使用elasticsearch建立搜索引擎
elasticsearch官方网址:https://www.elastic.co/products/elasticsearch
1、选择Elasticsearch的原因
(1)Elasticsearch是一个建立在全文搜索引擎 Apache Lucene™ 基础上的开源的实时分布式搜索和分析引擎,功能强大:
- 支持全文搜索;
- 分布式实时文件存储,并将每一个字段都编入索引,使其可以被搜索;
- 实时分析的分布式搜索引擎;
- 可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据。
所有的这些功能被集成到一个服务里面,你的应用可以通过简单的RESTful API、各种语言的客户端甚至命令行与之交互。
(2)简单易学,文档齐全
搜索引擎选择: Elasticsearch与Solr:http://www.cnblogs.com/chowmin/articles/4629220.html
2、安装并配置Elasticsearch
因为我们要使用ansj分词工具进行分词,最新的ansj与elasticsearch结合的工具包对应的elastic search的版本是5.0.1,所以我们下载5.0.1版本的elasticsearch。
(1)下载并解压
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-5.0.1.tar.gz
sha1sum elasticsearch-5.0.1.tar.gz
tar -xzf elasticsearch-5.0.1.tar.gz
cd elasticsearch-5.0.1/
(2)启动ES
./bin/elasticsearch
16-12-11T17:28:33,912][INFO ][o.e.n.Node ] [rpA7Jx3] started
看到类似这一句的,则说明启动ES了
新开一个终端,查看是否运行成功
curl -XGET 'localhost:9200/?pretty'
出现如上形式内容,则说明ES运行成功。
可以按Ctrl-C关闭ES
3、安装并配置ansj分词器
进入es目录执行如下命令
./bin/elasticsearch-plugin install http://maven.nlpcn.org/org/ansj/elasticsearch-analysis-ansj/5.0.1.0/elasticsearch-analysis-ansj-5.0.1.0-release.zip
4、elasticsearch启动出现的错误解决
(1)Java HotSpot™ 64-Bit Server VM warning: INFO:
os::commit_memory(0x0000000085330000, 2060255232, 0) failed; error=‘Cannot allocate memory’ (errno=12)
由于elasticsearch5.0默认分配jvm空间大小为2g,修改jvm空间分配
# vim config/jvm.options
-Xms2g
-Xmx2g
修改为
-Xms512m
-Xmx512m
(2)max number of threads [1024] for user [elasticsearch] is too low, increase to at least [2048]
修改 /etc/security/limits.d/90-nproc.conf
原: soft nproc 1024
改为: soft nproc 2048
(3)max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
修改/etc/sysctl.conf配置文件,
cat /etc/sysctl.conf | grep vm.max_map_count
vm.max_map_count=262144
如果不存在则添加
echo "vm.max_map_count=262144" >>/etc/sysctl.conf
(4)max file descriptors [65535] for elasticsearch process likely too low, increase to at least [65536]
ulimit -n 65536
(5)[root@localhost elasticsearch-5.0.1]# ./bin/elasticsearch
[WARN ][o.e.b.ElasticsearchUncaughtExceptionHandler] [] uncaught exception in thread [main]
org.elasticsearch.bootstrap.StartupException: java.lang.RuntimeException: can not run elasticsearch as root
注意:ES不能用root管理员身份启动
5、配置elasticsearch Java API
在pom.xml添加如下依赖:
<!-- elasticsearch Java API -->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>transport</artifactId>
<version>5.0.1</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>2.8.0</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.8.0</version>
</dependency>
6、elasticsearch教程
- 官方教程:https://www.elastic.co/guide/en/elasticsearch/reference/current/zip-targz.html
- Elasticsearch基础教程:http://blog.csdn.net/cnweike/article/details/33736429
- Elasticsearch JAVA API教程:http://www.07net01.com/2016/07/1603264.html
1. Java API批量导出
