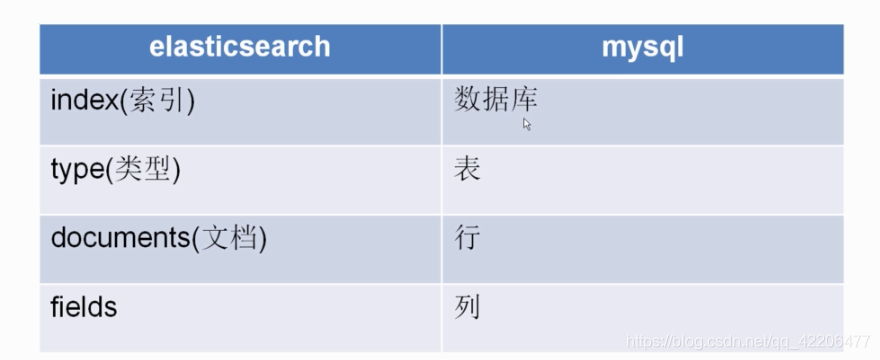
在elasticsearch中提到索引,可能有两种意思。第一种,是名词,指的就是数据库;第二种,是动词,指的是索引操作,也就是将数据做插入操作。
HTTP方法回顾:

倒排索引
目前搜索引擎中底层数据存储的方式都是倒排索引,倒排索引也是搜索引擎区别于其他数据库的关键。
倒排索引的概念:

在搜索引擎中每个文件都对应一个文件ID,文件内容被表示为一系列关键词的集合(实际上在搜索引擎索引库中,关键词也已经转换为关键词ID)。例如“文档1”经过分词,提取了20个关键词,每个关键词都会记录它在文档中的出现次数和出现位置。
既然有倒排索引,那么也是有正向索引的。当用户在主页上搜索关键词“华为手机”时,假设只存在正向索引(forward index),那么就需要扫描索引库中的所有文档,找出所有包含关键词“华为手机”的文档,再根据打分模型进行打分,排出名次后呈现给用户。因为互联网上收录在搜索引擎中的文档的数目是个天文数字,这样的索引结构根本无法满足实时返回排名结果的要求。
所以,搜索引擎会将正向索引重新构建为倒排索引,即把文件ID对应到关键词的映射转换为关键词到文件ID的映射,每个关键词都对应着一系列的文件,这些文件中都出现这个关键词。
(参考文章 https://www.cnblogs.com/zlslch/p/6440114.html)
倒排索引待解决的问题:

elasticsearch基本的索引和文档CRUD操作
创建索引
#lagou索引初始化操作,指定分片和副本数量
#shards一旦设置就不能修改
PUT lagou
{
"settings": {
"index":{
"number_of_shards":5,
"number_of_replicas":1
}
}
}
获取索引settings
GET lagou/_settings #获取lagou settings
GET _all/_settings #获取所有的 settings
GET .kibana,lagou/_settings #获取kibana、lagou的settings
GET _settings #等同于GET _all/_settings
更新settings
PUT lagou/_settings
{
"number_of_replicas":1
}
获取索引信息
GET _all #获取所有索引的信息
GET lagou #获取lagou的信息
保存文档
#指定id
PUT lagou/job/1
{
"title":"python分布式爬虫",
"salary_min":15000,
"city":"北京",
"company":{
"name":"百度",
"company_addr":"北京市软件园"
},
"publish_date":"2018-9-8",
"comments":15
}
#不指定id
POST lagou/job/
{
"title":"python开发",
"salary_min":15000,
"city":"上海",
"company":{
"name":"美团",
"company_addr":"上海市软件园"
},
"publish_date":"2018-9-8",
"comments":15
}
执行后,就可以在head中查看数据了

