1. 为什么使用openvino
openvino是intel开发的深度学习模型推理加速引擎,总体使用感觉就是方便,压缩后的模型再cpu上跑的速度可以媲美gpu(据称精度损失都小于5%)。另外,intel还在不断出配套的硬件,下半年要出货的keem bay性价比已经超越了现在的海康nnie(p.s. 这家的sdk极不友好);使用openvino还有一个优点,就是openvino内置优化过的opencv,处理视频图像更方便。
openvino支持python和c++,下面以python环境为例进行搭建。当然了,java也是可以调用的,技巧就是使用opencv的java编译包。opencv中的深度学习模块支持调用openvino压缩的模型。
2. openvino基本步骤
首先要把训练好的各种模型转换为openvino的标准IR模型(包含一个xml文件和bin文件,分别是模型结构和模型参数),然后调用推理引擎去对输入文件进行预测。
2.1 下载openvino
可以去官网下载安装包:https://software.intel.com/en-us/openvino-toolkit/choose-download
也可以去github上下载:https://github.com/opencv/open_model_zoo
这边是官方文档:https://docs.openvinotoolkit.org/2019_R2/_intel_models_index.html
在执行程序之前需要进行变量初始化:source /opt/intel/computer_vision_sdk/bin/setupvars.sh
cd /opt/intel/openvino/deployment_tools/model_optimizer/install_prerequisites
sudo ./install_prerequisites.sh
测试
cd /opt/intel/openvino/deployment_tools/demo
./demo_squeezenet_download_convert_run.sh
2.2 转换模型
转换脚本在deployment_tools/model_optimizer文件夹下,可以对caffe、tensorflow、onnx文件进行转换,参数为:
–input_model 要转换的模型
–output_dir 输出文件夹
–input shape 可选,可以调整输入影像的大小
–model_name 可选,自定义名称
–input 可选,输入层截断
–output 可选,输出层截断
注意pytorch的模型不能直接转,需要先转换成onnx格式:
from model import with_mobilenet
import onnx,torch
net = with_mobilenet.PoseEstimationWithMobileNet(is_convertible_by_mo=True)
net.load_state_dict((torch.load('human-pose-estimation-3d-0001.pth')))
dummy_input = torch.randn(1,3,256,448)
torch.onnx.export(net,dummy_input ,"pose.onnx")
然后再转为openvino模型
python /opt/intel/openvino/deployment_tools/model_optimizer/mo_onnx.py --input_model 模型地址.onnx
生成bin和xml两个文件
2.3 模型使用
C++调用步骤:
- 加载插件
InferenceEngine::InferencePlugin,被加载的设备为InferenceEngine::PluginDispatcher - 读入压缩模型
InferenceEngine::CNNNetReader::ReadNetwork(“Model.xml”)
