es基本概念:
- 索引(Index)
es是把数据存放到一个或者多个索引中 - 文档 (document)
用来存储数据实体,类似关系型数据库的row,文档的三元素:1._index:文档对应的索引;2._type:文档对应的数据类型;3._ID:文档的唯一ID - 类型(type)
每个文档在es中都必须设定它的类型。文档类型使得同一个索引中在存储结构不同文档时,只需根据文档类型就可以找到对应的参数映射信息,方便文档的存取。类似于关系型数据库的table - 节点(node)
部署es程序的服务器,运行的ES实例 - 集群(cluster)
多个节点组成的集群,这些节点在同一个网络内,cluster-name相同 - 分片(shard)\从分片(replica )
分片分为 主分片(primary shard) 以及 从分片(replica shard)
主分片与从分片关系:从分片只是主分片的一个副本,它用于提供数据的冗余副本
从分片应用:在硬件故障时提供数据保护,同时服务于搜索和检索这种只读请求
是否可变:索引中的主分片的数量在索引创建后就固定下来了,但是从分片的数量可以随时改变
索引默认创建的分片:默认设置5个主分片和一组从分片(即每个主分片有一个从分片对应),但是从分片没有被启用 (主从分片在同一个节点上没有意义),因此集群健康值显示为黄色(yellow)
特点:
- 高频使用
- 及时响应
- 全文检索
- 多条件组合查询
核心理念:
- 开箱即用
- 天生集群
- 自动容错
- 扩展性强
restful风格请求方式:
-
GET(数据查询)
GET /索引名称/_search GET /_search 空查询,查询所有索引,并且分页 -
POST(数据查询、数据新增、数据修改)
-
PUT(数据新增、数据修改、索引配置)
语法:(在settings中可以设置当前索引的分片数和从分片数(副本数)). PUT /索引名称/类型名称/文档ID { “name”:"value", ... } -
DELETE(数据删除)
DELETE /索引名称/类型名称/文档ID
ps: POST和PUT在修改时的区别,PUT是新数据替换旧数据,POST更新相同字段的值,POST在不指定id修改的时候,系统会生成一个id,若在POST请求的修改语句上遗漏了id,系统就会生成一条垃圾数据,所以修改尽量用PUT请求。
索引类型
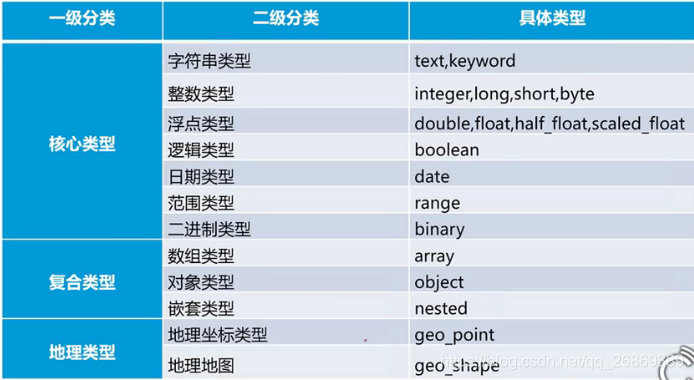
分词器类型
- 标准分词器(默认分词策略)
- 简单分词器
- 空格分词器
- 语音分词器
- 自定义分词器(以上四种不支持中文,需自定义分词器,如IK分词器)
kibana中操作
多条件查询
-
精准查询(过滤查询)
以下子句包含在bool中使用 must 文档 必须 匹配这些条件才能被包含进来。 must_not 文档 必须不 匹配这些条件才能被包含进来。 should 如果满足这些语句中的任意语句,将增加 _score ,否则,无任何影响。它们主要用于修正每个文档的相关性得分。 es会对filter过滤的数据进行缓存,提高查询效率 GET /hous_01/user/_search { "query": { "bool": { "filter": { "term": { "age": 30 } } } } } -
匹配度查询
match子句查询 GET /hous_01/user/_search { "query": { "match": { "username": "database" } } } -
范围查询
GET /hous_01/user/_search { "query": { "range": { "age": { "gte": 30, "lte": 50 } } } }
索引配置:
在settings中可以设置当前索引的分片数和从分片数(副本数)
mappings是对索引库中索引的字段名称及其数据类型进行定义,es中有自动映射机制,字符串映射为string,数字映射为long
properties用来创建一个属性,type则为该属性声明类型
PUT hous_01
{
"settings": {
"number_of_shards": 5,
"number_of_replicas": 1
},
"mappings": {
"user":{
"properties": {
"id":{
"type": "integer"
},
"username":{
"type": "text",
"analyzer": "standard"
},
"age":{
"type": "integer"
}
}
}
}
}
查询结果属性意义:
{
"took": 0, 查询执行时间,单位毫秒
"timed_out": false, 是否超时
"_shards": {
"total": 5, 参与此次查询的分片数
"successful": 5, 参与此次查询的成功数
"failed": 0 参与此次查询的失败数
},
"hits": { 查询出来的结果集,数据为json
"total": 1, 代表一个结果
"max_score": 1, 分数是1,表示满分
"hits": [ 结果展示,文档内容
{
"_index": "hous_01", 索引名称
"_type": "user", 类型名称
"_id": "1", 文档id
"_score": 1,
"_source": {
"id": 1,
"username": "hous",
"age": 30
}
}
]
}
}