Settings settings = ImmutableSettings.settingsBuilder().put("cluster.name", "elasticsearch-bigdata").build();
Client client = new TransportClient(settings)
.addTransportAddress(new InetSocketTransportAddress("10.58.71.6", 9300));
SearchResponse response = client.prepareSearch("bigdata").setTypes("student")
.setQuery(QueryBuilders.matchAllQuery()).setSize(10000).setScroll(new TimeValue(6000 00))
.setSearchType(SearchType.SCAN).execute().actionGet();//setSearchType(SearchType.Scan) 告诉ES不需要排序只要结果返回即可 setScroll(new TimeValue(600000)) 设置滚动的时间
String scrollid = response.getScrollId();
try {
//把导出的结果以JSON的格式写到文件里
BufferedWriter out = new BufferedWriter(new FileWriter("es", true));
//每次返回数据10000条。一直循环查询直到所有的数据都查询出来
while (true) {
SearchResponse response2 = client.prepareSearchScroll(scrollid).setScroll(new TimeValue(1000000))
.execute().actionGet();
SearchHits searchHit = response2.getHits();
//再次查询不到数据时跳出循环
if (searchHit.getHits().length == 0) {
break;
}
System.out.println("查询数量 :" + searchHit.getHits().length);
for (int i = 0; i < searchHit.getHits().length; i++) {
String json = searchHit.getHits()[i].getSourceAsString();
out.write(json);
out.write("\r\n");
}
}
System.out.println("查询结束");
out.close();
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
2. Java API 批量导入
Settings settings = ImmutableSettings.settingsBuilder().put("cluster.name", "elasticsearch-bigdata").build();
Client client = new TransportClient(settings)
.addTransportAddress(new InetSocketTransportAddress("10.58.71.6", 9300));
try {
//读取刚才导出的ES数据
BufferedReader br = new BufferedReader(new FileReader("es"));
String json = null;
int count = 0;
//开启批量插入
BulkRequestBuilder bulkRequest = client.prepareBulk();
while ((json = br.readLine()) != null) {
bulkRequest.add(client.prepareIndex("bigdata", "student").setSource(json));
//每一千条提交一次
if (count% 1000==0) {
bulkRequest.execute().actionGet();
System.out.println("提交了:" + count);
}
count++;
}
bulkRequest.execute().actionGet();
System.out.println("插入完毕");
br.close();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
elasticsearch导入数据的两种方法
第一种方法:手动导入
1、cat test.json
{"index":{"_index":"stuff_orders","_type":"order_list","_id":903713}}
{"real_name":"刘备","user_id":48430,"address_province":"上海","address_city":"浦东新区","address_district":null,"address_street":"上海市浦东新区广兰路1弄2号345室","price":30.0,"carriage":6.0,"state":"canceled","created_at":"2013-10-24T09:09:28.000Z","payed_at":null,"goods":["营养早餐:火腿麦满分"],"position":[121.53,31.22],"weight":70.0,"height":172.0,"sex_type":"female","birthday":"1988-01-01"}
2、导入elasticsearch
[root@ELKServer opt]# curl -XPOST ‘localhost:9200/stuff_orders/_bulk?pretty‘ --data-binary @test.json
{
"took" : 600,
"errors" : false,
"items" : [ {
"index" : {
"_index" : "stuff_orders",
"_type" : "order_list",