获取文档
GET lagou/job/1
GET lagou/job/1?_source=title,city #获取指定字段的source
修改文档
#方式一 覆盖的方式修改
PUT lagou/job/1
{
"title":"python分布式爬虫",
"salary_min":15000,
"company":{
"name":"百度",
"company_addr":"北京市软件园"
},
"publish_date":"2018-9-8",
"comments":15
}
#方式二,增量修改,指定修改的字段,推荐这种方式
POST lagou/job/1/_update
{
"doc": {
"comments":20
}
}
删除
DELETE lagou/job/1 #删除文档
DELETE lagou #删除index
elasticsearch的mget和bulk批量操作
建立一个testdb索引:
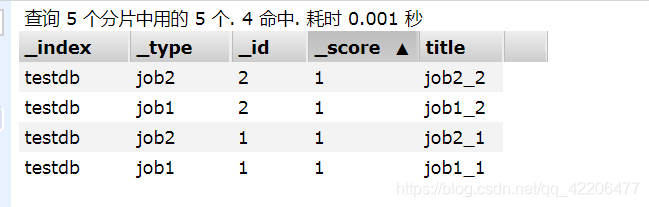
一、mget查询多条数据:
#查询type分别为job1、job2,id为1、2的数据
GET _mget
{
"docs":[
{
"_index":"testdb",
"_type":"job1",
"_id":1
},
{
"_index":"testdb",
"_type":"job2",
"_id":2
}
]
}
#index相同的查询
GET testdb/_mget
{
"docs":[
{
"_type":"job1",
"_id":1
},
{
"_type":"job2",
"_id":2
}
]
}
#index与type都相同的查询
GET testdb/job1/_mget
{
"docs":[
{
"_id":1
},
{
"_id":2
}
]
}
#index与type都相同的查询---简写方式
GET testdb/job1/_mget
{
"ids":[1,2]
}
二、bulk批量操作:

bulk操作的代码只能写成一行,不能做美化。
#bulk批量插入数据
POST _bulk
{"index":{"_index":"lagou","_type":"job","_id":"1"}}
{"title":"python开发","salary_min":15000,"city":"上海","company":{"name":"美团","company_addr":"上海市软件园"},"publish_date":"2018-9-8","comments":15}
{"index":{"_index":"lagou","_type":"job2","_id":"2"}}
{"title":"python开","salary_min":15000,"city":"上海","company":{"name":"团","company_addr":"上市软件园"},"publish_date":"2018-9-8","comments":15}
bulk其他操作格式

elasticsearch的mapping映射管理
映射是指创建索引的时候,可以预先定义字段的类型以及相关属性
elasticsearch会根据JSON源数据的基础类型猜测你想要的字段映射,将输入的数据转变成可搜索的索引项。Mapping就是我们自己定义的字段的数据类型,同时告诉elasticsearch如何索引数据以及是否可以被搜索。
作用:会让索引建立的更加细致和完善
es里的内置类型:
- string类型:text,keyword (设置为text类型,会做分词处理)
- 数字类型:long,interger,short,byte,double,float
- 日期类型:date
- bool类型:boolean
- binary类型:object,nested
- 复杂类型:object,nested
- geo类型:geo-point,geo-shape
- 专业类型:ip,competion
内置类型的常见属性:

举个栗子:
#创建mapping,并插入数据
PUT lagou
{
"mappings": {
"job":{
"properties": {
"title":{
"type":"text"
},
"salary_min":{
"type":"keyword"
},
"city":{
"type":"keyword"
},
"company":{
"properties": {
"name":{
"type":"text"
},
"company_addr":{
"type":"text"
},
"employee_count":{
"type":"integer"
}
}
},
"publish_date":{
"type":"date",
"format": "yyyy-MM-dd"
},
"comments":{
"type":"integer"
}
}
}
}
}
PUT lagou/job/2
{
"title":"python开发",
"salary_min":10000,
"city":"夜上海",
"company":{
"name":"夜美团",
"company_addr":"夜上海市软件园",
"employee_count":50
},
"publish_date":"2018-9-8",
"comments":15
}
#获取mapping
GET lagou/_mapping/job
#获取集群里所有的mapping
GET _all/_mapping
数据插入成功:

这里需要提醒一点,索引一旦创建了类型,就不能修改了。只能重建索引再导入数据。
elasticsearch的简单查询

首先插入一些数据,为查询做准备:
PUT lagou
{
"mappings": {
"job":{
"properties": {
"title":{
"store": true,
"type":"text", #text类型,会做分词处理
"analyzer": "ik_max_word"
},
"company_name":{
"store": true,
"type": "keyword"
},
"desc":{
"type": "text" #text类型,会做分词处理
},
"comments":{
"type":"integer"
},
"add_time":{
"type":"date",
"format": "yyyy-MM-dd"
}
}
}
}
}
POST lagou/job/
{
"title":"python开发",
"company_name":"美团",
"desc":"shuxi熟悉jichuzhishi基础知识",
"comments":15,
"publish_date":"2018-9-8"
}
POST lagou/job/
{
"title":"python分布式爬虫",
"company_name":"baidu百度",
"desc":"熟悉jichuzhishi基础知识",
"comments":15,
"publish_date":"2018-9-8"
}
1.match查询,会对关键词做分词(但是字段类型要是text)
GET lagou/job/_search
{
"query": {
"match": {
"title": "python" #指明要查询的关键词
}
}
}
2.term查询,不会对关键词做任何处理
GET lagou/job/_search
{
"query": {
"term": {
"title": "Python"
}
}
}
3.terms查询
GET lagou/job/_search
{
"query": {
"terms": {
"title": ["python","系统","工程师"] #符合列表中任意一个元素,就能查询结果
}
}
}
4.控制返回数量:
GET lagou/_search
{
"query": {
"match": {
"title": "python"
}
},
"from": 1,
"size": 2
}
5.返回所有数据
GET lagou/job/_search
{
"query": {
"match_all": {}
}
}
6.短语查询
GET lagou/_search
{
"query": {
"match_phrase": {
"title": {
"query": "python系统",
"slop":3 #限制词之间的距离
}
}
}
}
7.multi_match查询
#可以指定多个字段
#查询title和desc这两个字段里面包含python的关键词文档
GET lagou/_search
{
"query": {
"multi_match": {
"query": "python",
"fields":["title^3","desc"] #^3是权重
}
}
}
8.返回指定字段
GET lagou/_search
{
"stored_fields": ["title","company_name"],
"query": {
"match": {
"title": "python"
}
}
}
9.通过sort把结果排序
GET lagou/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"comments": {
"order": "desc"
} #需要排序的字段
}
]
}
10.range查询
GET lagou/_search
{
"query": {
"range": {
"comments": {
"gte": 10, #大于等于
"lte": 20, #小于等于
"boost": 2.0 #权重
}
}
}
}
#时间范围查询
GET lagou/_search
{
"query": {
"range": {
"add_time": {
"gte": "2018-05-01",
"lte": "now"
}
}
}
}
11.wildcard 模糊查询
GET lagou/_search
{
"query":{
"wildcard":
{"title":{"value":"pyth*n","boost":2.0}}
}
}
elasticsearch的bool组合查询
老版本的filtered已经被bool替换,用bool包括must should must_not filter来完成,格式如下:
bool:{
"filter":[], #字段的过滤 不参与打分
"must":[], #数组里的查询都必须满足
"should":[], #数组里只要满足一个或多个
"must_not":[], #数组里一个都不能满足
}
现在我们来举个栗子说明下:
首先建立测试数据,利用bulk批量建立
POST lagou/testjob/_bulk
{"index":{"_id":1}}
{"salary":10,"title":"Python"}
{"index":{"_id":2}}
{"salary":20,"title":"Scrapy"}
{"index":{"_id":3}}
{"salary":30,"title":"Django"}
{"index":{"_id":4}}
{"salary":30,"title":"Elasticsearch"}
有了数据之后,我们就可以来演示bool查询了:
1.最简单的filter查询
#等同于 select * from testjob where salary=20