InferenceEngine::CNNNetReader::ReadWeights(“Model.bin”) - 指定输入输出文件
InferenceEngine::CNNNetwork::getInputsInfo()
InferenceEngine::CNNNetwork::getOutputsInfo(). - 开始工作
4.1 将模型加载到插件中:调用方法InferenceEngine::InferencePlugin::LoadNetwork(),返回InferenceEngine::ExecutableNetwork
4.2 建立请求:InferenceEngine::InferRequest::Ptr,InferenceEngine::ExecutableNetwork::CreateInferRequestPtr()
4.3 加载输入:InferenceEngine::InferRequest::getBlob(),并做图形处理
4.4 运行请求:InferenceEngine::InferRequest::Infer();或者InferenceEngine::InferRequest::StartAsync()+InferenceEngine::InferRequest::Wait()
4.5 获取输出:InferenceEngine::InferRequest::getBlob()
python调用步骤
- 加载插件
ie = IECore()
ie.add_extension(os.getenv(‘INTEL_OPENVINO_DIR’)+’/deployment_tools/inference_engine/lib/intel64/libcpu_extension.dylib’,device) - 读入模型
net = IENetwork(model= modelpath+’.xml’, weights=modelpath+’.bin’) - 指定输入输出格式
input_blob = next(iter(net.inputs))
out_blob = next(iter(net.outputs)) - 开始工作
exec_net = ie.load_network(network=net, device_name=device)
image = cv2.imread(imgpath)
res = exec_net.infer(inputs={input_blob: image})
综合如下
from openvino.inference_engine import IENetwork, IECore
model_xml = "*.xml"
model_bin = "*.bin"
device = 'CPU'
ie = IECore()
net = IENetwork(model=model_xml, weights=model_bin)
input_blob,out_blob,net.batch_size = next(iter(net.inputs)),next(iter(net.outputs)),1
n, c, h, w = net.inputs[input_blob].shape
exec_net = ie.load_network(network=net, device_name=device)
output = exec_net.infer(inputs={input_blob: cpux.numpy()})[out_blob]
output
使用opencv调用
这里要自己编译opencv包,带上WITH_INF_ENGINE=ON,然后使用dnn模块进行推断。
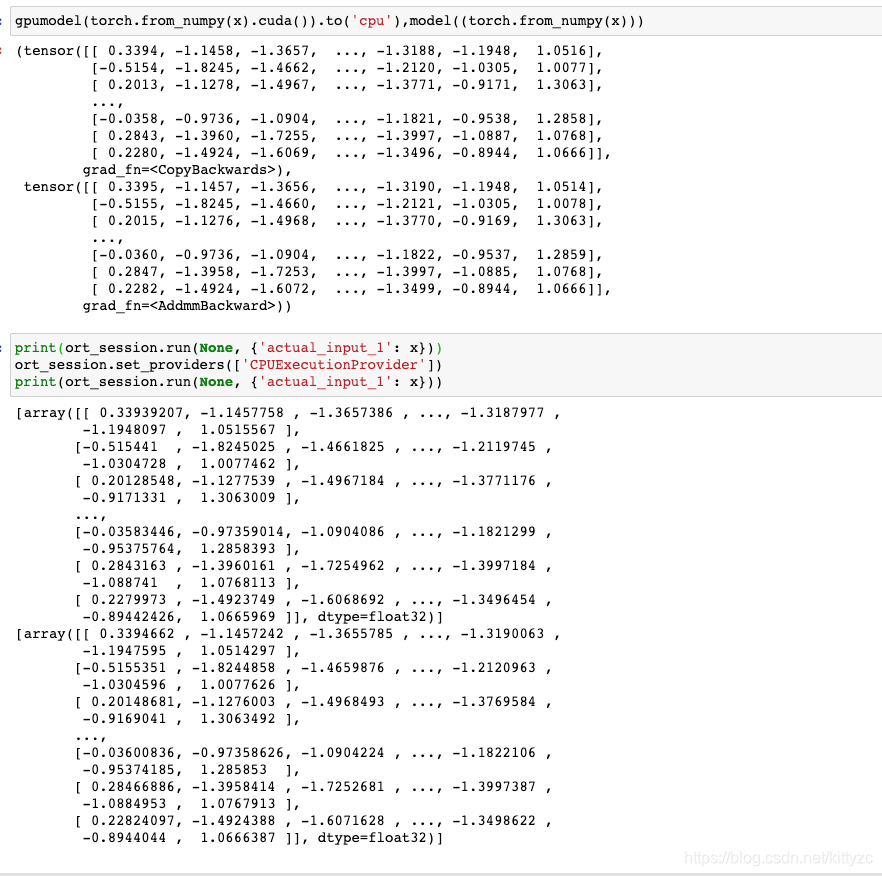
3. 性能对比
onnx的性能对比如下

onnx比原生模型稍慢一些,主要是因为数据精度问题,onnx是float32位,而原生模型是float16.
4. Open_model_zoo

4.1 face recognition
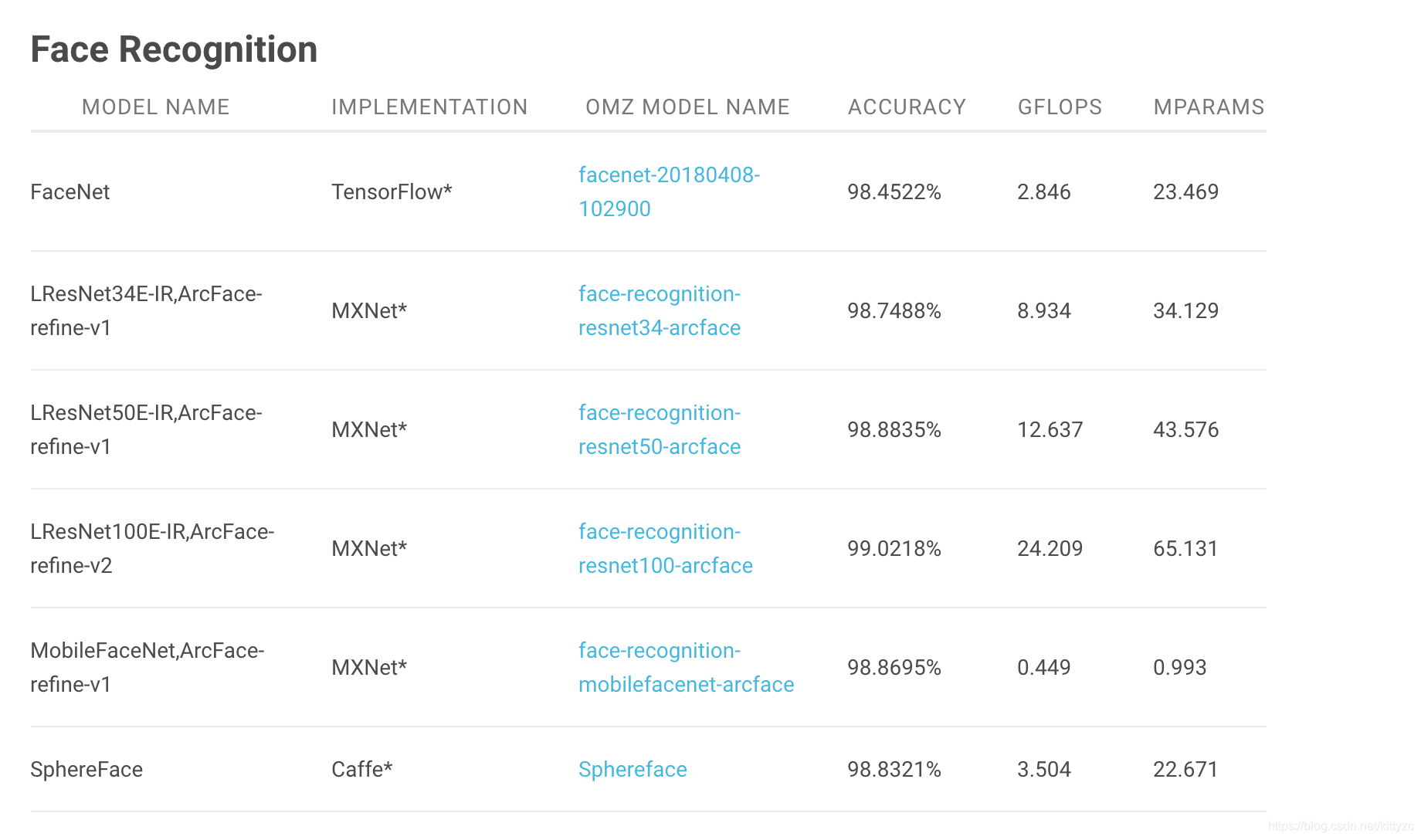
我们挑选mobilefacenet来试下
首先下载模型:
python /opt/intel/openvino/deployment_tools/open_model_zoo/tools/downloader/downloader.py --name face-recognition-mobilefacenet-arcface
然后转换模型:
python /opt/intel/openvino/deployment_tools/model_optimizer/mo_mxnet.py --input_model model-y1-test2/model-0000.params --input_shape "[1,3,112,112]"
接下来就可以快乐的使用了,速度快得飞起,在cpu上4.52 ms ± 76.4 µs per loop。
from openvino.inference_engine import IENetwork, IECore
import cv2
model_xml = "facenet/model-0000.xml"
model_bin = "facenet/model-0000.bin"
ie = IECore()
net = IENetwork(model=model_xml, weights=model_bin)
input_blob,out_blob,net.batch_size = next(iter(net.inputs)),next(iter(net.outputs)),1
n, c, h, w = net.inputs[input_blob].shape
exec_net = ie.load_network(network=net, device_name='CPU')
x = cv2.imread('1.png')
x = cv2.resize(x,(112,112)).transpose([2, 0, 1])
output = exec_net.infer(inputs={input_blob:x })[out_blob]
exec_net.infer(inputs={input_blob:x })
4.2 body ReID

首先下载模型
python /opt/intel/openvino/deployment_tools/open_model_zoo/tools/downloader/downloader.py --name person-reid*
嗯,这个是intel的模型,不需要转换,都可以直接使用,最高精度耗时,感动哭了好吗 18.1 ms ± 460 µs per loop
from openvino.inference_engine import IENetwork, IECore
import cv2
path = 'person-reidentification-retail-0270'
model_xml = path+".xml"
model_bin = path+".bin"
ie = IECore()
net = IENetwork(model=model_xml, weights=model_bin)
input_blob,out_blob,net.batch_size = next(iter(net.inputs)),next(iter(net.outputs)),1
n, c, h, w = net.inputs[input_blob].shape
exec_net = ie.load_network(network=net, device_name='CPU')
x = cv2.imread('58.jpg')
x = cv2.resize(x,(128,256)).transpose([2, 0, 1])
output = exec_net.infer(inputs={input_blob:x })[out_blob]
exec_net.infer(inputs={input_blob:x })
4.3 age/gender prediction
模型参考如下:
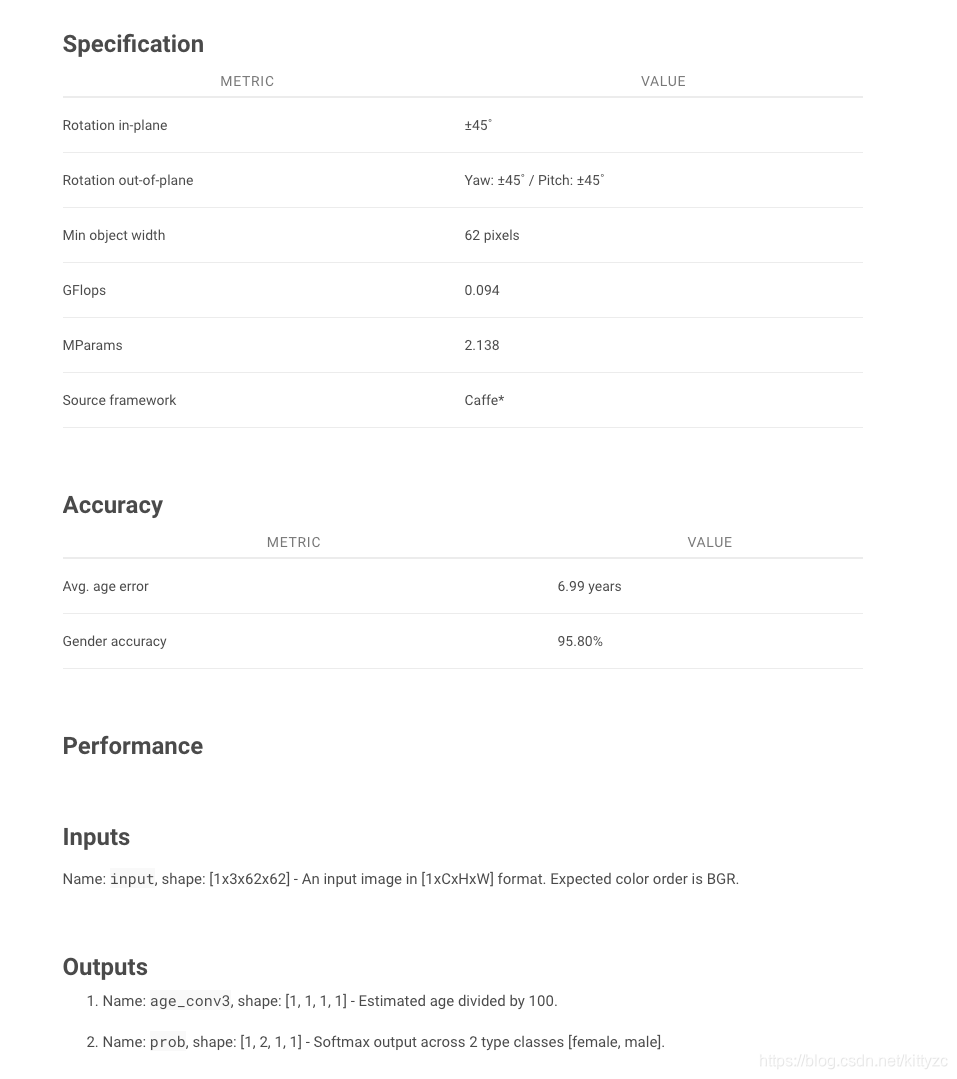
同样,首先下载模型,同样是intel自有模型,很方便,直接用。
python /opt/intel/openvino/deployment_tools/open_model_zoo/tools/downloader/downloader.py --name age-gender*
推理代码如下,速度快到发指:1.39 ms ± 5.41 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
from openvino.inference_engine import IENetwork, IECore
import cv2
path = 'work/openvino/agegender/age-gender-recognition-retail-0013'
model_xml = path+".xml"
model_bin = path+".bin"
ie = IECore()
net = IENetwork(model=model_xml, weights=model_bin)
input_blob,out_blob,net.batch_size = next(iter(net.inputs)),next(iter(net.outputs)),1
n, c, h, w = net.inputs[input_blob].shape
exec_net = ie.load_network(network=net, device_name='CPU')
x = cv2.imread('work/openvino/agegender/1.png')
x = cv2.resize(x,(62,62)).transpose([2, 0, 1])
output = exec_net.infer(inputs={input_blob:x })[out_blob]
exec_net.infer(inputs={input_blob:x })
4.4 body and face detection
body使用person-detection-0102
python /opt/intel/openvino/deployment_tools/open_model_zoo/tools/downloader/downloader.py --name person-detection*
22.7 ms ± 1.01 ms per loop,速度快的飞起,它不香么。
from openvino.inference_engine import IENetwork, IECore
import cv2
path = 'work/openvino/bodydetection/person-detection-0102'
model_xml = path+".xml"
model_bin = path+".bin"
ie = IECore()
net = IENetwork(model=model_xml, weights=model_bin)
input_blob,out_blob,net.batch_size = next(iter(net.inputs)),next(iter(net.outputs)),1
n, c, h, w = net.inputs[input_blob].shape
exec_net = ie.load_network(network=net, device_name='CPU')
x = cv2.imread('work/openvino/bodydetection/0.png')
x = cv2.resize(x,(512,512)).transpose([2, 0, 1])
output = exec_net.infer(inputs={input_blob:x })[out_blob]
res = exec_net.infer(inputs={input_blob:x })[out_blob][0][0]
b = cv2.imread('work/openvino/bodydetection/0.png')
h,w = b.shape[:2]
for r in res:
c,x1,y1,x2,y2 = r[2],r[3],r[4],r[5],r[6]
if c>0.9:
cv2.rectangle(b,(int(x1*w),int(y1*h)),(int(x2*w),int(y2*h)),(255,0,0),5)
cv2.imwrite('temp.jpg',b)
face用face-detection-0105,也是快的飞起29.9 ms ± 530 µs