文章目录
Flink on Yarn 模式的原理是依靠YARN来调度Flink 任务,目前在企业中使用较多。这种模式的好处是可以充分利用集群资源,提高集群机器的利用率,并且只需要1套Hadoop集群,就可以执行MR和Spark任务,还可以执行 Flink 任务等,操作非常方便,不需要维护多套集群,运维方面也很轻松。Flink on Yarn 模式需要依赖 Hadoop 集群,并且Hadoop的版本需要是 2.2 及以上。
一、部署
1.1、参考Standalone部署
1.2、由于虚拟机的内存有限,所以需要修改资源配置
taskmanager.memory.process.size: 512m
taskmanager.memory.framework.heap.size: 64m
taskmanager.memory.framework.off-heap.size: 64m
taskmanager.memory.jvm-metaspace.size: 64m
taskmanager.memory.jvm-overhead.fraction: 0.2
taskmanager.memory.jvm-overhead.min: 16m
taskmanager.memory.jvm-overhead.max: 64m
taskmanager.memory.network.fraction: 0.1
taskmanager.memory.network.min: 1mb
1.3、复制Hadoop的jar包到Flink的lib目录
根据你需要的hadoop版本

二、Flink On Yarn的运行架构
2.1、Flink On Yarn 的内部实现原理: 任务提交流程

- 当启动一个新的 Flink YARN Client 会话时,客户端首先会检查所请求的资源(容器和内存)是否可用。之后,它会上传Flink 配置和 JAR 文件到 HDFS。
- 客 户 端 的 下 一 步 是 请 求 一 个 YARN 容 器 启 动 ApplicationMaster 。 JobManager 和ApplicationMaster(AM)运行在同一个容器中,一旦它们成功地启动了,AM 就能够知道JobManager 的地址,它会为 TaskManager 生成一个新的 Flink 配置文件(这样它才能连上 JobManager),该文件也同样会被上传到 HDFS。另外,AM 容器还提供了 Flink 的Web 界面服务。Flink 用来提供服务的端口是由用户和应用程序 ID 作为偏移配置的,这使得用户能够并行执行多个 YARN 会话。
- 之后,AM 开始为 Flink 的 TaskManager 分配容器(Container),从 HDFS 下载 JAR 文件和修改过的配置文件。一旦这些步骤完成了,Flink 就安装完成并准备接受任务了。
2.2、任务调度原理

三、Session-Cluster模式(yarn-session)
Session-Cluster:是在 YARN 中提前初始化一个 Flink集群(称为Flink yarn-session),开辟指定的资源,以后的 Flink 任务都提交到这里。这个Flink 集群会常驻在YARN 集群中,除非手工停止。这种方式创建的 Flink 集群会独占资源,不管有没有 Flink 任务在执行,YARN 上面的其他任务都无法使用这些资源。

3.1、启动yarn-session集群
3.1.1、启动hadoop集群, 通过命令气筒一个Flink集群
./bin/yarn-session.sh -n 1 -s 1 -nm chbFlink
其中 yarn-session.sh 后面支持多个参数。下面针对一些常见的参数进行讲解:
- -n,–container 表示分配容器的数量(也就是 TaskManager 的数量)。
- -D 动态属性。
- -d,–detached 在后台独立运行。
- -jm,–jobManagerMemory :设置 JobManager 的内存,单位是 MB。
- -nm,–name:在 YARN 上为一个自定义的应用设置一个名字。
- -q,–query:显示 YARN 中可用的资源(内存、cpu 核数)。
- -qu,–queue :指定 YARN 队列。
- -s,–slots :每个 TaskManager 使用的 Slot 数量。
- -tm,–taskManagerMemory :每个 TaskManager 的内存,单位是 MB。
- -z,–zookeeperNamespace :针对 HA 模式在 ZooKeeper 上创建 NameSpace。
- -id,–applicationId :指定 YARN 集群上的任务 ID,附着到一个后台独立运行的yarn session中。
3.2、查看WebUI
3.2.1、ResourceManager UI

3.2.2、Flink Web UI
点击ApplicationMaster , 可以发现跳到Flink Web UI上, 此时还没有提交Job,所以没人任务

3.2.3、注意查看本地文件系统中有一个临时文件。有了这个文件可以提交 job 到 Yarn
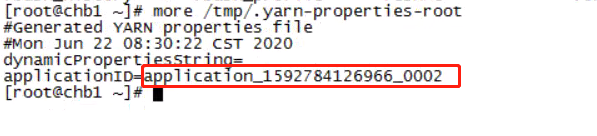
3.2.4、提交Job
由于有了之前的配置,所以自动会提交到 Yarn 中。

提交的任务

3.2.4、停止yarn-session集群
yarn app -kill applicationId
四、Pre-Job-Cluster模式(yarn-cluster)
Per-Job-Cluster):每次提交 Flink 任务都会创建一个新的 Flink 集群,每个 Flink 任务之间相互独立、互不影响,管理方便。任务执行完成之后创建的Flink集群也会消失,不会额外占用资源,按需使用,这使资源利用率达到最大,在工作中推荐使用这种模式。

这种模式不再需要yarn-session,
3.1、启动一个Cluster模式集群
./bin/flink run -m yarn -cluster -ys 1 ymn chbFlink2 -c com.chb.flink2.StreamWrodCount /uardata1/FlinkProject-1.0.jar

3.2、从ResourceManager UI查看