#filtered 薪资为20k的工作
GET lagou/testjob/_search
{
"query": {
"bool": {
"must": {
"match_all":{}
},
"filter": {
"term": {
"salary": 20
}
}
}
}
}
#也可以指定多个值
#filtered 薪资为10k或20k的工作
GET lagou/testjob/_search
{
"query": {
"bool": {
"must": {
"match_all":{}
},
"filter": {
"terms": {
"salary": [10,20]
}
}
}
}
}
2.查看分析器解析的结果
GET /_analyze
{
"analyzer": "ik_max_word",
"text": "python网络"
}
##########分析器解析结果###########
{
"tokens": [
{
"token": "python",
"start_offset": 0,
"end_offset": 6,
"type": "ENGLISH",
"position": 0
},
{
"token": "网络",
"start_offset": 6,
"end_offset": 8,
"type": "CN_WORD",
"position": 1
},
{
"token": "络",
"start_offset": 7,
"end_offset": 8,
"type": "CN_WORD",
"position": 2
}
]
}
3.复杂的组合查询
#select * from testjob where (salary=20 OR title=Python) AND (salary != 30)
#查询薪资等于20k或者工作python的工作,排除价格为30k的
GET lagou/testjob/_search
{
"query": {
"bool": {
"should":[
{"term":{"salary":20}},
{"term":{"title":"python"}}
],
"must_not":{
"term":{"salary":30}
}
}
}
}
4.嵌套查询
#相当于 select * from testjob where title="python" or (title="elasticsearch" AND salary=30)
GET lagou/testjob/_search
{
"query": {
"bool": {
"should":[
{"term":{"title":"python"}},
{"bool":{
"must":[
{"term":{"title":"elasticsearch"}},
{"term":{"salary":30}}
]
}}
]
}
}
}
5.处理null空值方法
#相当于 select salary from testjob where salary is not NULL
GET lagou/testjob/_search
{
"query": {
"bool": {
"filter": {
"exists": {
"field": "salary"
}
}
}
}
}
#对上面的操作取反
GET lagou/testjob/_search
{
"query": {
"bool": {
"must_not": {
"exists": {
"field": "salary"
}
}
}
}
}
scrapy写入数据到elasticsearch
首先需要安装elasticsearch-dsl:
pip install elasticsearch-dsl
新建es_types文件,用来写数据类型
#es_types.py
from datetime import datetime
from elasticsearch_dsl import DocType, Date, Nested, Boolean, \
analyzer, InnerObjectWrapper, Completion, Keyword, Text,Integer
from elasticsearch_dsl.connections import connections
connections.create_connection(hosts=["localhost"])
class JobType(DocType):
#拉勾数据类型
url = Keyword()
url_object_id = Keyword()
title = Text(analyzer="ik_max_word")
salary = Keyword()
job_city = Keyword()
work_years_min = Integer()
work_years_max = Integer()
degree_need = Text(analyzer="ik_max_word")
job_type = Text(analyzer="ik_max_word")
pulish_time = Date()
tags = Text(analyzer="ik_max_word")
job_advantage = Text(analyzer="ik_max_word")
job_desc = Text(analyzer="ik_max_word")
job_addr = Keyword()
company_url = Keyword()
company_name = Text(analyzer="ik_max_word")
class Meta:
index = "lagou" #索引index
doc_type = "job" #type
timeout = 30 #设置超时时间
if __name__ == "__main__":
JobType.init()
运行后,出现了以下的报错信息:

这是由于版本错误造成的,解决方案可以参考文章:
https://blog.csdn.net/weixin_39492016/article/details/82771438
运行成功后,在elasticsearch-head中查看mappings信息:
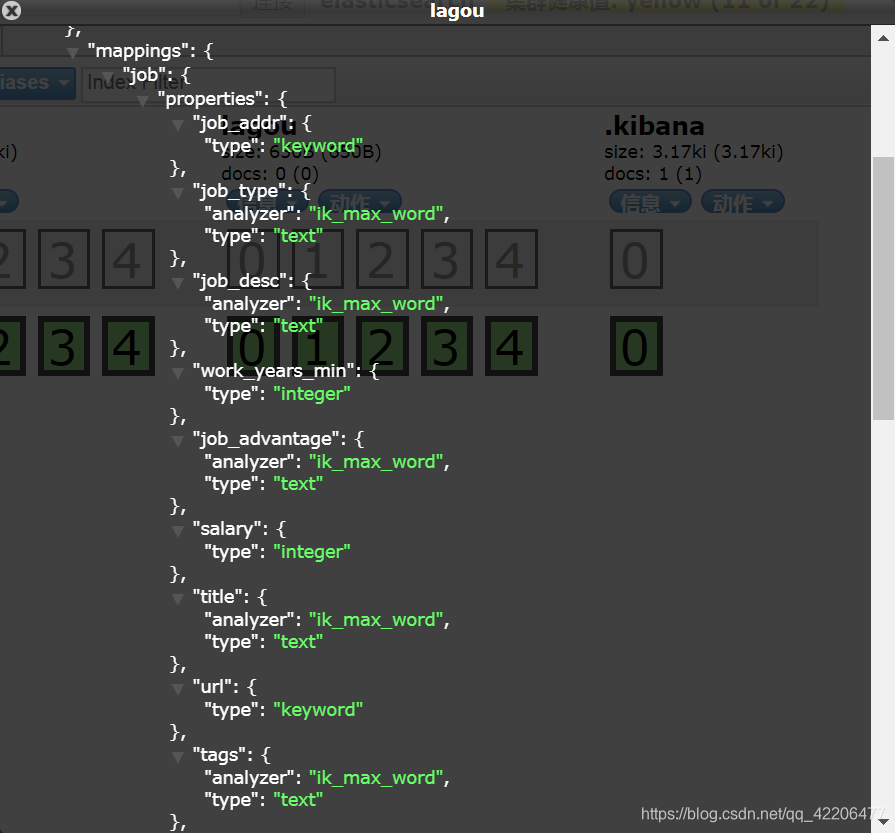
在Item添加save_to_es方法:
class LagouItem(scrapy.Item):
#省略部分代码
def save_to_es(self):
#将item转换成es的数据
job = JobType()
job.title = self['title']
job.url = self['url']
job.url_object_id = self['url_object_id']
job.title = self['title']
job.salary = self['salary']
job.job_city = self['job_city']
job.work_years_min = self['work_years_min']
job.work_years_max = self['work_years_max']
job.degree_need = self['degree_need']
job.job_type = self['job_type']
job.pulish_time = self['pulish_time']
job.tags = self['tags']
job.job_advantage = self['job_advantage']
job.job_desc = self['job_desc']
job.job_addr = self['job_addr']
job.company_url = self['company_url']
job.company_name = self['company_name']
job.save()
return
在pipeline中添加ElasticsearchPipeline,用于将数据写入es
class ElasticsearchPipeline(object):
#将数据写入es中
def process_item(self,item,spider):
#将item转换成es的数据
item.save_to_es()
return item
Debug以下,确保数据能保存到es中
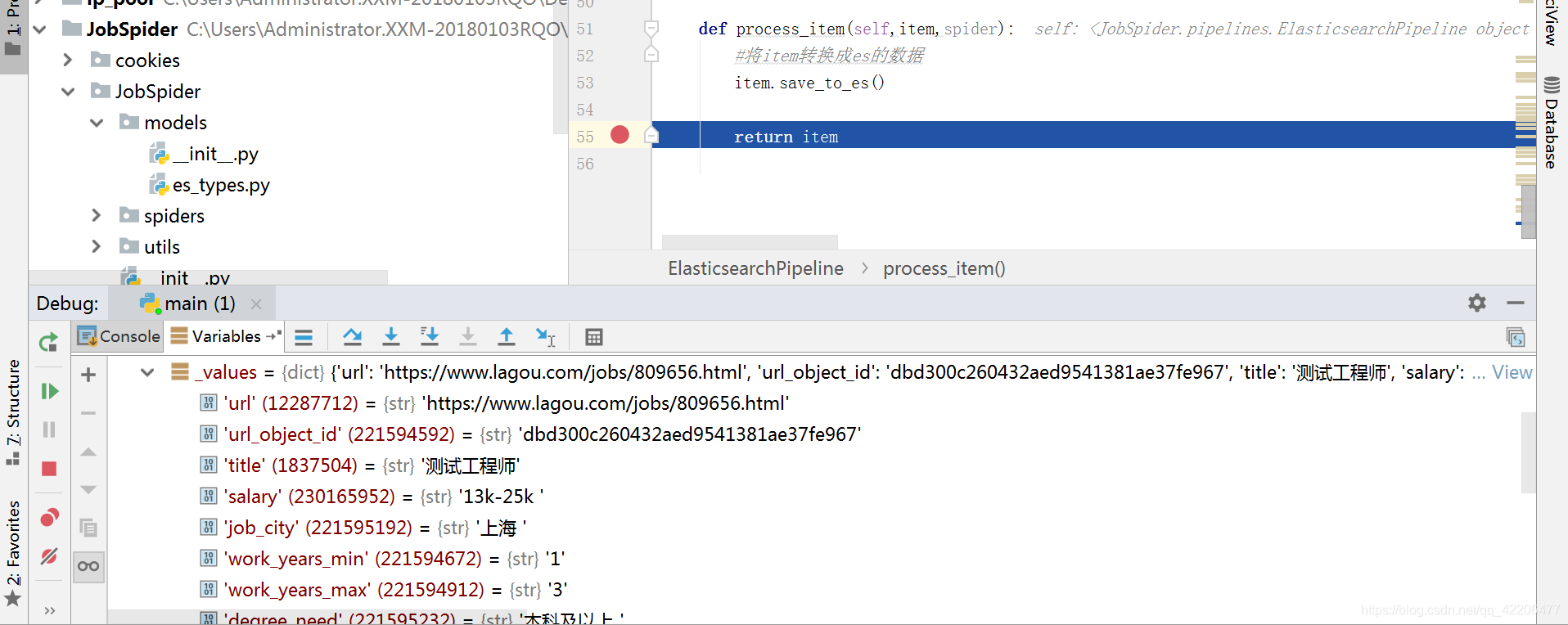
在elasticsearch-head中可以看到,成功写入两条数据:
