文章目录

特别说明
●在本篇博客中将使用三种方法实现 Kaggle 数据集——Dogs vs .Cats 进行迁移学习完成图像分类操作
●TensorFlow 1.x 实现使用的 TensorFlow 1.15.2版本,TensorFlow 2.x 低阶 API 由于本地笔记本带不动所以使用的 Google Colab 集成开发环境,TensorFlow 2.x 高阶 API Keras使用的本地安装的 TensorFlow 2.0 版本
●部分函数将不做解析,前面博客已对大量常用函数进行解析
数据准备
Kaggle 数据集
Kaggle 数据集的下载参见 TensorFlow实现kaggle数据集图像分类Ⅱ——tfrecord数据格式制作,展示,与训练一体综合,详述了如何本地下载以及使用 Google Colab 利用 Kaggle API 进行下载
权重文件
| Version | Size | 说明 |
| vgg16_weights.npz | 527 MB | VGG 16 权重文件,适合 TensorFlow 低阶 API 读取 |
| vgg16_weights_tf_dim_ordering_tf_kernels_notop.h5 | 56.1 MB | VGG 16 权重文件,适合 TensorFlow 高阶 API Keras 读取 |
其中可在此处找到更多关于 VGG 16 的信息,其网页包含 VGG 16 权重文件的下载,VGG 16 模型搭建文件以及分类文件等,其中 vgg16_weights_tf_dim_ordering_tf_kernels_notop.h5 在 TensorFlow 2.x 高阶 API Keras 运行时会自动下载

Transfer Learning(迁移学习)
背景
随着大量机器学习模型的诞生,一个好的模型,往往网络非常深,参数基本达到了千万级别,甚至有的参数更高达过亿,而在神经网络的众多层中,其中大量的层都在做同一个问题,如何提取输入数据的特征,神经网络中本就有共享权重这一思想(卷积核操作就体现了这一思想),为此,如何将共享权重这一思想用于不同数据但同类型的数据集?迁移学习很好的解决了这一个问题
迁移学习的实现
迁移学习中使用的模型被称为预训练模型(pre-trained model),预训练模型基本是业界公认的经典且优异的神经网络模型,本节则将已 VGG 系列的 VGG 16 为例进行 transfer learning

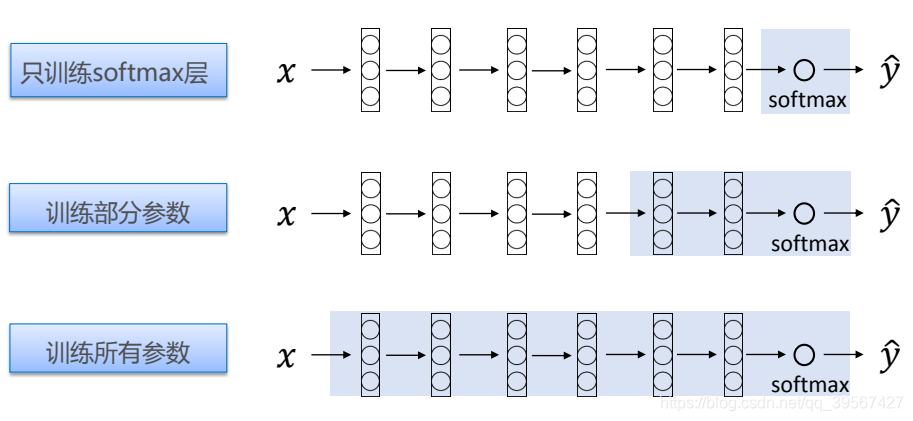
VGG 16 预训练模型是在 imagenet 图像数据库训练得出,含有 1000 个分类任务,我们通过固定其前面提取特征的各个网络层的权重,仅仅将高层(这里我们将已 softmax 层为例)进行重新训练,因为我们的数据集只有猫狗两种类别,为此在最后一层,我们不能读取 VGG 16 的参数(因为最后一层 VGG 16 是一个1000分类层),简单来说就是**利用已经训练好的模型作为新模型训练的初始化的学习方式**,其直观表达如下
 Transfer Learning
Transfer Learning

迁移学习优劣
再次注意:迁移学习需要在相似任务与相似数据集情况下使用
优势
●所需样本数量更少,imagenet 图像数据量达百万级,而此次训练的 Kaggle 数据集仅为 25000 张,数量级差距明显,因此,可将其是为小样本
●模型达到收敛所需耗时更短,沿用了预训练模型的大量权重,显著降低收敛时间,比如:网络在Cifar-10数据集上迭代训练5000次收敛,将一个在Cifar-100上训练好的模型迁移至Cifar-10上,只需1000次就能收敛
●解决算力不足,由于从头训练需要训练大量参数,而迁移学习仅需训练少量层参数
劣势
●损失值下降的更少,模型精度也会相应的降低
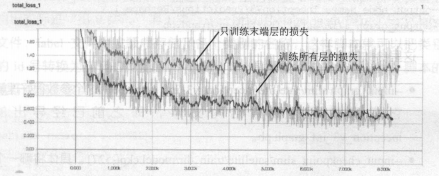
当然,可以选择多的层数进行训练来降低loss,而不仅仅只训练末端层,甚至可以将迁移学习的所有权重作为初始化权值
模型搭建与部分函数文件解析
VGG 16

VGG 16 顾名思义一共有 16 层,其中卷积层(conv)有 13 层,池化层(pool)有5 层,全连接层(fc)有 3 层在加一个 softmax 分类层,其中网络将卷积池化分为 5 组,依次输出通道为 64,128,256,512,512通道,13 层卷积层与 3 层全连接层中的参数包括权重(weights)与偏置(bias)一共 32 个参数
网络搭建文件
vgg16model.py
适用于 Tensor Flow 1.x
| 函数(方法) | 作用 |
|---|---|
| def init(self, imgs) | 构造函数,构建对象即执行,生成网络 |
| def saver(self) | 未用到,可以删除 |
| def maxpool(self, name, input_data) | 单个池化层 |
| def conv(self, name, input_data, out_channel, trainable=False) | 单个卷积层 |
| def fc(self, name, input_data, out_channel, trainable=True) | 单个全连接层 |
| def convlayers(self) | 卷积池化网络层 |
| def fc_layers(self) | 全连接层 |
| def load_weights(self, weight_file, sess) | 参数装载 |
import tensorflow as tf
import numpy as np
class vgg16:
def __init__(self, imgs):
self.parameters = []
self.imgs = imgs
self.convlayers()
self.fc_layers()
self.probs = tf.nn.softmax(self.fc8)
self.step = tf.Variable(0, name='step', trainable=False)
def saver(self):
return tf.train.Saver()
def maxpool(self, name, input_data):
out = tf.nn.max_pool(input_data, [1, 2, 2, 1], [1, 2, 2, 1], padding="SAME", name=name)
return out
def conv(self, name, input_data, out_channel, trainable=False):
in_channel = input_data.get_shape()[-1]
with tf.variable_scope(name):
kernel = tf.get_variable("weights", [3, 3, in_channel, out_channel], dtype=tf.float32, trainable=False)
biases = tf.get_variable("bias", [out_channel], dtype=tf.float32, trainable=False)
conv_res = tf.nn.conv2d(input_data, kernel, [1, 1, 1, 1], padding="SAME")
res = tf.nn.bias_add(conv_res, biases)
out = tf.nn.relu(res, name=name)
self.parameters += [kernel, biases]
return out
def fc(self, name, input_data, out_channel, trainable=True):
shape = input_data.get_shape().as_list()
if len(shape) == 4:
size = shape[-1] * shape[-2] * shape[-3]
else:
size = shape[1]
input_data_flat = tf.reshape(input_data, [-1, size])
with tf.variable_scope(name):
weights = tf.get_variable("weights", shape=[size, out_channel], dtype=tf.float32, trainable=trainable)
biases = tf.get_variable("bias", shape=[out_channel], dtype=tf.float32, trainable=trainable)
res = tf.matmul(input_data_flat, weights)
out = tf.nn.relu(tf.nn.bias_add(res, biases))
self.parameters += [weights, biases]
return out
def convlayers(self):
self.conv1_1 = self.conv("conv1re_1", self.imgs, 64, trainable=False)
self.conv1_2 = self.conv("conv1_2", self.conv1_1, 64, trainable=False)
self.pool1 = self.maxpool("poolre1", self.conv1_2)
self.conv2_1 = self.conv("conv2_1", self.pool1, 128, trainable=False)
self.conv2_2 = self.conv("convwe2_2", self.conv2_1, 128, trainable=False)
self.pool2 = self.maxpool("pool2", self.conv2_2)
self.conv3_1 = self.conv("conv3_1", self.pool2, 256, trainable=False)
self.conv3_2 = self.conv("convrwe3_2", self.conv3_1, 256, trainable=False)
self.conv3_3 = self.conv("convrew3_3", self.conv3_2, 256, trainable=False)
self.pool3 = self.maxpool("poolre3", self.conv3_3)
self.conv4_1 = self.conv("conv4_1", self.pool3, 512, trainable=False)
self.conv4_2 = self.conv("convrwe4_2", self.conv4_1, 512, trainable=False)
self.conv4_3 = self.conv("conv4rwe_3", self.conv4_2, 512, trainable=False)
self.pool4 = self.maxpool("pool4", self.conv4_3)
self.conv5_1 = self.conv("conv5_1", self.pool4, 512, trainable=False)
self.conv5_2 = self.conv("convrwe5_2", self.conv5_1, 512, trainable=False)
self.conv5_3 = self.conv("conv5_3", self.conv5_2, 512, trainable=False)
self.pool5 = self.maxpool("poorwel5", self.conv5_3)
def fc_layers(self):
self.fc6 = self.fc("fc1", self.pool5, 4096, trainable=False)
self.fc7 = self.fc("fc2", self.fc6, 4096, trainable=False)
self.fc8 = self.fc("fc3", self.fc7, 2, trainable=True)
def load_weights(self, weight_file, sess):
weights = np.load(weight_file)
keys = sorted(weights.keys())
for i, k in enumerate(keys):
if i not in [30, 31]:
sess.run(self.parameters[i].assign(weights[k]))
print("----------------------weights loaded----------------------")
utils.py
适用于 Tensor Flow 1.x
| 函数(方法) | 作用 |
|---|---|
| def get_file(file_dir) | 获取图像与标签列表 |
| def get_batch(image_list, label_list, img_width, img_height, batch_size, capacity) | 获取训练批次 |
import os
import numpy as np
from vgg_preprocess import preprocess_for_train
import tensorflow as tf
def get_file(file_dir):
labels = []
images = []
for root, _, files in os.walk(file_dir):
for name in files:
cls_name = name.split('.')[0]
if cls_name == 'cat':
labels.append(0)
images.append(file_dir + name)
else:
labels.append(1)
images.append(file_dir + name)
temp = np.array([images, labels])
temp = temp.transpose()
np.random.shuffle(temp)
image_list = list(temp[:, 0])
label_list = list(temp[:, 1])
label_list = [int(float(i)) for i in label_list]
return image_list, label_list
img_width = 224
img_height = 224
def get_batch(image_list, label_list, img_width, img_height, batch_size, capacity):
image = tf.cast(image_list, tf.string)
label = tf.cast(label_list, tf.int32)
input_queue = tf.train.slice_input_producer([image, label])
label = input_queue[1]
image_contents = tf.read_file(input_queue[0])
image = tf.image.decode_jpeg(image_contents, channels=3)
image = preprocess_for_train(image, 224, 224)
image_batch, label_batch = tf.train.batch([image, label], batch_size=batch_size, num_threads=64, capacity=capacity)
label_batch = tf.reshape(label_batch, [batch_size])
return image_batch, label_batch
vgg_preprocess.py
适用于 Tensor Flow 1.x,由 TensorFlow 官方团队制定,其来源于 Google 官方 models,存放于图像分类 API research/slim/preprocessing 文件夹下,其主要功能包括图像尺寸缩放,数据增强,点击此处查看
TransferLearning TensorFLow 1.x 实现
开始训练
导入必要的包
import os
import cv2
import tensorflow as tf
from time import time
import vgg16model as model
import utils
import matplotlib.pyplot as plt
import numpy as np
from sklearn.preprocessing import OneHotEncoder
print('GPU is', 'available' if tf.test.is_gpu_available() else 'Not available')
GPU is available
开始训练
tf.reset_default_graph()
file_dir = 'data/train/'
train_steps = 200
startTime = time()
batch_size = 50
capacity = 256
means = [123.68, 116.779, 103.939]
xs, ys = utils.get_file(file_dir)
image_batch, label_batch = utils.get_batch(xs, ys, 224, 224, batch_size, capacity)
x = tf.placeholder(tf.float32, [None, 224, 224, 3])
y = tf.placeholder(tf.int32, [None, 2])
encoder = OneHotEncoder(sparse=False)
one_hot = [[0],[1]]
encoder.fit(one_hot)
vgg = model.vgg16(x)
fc8_finetuining = vgg.probs
loss_function = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=fc8_finetuining, labels=y))
accuracy = tf.reduce_mean(tf.cast(tf.equal(tf.argmax(fc8_finetuining, 1),
tf.argmax(y, 1)),'float32'))
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.001).minimize(loss_function)
sess = tf.Session()
sess.run(tf.global_variables_initializer())
log_dir = './dogs_vs_cats_log/'
if not os.path.exists(log_dir):
os.makedirs(log_dir)
writer = tf.summary.FileWriter(log_dir, sess.graph)
image_shape_input = tf.reshape(x, [-1, 224, 224, 1])
tf.summary.image('input', image_shape_input, 9)
tf.summary.histogram('forward', fc8_finetuining)
tf.summary.scalar('loss', loss_function)
tf.summary.scalar('accuracy', accuracy)
merged_summary_op = tf.summary.merge_all()
ckpt_dir = 'local_model'
ckpt = tf.train.latest_checkpoint(ckpt_dir)
saver = tf.train.Saver()
if ckpt != None:
saver.restore(sess, ckpt)
print('----------------------checkpoint model loaded----------------------')
else:
vgg.load_weights('./vgg16_weights.npz', sess)
saver = tf.train.Saver(max_to_keep = 5)
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(coord=coord, sess=sess)
start = sess.run(vgg.step)
print("Training starts from {} step.".format(start + 1))
loss_list = []
accuracy_list = []
for i in range(start, train_steps):
images, labels = sess.run([image_batch, label_batch])
labels = labels.reshape(-1, 1)
labels = encoder.transform(labels)
sess.run(optimizer, feed_dict={x:images, y:labels})
summary_str, loss, acc = sess.run([merged_summary_op, loss_function, accuracy], feed_dict={x:images, y:labels})
print("Train Step:", '%02d' % (i + 1), "Loss=", "{:.6f}".format(loss), "Accuracy=", acc)
writer.add_summary(summary_str, i)
loss_list.append(loss)
accuracy_list.append(acc)
if (i + 1) % 10 == 0:
sess.run((vgg.step).assign(i + 1))
saver.save(sess, os.path.join("./local_model/", 'step_{:03d}.ckpt'.format(i + 1)))
print("./local_model/", 'step_{:03d}.ckpt saved!'.format(i + 1))
duration = time() - startTime
print("Train Finished takes:", "{:.2f}".format(duration))
coord.request_stop()
coord.join(threads)
部分训练过程如下
----------------------weights loaded----------------------
Train Step: 180 Loss= 0.406750 Accuracy= 0.94
./model/ step_180.ckpt saved!
Train Step: 181 Loss= 0.474592 Accuracy= 0.84
Train Step: 182 Loss= 0.433815 Accuracy= 0.9
Train Step: 183 Loss= 0.446380 Accuracy= 0.84
Train Step: 184 Loss= 0.405504 Accuracy= 0.92
Train Step: 185 Loss= 0.463365 Accuracy= 0.86
Train Step: 186 Loss= 0.472064 Accuracy= 0.88
Train Step: 187 Loss= 0.431420 Accuracy= 0.92
Train Step: 188 Loss= 0.405534 Accuracy= 0.92
Train Step: 189 Loss= 0.439118 Accuracy= 0.86
Train Step: 190 Loss= 0.405207 Accuracy= 0.92
./model/ step_190.ckpt saved!
Train Step: 191 Loss= 0.443627 Accuracy= 0.88
Train Step: 192 Loss= 0.432028 Accuracy= 0.9
Train Step: 193 Loss= 0.406260 Accuracy= 0.94
Train Step: 194 Loss= 0.452374 Accuracy= 0.86
Train Step: 195 Loss= 0.379888 Accuracy= 0.94
Train Step: 196 Loss= 0.390018 Accuracy= 0.94
Train Step: 197 Loss= 0.429657 Accuracy= 0.9
Train Step: 198 Loss= 0.442157 Accuracy= 0.84
Train Step: 199 Loss= 0.413196 Accuracy= 0.92
Train Step: 200 Loss= 0.397276 Accuracy= 0.92
./model/ step_200.ckpt saved!
Train Finished takes: 1121.14
训练可视化
fig = plt.gcf()
fig.set_size_inches(10, 5)
ax1 = fig.add_subplot(111)
ax1.set_title('Train and Validation Picture')
ax1.set_ylabel('Loss value')
line1, = ax1.plot(loss_list, color=(0.5, 0.5, 1.0), label='Loss train')
ax2 = ax1.twinx()
ax2.set_ylabel('Accuracy value')
line2, = ax2.plot(accuracy_list, color=(0.5, 0.5, 0.5), label='Accuracy train')
plt.legend(handles=(line1, line2), loc='best')
plt.show()

单张预测
tf.reset_default_graph()
means = [123.68, 116.779, 103.939]
x = tf.placeholder(tf.float32, [None, 224, 224, 3])
sess = tf.Session()
vgg = model.vgg16(x)
fc8_finetuining = vgg.probs
saver = tf.train.Saver()
ckpt_dir = 'local_model'
ckpt = tf.train.latest_checkpoint(ckpt_dir)
print("Model restoring...")
#saver.restore(sess, './local_model/step_xxx.ckpt')
saver.restore(sess, ckpt)
filepath = 'data/test1/7.jpg'
img = cv2.imread(filepath)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = cv2.resize(img, (224, 224))
img = img.astype(np.float32)
IMG = img.copy()
for c in range(3):
img[:, :, c] -= means[c]
prob = sess.run(fc8_finetuining, feed_dict={x: [img]})
max_index = np.argmax(prob)
if max_index == 0:
cls_name = 'cat'
print("This is a cat with possibility %.6f" % prob[:, 0])
else:
cls_name = 'dog'
print("This is a dog with possibility %.6f" % prob[:, 1])
sess.close()
plt.imshow(IMG.astype('uint8'))
plt.title('Predict:' + cls_name)
plt.show()
Model restoring...
INFO:tensorflow:Restoring parameters from local_model\step_200.ckpt
This is a cat with possibility 0.999851

多张预测
tf.reset_default_graph()
means = [123.68, 116.779, 103.939]
x = tf.placeholder(tf.float32, [None, 224, 224, 3])
sess = tf.Session()
vgg = model.vgg16(x)
fc8_finetuining = vgg.probs
saver = tf.train.Saver()
ckpt_dir = 'local_model'
ckpt = tf.train.latest_checkpoint(ckpt_dir)
print("Model restoring...")
#saver.restore(sess, './local_model/step_xxx.ckpt')
saver.restore(sess, ckpt)
file_i = np.random.randint(12500, size=(1, 8))
filepath = []
plt_images = []
pre_images = []
root_dir = 'data/test1/'
for i in range(file_i.shape[1]):
filepath.append(root_dir + str(file_i[0][i]) + '.jpg')
for path in filepath:
img = cv2.imread(path)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = cv2.resize(img, (224, 224))
img = img.astype(np.float32)
IMG = img.copy()
plt_images.append(IMG)
del IMG
for c in range(3):
img[:, :, c] -= means[c]
pre_images.append(img)
image_batch = np.array(pre_images)
prob = sess.run(fc8_finetuining, feed_dict={x: image_batch})
max_index = np.argmax(prob, 1)
sess.close()
fig = plt.gcf()
fig.set_size_inches(20, 10)
for i in range(8):
if max_index[i] == 0:
cls_name = 'cat'
else:
cls_name = 'dog'
ax = plt.subplot(2, 4, 1 + i)
ax.imshow(plt_images[i].astype('uint8'), cmap='binary')
title = 'Prediction:' + cls_name
ax.set_title(title, fontsize=20)
plt.show()

查看模型与日志文件
查看模型
此程序支持断点续训,并最大保存邻近的 5 个模型

查看日志文件
利用 jupyter 查看模型,在Tensorflow 笔记 Ⅰ——TensorFlow 编程基础 中有两种方法的详细介绍,在此不赘述




TransferLearning TensorFLow 2.x 低阶 API 实现
前情步骤
查看显卡信息
!nvidia-smi
Tue May 5 12:48:22 2020
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 440.64.00 Driver Version: 418.67 CUDA Version: 10.1 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla P100-PCIE... Off | 00000000:00:04.0 Off | 0 |
| N/A 33C P0 26W / 250W | 0MiB / 16280MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
利用 Kaggle API 下载数据集
!mkdir .kaggle
# 导入 API Token,token 为上述 kaggle.json 文件内容,创建一个 kaggle.json 文件
import json
token = {"username":"qhaoguo","key":"bf88c68cc306ec951f78f9f3a23f7246"}
with open('/content/.kaggle/kaggle.json', 'w') as file:
json.dump(token, file)
# 让 kaggle.json 赋予更高的权限
!chmod 600 /content/.kaggle/kaggle.json
# 复制到系统目录
!mkdir ~/.kaggle
!cp /content/.kaggle/kaggle.json ~/.kaggle/kaggle.json
# 设置下载的文件夹路径
!kaggle config set -n path -v /content
- path is now set to: /content
# 粘贴命令并顺便指明存储路径
!kaggle competitions download -c dogs-vs-cats -p /content
Warning: Looks like you're using an outdated API Version, please consider updating (server 1.5.6 / client 1.5.4)
Downloading train.zip to /content
97% 529M/543M [00:04<00:00, 112MB/s]
100% 543M/543M [00:04<00:00, 117MB/s]
Downloading sampleSubmission.csv to /content
0% 0.00/86.8k [00:00<?, ?B/s]
100% 86.8k/86.8k [00:00<00:00, 77.8MB/s]
Downloading test1.zip to /content
99% 268M/271M [00:03<00:00, 131MB/s]
100% 271M/271M [00:03<00:00, 92.4MB/s]
解压数据集
!unzip train.zip
inflating: train/dog.9990.jpg
inflating: train/dog.9991.jpg
inflating: train/dog.9992.jpg
inflating: train/dog.9993.jpg
inflating: train/dog.9994.jpg
inflating: train/dog.9995.jpg
inflating: train/dog.9996.jpg
inflating: train/dog.9997.jpg
inflating: train/dog.9998.jpg
inflating: train/dog.9999.jpg
!unzip test1.zip
inflating: test1/9990.jpg
inflating: test1/9991.jpg
inflating: test1/9992.jpg
inflating: test1/9993.jpg
inflating: test1/9994.jpg
inflating: test1/9995.jpg
inflating: test1/9996.jpg
inflating: test1/9997.jpg
inflating: test1/9998.jpg
inflating: test1/9999.jpg
获取权重文件
!wget https://www.cs.toronto.edu/~frossard/vgg16/vgg16_weights.npz
--2020-05-05 12:49:16-- https://www.cs.toronto.edu/~frossard/vgg16/vgg16_weights.npz
Resolving www.cs.toronto.edu (www.cs.toronto.edu)... 128.100.3.30
Connecting to www.cs.toronto.edu (www.cs.toronto.edu)|128.100.3.30|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 553436134 (528M)
Saving to: ‘vgg16_weights.npz’
vgg16_weights.npz 100%[===================>] 527.80M 49.1MB/s in 11s
2020-05-05 12:49:27 (48.0 MB/s) - ‘vgg16_weights.npz’ saved [553436134/553436134]
正式开始
导入必要的包
import tensorflow as tf
import os
import numpy as np
import cv2
import matplotlib.pyplot as plt
tf.__version__
'2.2.0-rc3'
设置超参数
learning_rate = 0.0001
BATCH_SIZE = 50
training_steps = 1000
display_step = 20
HEIGHT = 224
WIDTH = 224
NUM_CHANNELS = 3
定义卷积与池化
def conv2d(x, W, b, strides=1):
x = tf.nn.conv2d(x, W, strides=[1, strides, strides, 1], padding='SAME')
x = tf.nn.bias_add(x, b)
return tf.nn.relu(x)
def maxpool2d(x, k=2):
return tf.nn.max_pool(x, ksize=[1, k, k, 1], strides=[1, k, k, 1], padding='SAME')
定义权值
random_normal = tf.initializers.RandomNormal()
parameters = {
'conv1_1_W': tf.Variable(random_normal([3, 3, 3, 64]), trainable=False),
'conv1_1_b': tf.Variable(tf.zeros([64]), trainable=False),
'conv1_2_W': tf.Variable(random_normal([3, 3, 64, 64]), trainable=False),
'conv1_2_b': tf.Variable(tf.zeros([64]), trainable=False),
'conv2_1_W': tf.Variable(random_normal([3, 3, 64, 128]), trainable=False),
'conv2_1_b': tf.Variable(tf.zeros([128]), trainable=False),
'conv2_2_W': tf.Variable(random_normal([3, 3, 128, 128]), trainable=False),
'conv2_2_b': tf.Variable(tf.zeros([128]), trainable=False),
'conv3_1_W': tf.Variable(random_normal([3, 3, 128, 256]), trainable=False),
'conv3_1_b': tf.Variable(tf.zeros([256]), trainable=False),
'conv3_2_W': tf.Variable(random_normal([3, 3, 256, 256]), trainable=False),
'conv3_2_b': tf.Variable(tf.zeros([256]), trainable=False),
'conv3_3_W': tf.Variable(random_normal([3, 3, 256, 256]), trainable=False),
'conv3_3_b': tf.Variable(tf.zeros([256]), trainable=False),
'conv4_1_W': tf.Variable(random_normal([3, 3, 256, 512]), trainable=False),
'conv4_1_b': tf.Variable(tf.zeros([512]), trainable=False),
'conv4_2_W': tf.Variable(random_normal([3, 3, 512, 512]), trainable=False),
'conv4_2_b': tf.Variable(tf.zeros([512]), trainable=False),
'conv4_3_W': tf.Variable(random_normal([3, 3, 512, 512]), trainable=False),
'conv4_3_b': tf.Variable(tf.zeros([512]), trainable=False),
'conv5_1_W': tf.Variable(random_normal([3, 3, 512, 512]), trainable=False),
'conv5_1_b': tf.Variable(tf.zeros([512]), trainable=False),
'conv5_2_W': tf.Variable(random_normal([3, 3, 512, 512]), trainable=False),
'conv5_2_b': tf.Variable(tf.zeros([512]), trainable=False),
'conv5_3_W': tf.Variable(random_normal([3, 3, 512, 512]), trainable=False),
'conv5_3_b': tf.Variable(tf.zeros([512]), trainable=False),
'fc6_W': tf.Variable(random_normal([25088, 4096]), trainable=False),
'fc6_b': tf.Variable(tf.zeros([4096]), trainable=False),
'fc7_W': tf.Variable(random_normal([4096, 4096]), trainable=False),
'fc7_b': tf.Variable(tf.zeros([4096]), trainable=False),
'fc8_W': tf.Variable(random_normal([4096, 2]), trainable=True),
'fc8_b': tf.Variable(tf.zeros([2]), trainable=True)
}
加载权重
weights = np.load('./vgg16_weights.npz')
keys = sorted(weights.keys())
for i, k in enumerate(keys):
if i not in [30, 31]:
parameters[k] = tf.cast(weights[k], tf.float32)
定义网络
def conv_net(x):
x = tf.reshape(x, [-1, 224, 224, 3])
conv1_1 = conv2d(x, parameters['conv1_1_W'], parameters['conv1_1_b'])
conv1_2 = conv2d(conv1_1, parameters['conv1_2_W'], parameters['conv1_2_b'])
pool1 = maxpool2d(conv1_2, k=2)
conv2_1 = conv2d(pool1, parameters['conv2_1_W'], parameters['conv2_1_b'])
conv2_2 = conv2d(conv2_1, parameters['conv2_2_W'], parameters['conv2_2_b'])
pool2 = maxpool2d(conv2_2, k=2)
conv3_1 = conv2d(pool2, parameters['conv3_1_W'], parameters['conv3_1_b'])
conv3_2 = conv2d(conv3_1, parameters['conv3_2_W'], parameters['conv3_2_b'])
conv3_3 = conv2d(conv3_2, parameters['conv3_3_W'], parameters['conv3_3_b'])
pool3 = maxpool2d(conv3_3, k=2)
conv4_1 = conv2d(pool3, parameters['conv4_1_W'], parameters['conv4_1_b'])
conv4_2 = conv2d(conv4_1, parameters['conv4_2_W'], parameters['conv4_2_b'])
conv4_3 = conv2d(conv4_2, parameters['conv4_3_W'], parameters['conv4_3_b'])
pool4 = maxpool2d(conv4_3, k=2)
conv5_1 = conv2d(pool4, parameters['conv5_1_W'], parameters['conv5_1_b'])
conv5_2 = conv2d(conv5_1, parameters['conv5_2_W'], parameters['conv5_2_b'])
conv5_3 = conv2d(conv5_2, parameters['conv5_3_W'], parameters['conv5_3_b'])
pool5 = maxpool2d(conv5_3, k=2)
flat = tf.reshape(pool5, [-1, parameters['fc6_W'].shape[0]])
fc6 = tf.add(tf.matmul(flat, parameters['fc6_W']), parameters['fc6_b'])
fc6 = tf.nn.relu(fc6)
fc7 = tf.add(tf.matmul(fc6, parameters['fc7_W']), parameters['fc7_b'])
fc7 = tf.nn.relu(fc7)
out = tf.add(tf.matmul(fc7, parameters['fc8_W']), parameters['fc8_b'])
return tf.nn.softmax(out)
数据处理与装载函数
def preprocess_image(image):
image = tf.image.decode_jpeg(image, channels=NUM_CHANNELS)
image = tf.image.resize(image, [HEIGHT, WIDTH])
image /= 255.0
return image
def load_and_preprocess_image(path):
image = tf.io.read_file(path)
return preprocess_image(image)
def get_file(file_dir):
labels = []
images = []
for root, _, files in os.walk(file_dir):
for name in files:
cls_name = name.split('.')[0]
if cls_name == 'cat':
labels.append(0)
images.append(file_dir + name)
else:
labels.append(1)
images.append(file_dir + name)
temp = np.array([images, labels])
temp = temp.transpose()
np.random.shuffle(temp)
image_list = list(temp[:, 0])
label_list = list(temp[:, 1])
label_list = [int(float(i)) for i in label_list]
return image_list, label_list
file_dir = 'train/'
files, categories = get_file(file_dir)
path_dataset = tf.data.Dataset.from_tensor_slices(files)
image_dataset = path_dataset.map(load_and_preprocess_image, num_parallel_calls=tf.data.experimental.AUTOTUNE)
label_dataset = tf.data.Dataset.from_tensor_slices(tf.cast(categories, tf.int64))
image_label_dataset = tf.data.Dataset.zip((image_dataset, label_dataset))
dataset = image_label_dataset.repeat().shuffle(1000).batch(BATCH_SIZE).prefetch(1)
定义准确率与损失函数
def cross_entropy(y_pred, y_true):
y_pred = tf.clip_by_value(y_pred, 1e-9, 1.)
loss_ = tf.keras.losses.sparse_categorical_crossentropy(y_true=y_true, y_pred=y_pred)
return tf.reduce_mean(loss_)
def accuracy(y_pred, y_true):
correct_prediction = tf.equal(tf.argmax(y_pred, 1), tf.reshape(tf.cast(y_true, tf.int64), [-1]))
return tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
optimizer = tf.optimizers.Adam(learning_rate)
定义梯度下降
def run_optimization(x, y):
with tf.GradientTape() as g:
pred = conv_net(x)
loss = cross_entropy(pred, y)
trainable_variables = [list(parameters.values())[-1], list(parameters.values())[-2]]
gradients = g.gradient(loss, trainable_variables)
optimizer.apply_gradients(zip(gradients, trainable_variables))
开始训练
train_loss_list = []
train_acc_list = []
for step, (batch_x, batch_y) in enumerate(dataset.take(training_steps), 1):
run_optimization(batch_x, batch_y)
pred = conv_net(batch_x)
loss = cross_entropy(pred, batch_y)
acc = accuracy(pred, batch_y)
train_loss_list.append(loss.numpy())
train_acc_list.append(acc.numpy())
if step % display_step == 0:
pred = conv_net(batch_x)
loss = cross_entropy(pred, batch_y)
acc = accuracy(pred, batch_y)
print("step: %i, loss: %f, accuracy: %f" % (step, loss, acc))
部分训练如下
step: 800, loss: 0.286215, accuracy: 0.900000
step: 820, loss: 0.348468, accuracy: 0.900000
step: 840, loss: 0.380456, accuracy: 0.820000
step: 860, loss: 0.476971, accuracy: 0.800000
step: 880, loss: 0.376081, accuracy: 0.800000
step: 900, loss: 0.332010, accuracy: 0.840000
step: 920, loss: 0.390494, accuracy: 0.800000
step: 940, loss: 0.286899, accuracy: 0.880000
step: 960, loss: 0.316757, accuracy: 0.840000
step: 980, loss: 0.311071, accuracy: 0.840000
step: 1000, loss: 0.245536, accuracy: 0.940000
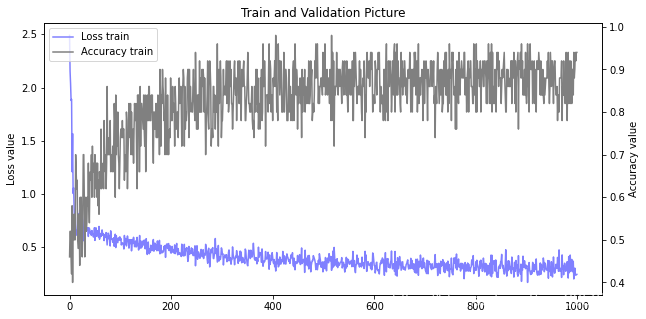
训练可视化
fig = plt.gcf()
fig.set_size_inches(10, 5)
ax1 = fig.add_subplot(111)
ax1.set_title('Train and Validation Picture')
ax1.set_ylabel('Loss value')
line1, = ax1.plot(train_loss_list, color=(0.5, 0.5, 1.0), label='Loss train')
ax2 = ax1.twinx()
ax2.set_ylabel('Accuracy value')
line2, = ax2.plot(train_acc_list, color=(0.5, 0.5, 0.5), label='Accuracy train')
plt.legend(handles=(line1, line2), loc='best')
plt.show()
file_i = np.random.randint(12500, size=(1, 8))
filepath = []
plt_images = []
pre_images = []
root_dir = 'test1/'
for i in range(file_i.shape[1]):
filepath.append(root_dir + str(file_i[0][i]) + '.jpg')
for path in filepath:
img = cv2.imread(path)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = cv2.resize(img, (224, 224))
img = img.astype(np.float32)
IMG = img.copy()
plt_images.append(IMG)
del IMG
pre_images.append(img)
image_batch = np.array(pre_images)
pred = conv_net(image_batch)
max_index = np.argmax(pred, 1)
fig = plt.gcf()
fig.set_size_inches(20, 10)
for i in range(8):
if max_index[i] == 0:
cls_name = 'cat'
else:
cls_name = 'dog'
ax = plt.subplot(2, 4, 1 + i)
ax.imshow(plt_images[i].astype('uint8'), cmap='binary')
title = 'Prediction:' + cls_name
ax.set_title(title, fontsize=20)
plt.show()

保存权重
np.savez('cats_vs_dogs.npz', conv1_1_W=parameters['conv1_1_W'], conv1_1_b=parameters['conv1_1_b'],conv1_2_W=parameters['conv1_2_W'], conv1_2_b=parameters['conv1_2_b'],
conv2_1_W=parameters['conv2_1_W'], conv2_1_b=parameters['conv2_1_b'], conv2_2_W=parameters['conv2_2_W'], conv2_2_b=parameters['conv2_2_b'],
conv3_1_W=parameters['conv3_1_W'], conv3_1_b=parameters['conv3_1_b'], conv3_2_W=parameters['conv3_2_W'], conv3_2_b=parameters['conv3_2_b'],
conv3_3_W=parameters['conv3_3_W'], conv3_3_b=parameters['conv3_3_b'], conv4_1_W=parameters['conv4_1_W'], conv4_1_b=parameters['conv4_1_b'],
conv4_2_W=parameters['conv4_2_W'], conv4_2_b=parameters['conv4_2_b'], conv4_3_W=parameters['conv4_3_W'], conv4_3_b=parameters['conv4_3_b'],
conv5_1_W=parameters['conv5_1_W'], conv5_1_b=parameters['conv5_1_b'], conv5_2_W=parameters['conv5_2_W'], conv5_2_b=parameters['conv5_2_b'],
conv5_3_W=parameters['conv5_3_W'], conv5_3_b=parameters['conv5_3_b'], fc6_W=parameters['fc6_W'], fc6_b=parameters['fc6_b'],
fc7_W=parameters['fc7_W'], fc7_b=parameters['fc7_b'], fc8_W=parameters['fc8_W'], fc8_b=parameters['fc8_b'],)
重启环境并导入已训练权重
weights = np.load('./cats_vs_dogs.npz')
keys = sorted(weights.keys())
for i, k in enumerate(keys):
if i not in [30, 31]:
parameters[k] = tf.cast(weights[k], tf.float32)
利用已训练权重进行识别
file_i = np.random.randint(12500, size=(1, 8))
filepath = []
plt_images = []
pre_images = []
root_dir = 'test1/'
for i in range(file_i.shape[1]):
filepath.append(root_dir + str(file_i[0][i]) + '.jpg')
for path in filepath:
img = cv2.imread(path)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = cv2.resize(img, (224, 224))
img = img.astype(np.float32)
IMG = img.copy()
plt_images.append(IMG)
del IMG
pre_images.append(img)
image_batch = np.array(pre_images)
pred = conv_net(image_batch)
max_index = np.argmax(pred, 1)
fig = plt.gcf()
fig.set_size_inches(20, 10)
for i in range(8):
if max_index[i] == 0:
cls_name = 'cat'
else:
cls_name = 'dog'
ax = plt.subplot(2, 4, 1 + i)
ax.imshow(plt_images[i].astype('uint8'), cmap='binary')
title = 'Prediction:' + cls_name
ax.set_title(title, fontsize=20)
plt.show()

TransferLearning TensorFLow 2.x 高阶 API Keras 实现
Global Average Pooling 层
细心的读者可以发现,在使用 TensorFLow 2.x 高阶 API Keras 搭建网络时,我们在全连接部分没有使用全连接层,而是使用 GlobalAveragePooling2D 来代替
Global Average Pooling(简称GAP,全局池化层)技术最早提出是在这篇论文
(第3.2节)中,被认为是可以替代全连接层的一种新技术。在 keras 发布的经典模型中,可以看到不少模型甚至抛弃了全连接层,转而使用GAP,而在支持迁移学习方面,各个模型几乎都支持使用 Global Average Pooling 和Global Max Pooling(GMP),究其原因有两点:一是GAP在特征图与最终的分类间转换更加简单自然;二是不像FC层需要大量训练调优的参数,降低了空间参数会使模型更加健壮,抗过拟合效果更佳,具体原理将在后面的博客给出,读者也可自行 Google 其原始论文进行查看
开始训练
导入必要包
import tensorflow as tf
import os
import numpy as np
import matplotlib.pyplot as plt
import cv2
import datetime