"_id" : "903713",
"_version" : 1,
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"status" : 201
}
} ]
}
3、查看elasticsearch是否存在数据
[root@ELKServer opt]# curl localhost:9200/stuff_orders/order_list/903713?pretty
{
"_index" : "stuff_orders",
"_type" : "order_list",
"_id" : "903713",
"_version" : 1,
"found" : true,
"_source" : {
"real_name" : "刘备",
"user_id" : 48430,
"address_province" : "上海",
"address_city" : "浦东新区",
"address_district" : null,
"address_street" : "上海市浦东新区广兰路1弄2号345室",
"price" : 30.0,
"carriage" : 6.0,
"state" : "canceled",
"created_at" : "2013-10-24T09:09:28.000Z",
"payed_at" : null,
"goods" : [ "营养早餐:火腿麦满分" ],
"position" : [ 121.53, 31.22 ],
"weight" : 70.0,
"height" : 172.0,
"sex_type" : "female",
"birthday" : "1988-01-01"
}
}
第二种方法:从数据库中导入
1、下载安装插件elasticsearch-jdbc-2.3.4.0
wget http://xbib.org/repository/org/xbib/elasticsearch/importer/elasticsearch-jdbc/2.3.4.0/elasticsearch-jdbc-2.3.4.0-dist.zip
# elasticsearch-jdbc-2.3.4.0-dist.zip的版本要和你安装的elasticsearch对应。
unzip elasticsearch-jdbc-2.3.4.0-dist.zip
mv elasticsearch-jdbc-2.3.4.0 /usr/local/
cd /usr/local/elasticsearch-jdbc-2.3.4.0/
2、配置脚本
vim import.sh
#!/bin/sh
JDBC_IMPORTER_HOME=/usr/local/elasticsearch-jdbc-2.3.4.0
bin=$JDBC_IMPORTER_HOME/bin
lib=$JDBC_IMPORTER_HOME/lib
echo ‘{
"type" : "jdbc",
"jdbc": {
"elasticsearch.autodiscover":true,
"elasticsearch.cluster":"my-application", #簇名 详见:/usr/local/elasticsearch/config/elasticsearch.yml
"url":"jdbc:mysql://localhost:3306/test", #mysql数据库地址
"user":"test", #mysql用户名
"password":"1234", #mysql密码
"sql":"select *,id as _id from workers_info",
"elasticsearch" : {
"host" : "192.168.10.49",
"port" : 9300
},
"index" : "myindex", #新的index
"type" : "mytype" #新的type
}
}‘| java -cp "${lib}/*" -Dlog4j.configurationFile=${bin}/log4j2.xml org.xbib.tools.Runner org.xbib.tools.JDBCImporter
chmod + import.sh
sh import.sh
3、查看数据是否导入elasticsearch
[root@ELKServer bin]# curl -XGET ‘http://localhost:9200/myindex/mytype/_search?pretty‘
{
"took" : 15,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"failed" : 0
},
"hits" : {
"total" : 1,
"max_score" : 1.0,
"hits" : [ {
"_index" : "myindex",
"_type" : "mytype",
"_id" : "AVZyXCReGHjmX33dpJi3",
"_score" : 1.0,
"_source" : {
"id" : 1,
"workername" : "xing",
"salary" : 10000,
"tel" : "1598232123",
"mailbox" : "[email protected]",
"department" : "yanfa",
"sex" : "F",
"qq" : 736019646,
"EmployedDates" : "2012-12-21T00:00:00.000+08:00"
}
} ]
}
}
实战代码
古诗文搜索引擎实战github地址:https://github.com/AngelaFighting/gushiwensearch
1、启动ES
Windows系统,在ES目录的bin目录中打开命令行窗口,输入命令:·elasticsearch.bat·,回车,如果看到ES集群显示started并且状态为Green,则说明启动成功
2、使用浏览器打开首页
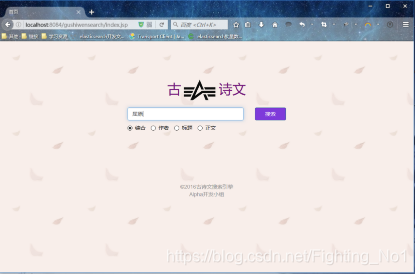
输入要查询的内容,并选择搜索范围,点击搜索按钮
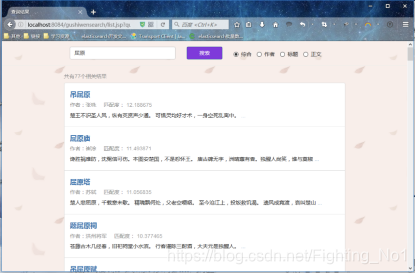
可看到匹配的结果数和各个结果的部分信息。
点击某篇诗文的链接,就可以查看诗文的详细信息了。