print('GPU is', 'available' if tf.test.is_gpu_available() else 'Not available')
GPU is available
tf.__version__
'2.0.0'
超参数设置
NCLASSES: 分类的类别数
HEIGHT: 根据模型输入尺寸要求更改,VGG 采用(batch_size, 224, 224, 3)
WIDTH: 根据模型输入尺寸要求更改,VGG 采用(batch_size, 224, 224, 3)
NUM_CHANNELS: 根据模型输入尺寸要求更改,VGG 采用(batch_size, 224, 224, 3)
BATCH_SIZE: 批次大小
NCLASSES = 2
HEIGHT = 224
WIDTH = 224
NUM_CHANNELS = 3
BATCH_SIZE = 50
Keras预装载模型
base_model = tf.keras.applications.VGG16(input_shape=(HEIGHT, WIDTH, NUM_CHANNELS), include_top=False, weights='imagenet')
base_model.trainable = False
print(base_model.summary())
Model: "vgg16"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 224, 224, 3)] 0
_________________________________________________________________
block1_conv1 (Conv2D) (None, 224, 224, 64) 1792
_________________________________________________________________
block1_conv2 (Conv2D) (None, 224, 224, 64) 36928
_________________________________________________________________
block1_pool (MaxPooling2D) (None, 112, 112, 64) 0
_________________________________________________________________
block2_conv1 (Conv2D) (None, 112, 112, 128) 73856
_________________________________________________________________
block2_conv2 (Conv2D) (None, 112, 112, 128) 147584
_________________________________________________________________
block2_pool (MaxPooling2D) (None, 56, 56, 128) 0
_________________________________________________________________
block3_conv1 (Conv2D) (None, 56, 56, 256) 295168
_________________________________________________________________
block3_conv2 (Conv2D) (None, 56, 56, 256) 590080
_________________________________________________________________
block3_conv3 (Conv2D) (None, 56, 56, 256) 590080
_________________________________________________________________
block3_pool (MaxPooling2D) (None, 28, 28, 256) 0
_________________________________________________________________
block4_conv1 (Conv2D) (None, 28, 28, 512) 1180160
_________________________________________________________________
block4_conv2 (Conv2D) (None, 28, 28, 512) 2359808
_________________________________________________________________
block4_conv3 (Conv2D) (None, 28, 28, 512) 2359808
_________________________________________________________________
block4_pool (MaxPooling2D) (None, 14, 14, 512) 0
_________________________________________________________________
block5_conv1 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_conv2 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_conv3 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_pool (MaxPooling2D) (None, 7, 7, 512) 0
=================================================================
Total params: 14,714,688
Trainable params: 0
Non-trainable params: 14,714,688
_________________________________________________________________
None
设置全连接层
GlobalAveragePooling2D 详述见前面介绍
x = base_model.output
x = tf.keras.layers.GlobalAveragePooling2D()(x)
x = tf.keras.layers.Dense(4096, activation='relu')(x)
x = tf.keras.layers.Dense(2, activation='softmax')(x)
model = tf.keras.models.Model(inputs=base_model.input, outputs=x)
print(model.summary())
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 224, 224, 3)] 0
_________________________________________________________________
block1_conv1 (Conv2D) (None, 224, 224, 64) 1792
_________________________________________________________________
block1_conv2 (Conv2D) (None, 224, 224, 64) 36928
_________________________________________________________________
block1_pool (MaxPooling2D) (None, 112, 112, 64) 0
_________________________________________________________________
block2_conv1 (Conv2D) (None, 112, 112, 128) 73856
_________________________________________________________________
block2_conv2 (Conv2D) (None, 112, 112, 128) 147584
_________________________________________________________________
block2_pool (MaxPooling2D) (None, 56, 56, 128) 0
_________________________________________________________________
block3_conv1 (Conv2D) (None, 56, 56, 256) 295168
_________________________________________________________________
block3_conv2 (Conv2D) (None, 56, 56, 256) 590080
_________________________________________________________________
block3_conv3 (Conv2D) (None, 56, 56, 256) 590080
_________________________________________________________________
block3_pool (MaxPooling2D) (None, 28, 28, 256) 0
_________________________________________________________________
block4_conv1 (Conv2D) (None, 28, 28, 512) 1180160
_________________________________________________________________
block4_conv2 (Conv2D) (None, 28, 28, 512) 2359808
_________________________________________________________________
block4_conv3 (Conv2D) (None, 28, 28, 512) 2359808
_________________________________________________________________
block4_pool (MaxPooling2D) (None, 14, 14, 512) 0
_________________________________________________________________
block5_conv1 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_conv2 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_conv3 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_pool (MaxPooling2D) (None, 7, 7, 512) 0
_________________________________________________________________
global_average_pooling2d (Gl (None, 512) 0
_________________________________________________________________
dense (Dense) (None, 4096) 2101248
_________________________________________________________________
dense_1 (Dense) (None, 2) 8194
=================================================================
Total params: 16,824,130
Trainable params: 2,109,442
Non-trainable params: 14,714,688
_________________________________________________________________
None
定义需求函数
def preprocess_image(image):
image = tf.image.decode_jpeg(image, channels=NUM_CHANNELS)
image = tf.image.resize(image, [HEIGHT, WIDTH])
image /= 255.0
return image
def load_and_preprocess_image(path):
image = tf.io.read_file(path)
return preprocess_image(image)
def get_file(file_dir):
labels = []
images = []
for root, _, files in os.walk(file_dir):
for name in files:
cls_name = name.split('.')[0]
if cls_name == 'cat':
labels.append(0)
images.append(file_dir + name)
else:
labels.append(1)
images.append(file_dir + name)
temp = np.array([images, labels])
temp = temp.transpose()
np.random.shuffle(temp)
image_list = list(temp[:, 0])
label_list = list(temp[:, 1])
label_list = [int(float(i)) for i in label_list]
return image_list, label_list
数据读取
file_dir = 'data/train/'
files, categories = get_file(file_dir)
path_dataset = tf.data.Dataset.from_tensor_slices(files)
image_dataset = path_dataset.map(load_and_preprocess_image, num_parallel_calls=tf.data.experimental.AUTOTUNE)
label_dataset = tf.data.Dataset.from_tensor_slices(tf.cast(categories, tf.int64))
image_label_dataset = tf.data.Dataset.zip((image_dataset, label_dataset))
dataset = image_label_dataset.repeat().shuffle(1000).batch(BATCH_SIZE).prefetch(1)
模型 compile
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
设置回调
log_dir = os.path.join(
'logs2.x',
'train',
'plugins',
'profile',
datetime.datetime.now().strftime('%Y-%m-%d_%H-%M-%S'))
checkpoint_path = './keras_checkpoint2.x/cats_vs_dogs.{epoch:02d}.ckpt'
if not os.path.exists('./keras_checkpoint2.x'):
os.mkdir('./keras_checkpoint2.x')
callbacks = [
tf.keras.callbacks.TensorBoard(log_dir=log_dir,
histogram_freq=2),
tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_path,
save_weights_only=True,
verbose=0,
save_freq='epoch'),
]
开始训练
train_history = model.fit(dataset,
epochs=20,
steps_per_epoch=20,
callbacks=callbacks,
verbose=1)
Train for 20 steps
Epoch 1/20
20/20 [==============================] - 35s 2s/step - loss: 0.7965 - accuracy: 0.5870
Epoch 2/20
20/20 [==============================] - 20s 986ms/step - loss: 0.4286 - accuracy: 0.8000
Epoch 3/20
20/20 [==============================] - 21s 1s/step - loss: 0.3388 - accuracy: 0.8690
Epoch 4/20
20/20 [==============================] - 20s 977ms/step - loss: 0.2689 - accuracy: 0.8860
Epoch 5/20
20/20 [==============================] - 21s 1s/step - loss: 0.2580 - accuracy: 0.8890
Epoch 6/20
20/20 [==============================] - 20s 1s/step - loss: 0.2334 - accuracy: 0.9030
Epoch 7/20
20/20 [==============================] - 22s 1s/step - loss: 0.2449 - accuracy: 0.9060
Epoch 8/20
20/20 [==============================] - 20s 1s/step - loss: 0.2340 - accuracy: 0.9060
Epoch 9/20
20/20 [==============================] - 22s 1s/step - loss: 0.2621 - accuracy: 0.8920
Epoch 10/20
20/20 [==============================] - 20s 1s/step - loss: 0.2434 - accuracy: 0.8980
Epoch 11/20
20/20 [==============================] - 22s 1s/step - loss: 0.1960 - accuracy: 0.9160
Epoch 12/20
20/20 [==============================] - 20s 994ms/step - loss: 0.1814 - accuracy: 0.9360
Epoch 13/20
20/20 [==============================] - 22s 1s/step - loss: 0.2349 - accuracy: 0.9000
Epoch 14/20
20/20 [==============================] - 20s 1s/step - loss: 0.2149 - accuracy: 0.9050
Epoch 15/20
20/20 [==============================] - 22s 1s/step - loss: 0.2052 - accuracy: 0.9080
Epoch 16/20
20/20 [==============================] - 20s 1s/step - loss: 0.2282 - accuracy: 0.9010
Epoch 17/20
20/20 [==============================] - 22s 1s/step - loss: 0.1988 - accuracy: 0.9250
Epoch 18/20
20/20 [==============================] - 20s 1s/step - loss: 0.1928 - accuracy: 0.9200
Epoch 19/20
20/20 [==============================] - 22s 1s/step - loss: 0.2177 - accuracy: 0.9150
Epoch 20/20
20/20 [==============================] - 21s 1s/step - loss: 0.1743 - accuracy: 0.9360
可视化参数
fig = plt.gcf()
fig.set_size_inches(10, 5)
ax1 = fig.add_subplot(111)
ax1.set_title('Train and Validation Picture')
ax1.set_ylabel('Loss value')
line1, = ax1.plot(train_history.history['loss'], color=(0.5, 0.5, 1.0), label='Loss train')
ax2 = ax1.twinx()
ax2.set_ylabel('Accuracy value')
line2, = ax2.plot(train_history.history['accuracy'], color=(0.5, 0.5, 0.5), label='Accuracy train')
plt.legend(handles=(line1, line2), loc='best')
plt.show()
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BLMvNvUG-1588747134481)(output_20_0.png)]](https://img-blog.csdnimg.cn/20200506143956501.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzM5NTY3NDI3,size_16,color_FFFFFF,t_70)
预测可视化
利用TensorFlow2.0 高阶API keras 迁移学习未使用序列化模型,所以不能使用 model.predict_classes(),应使用 model.predict()
file_i = np.random.randint(12500, size=(1, 8))
filepath = []
plt_images = []
pre_images = []
root_dir = 'data/test1/'
for i in range(file_i.shape[1]):
filepath.append(root_dir + str(file_i[0][i]) + '.jpg')
for path in filepath:
img = cv2.imread(path)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = cv2.resize(img, (224, 224))
img = img.astype(np.float32)
IMG = img.copy()
plt_images.append(IMG)
del IMG
pre_images.append(img)
image_batch = np.array(pre_images)
prob = model.predict(image_batch)
max_index = np.argmax(prob, 1)
fig = plt.gcf()
fig.set_size_inches(20, 10)
for i in range(8):
if max_index[i] == 0:
cls_name = 'cat'
else:
cls_name = 'dog'
ax = plt.subplot(2, 4, 1 + i)
ax.imshow(plt_images[i].astype('uint8'), cmap='binary')
title = 'Prediction:' + cls_name
ax.set_title(title, fontsize=20)
plt.show()
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TQqi7MJm-1588747134485)(output_22_0.png)]](https://img-blog.csdnimg.cn/2020050614400433.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzM5NTY3NDI3,size_16,color_FFFFFF,t_70)
查看模型与日志文件
查看模型
此程序支持断点续训

查看日志文件



