先看下官网对Flink 各个组件的描述:https://ci.apache.org/projects/flink/flink-docs-release-1.10/concepts/runtime.html#job-managers-task-managers-clients
启动流程。
Flink 的 checkpoint 可以保证任务在遇到异常的时候,可以自动从上一个checkpoint 的状态恢复,保障任务的正常的运行,这应该是大家都知道的事情。
上面的异常,指的是执行计算任务的 taskmanager 的异常,如果是jobmanager 遇到异常是不能自动恢复的。(因为需要恢复的元数据、执行图、各种端口、路径都是jobmanager 管理的,jobmanager 死了,就都没有了)
下面内容来自官网:https://ci.apache.org/projects/flink/flink-docs-release-1.10/ops/jobmanager_high_availability.html
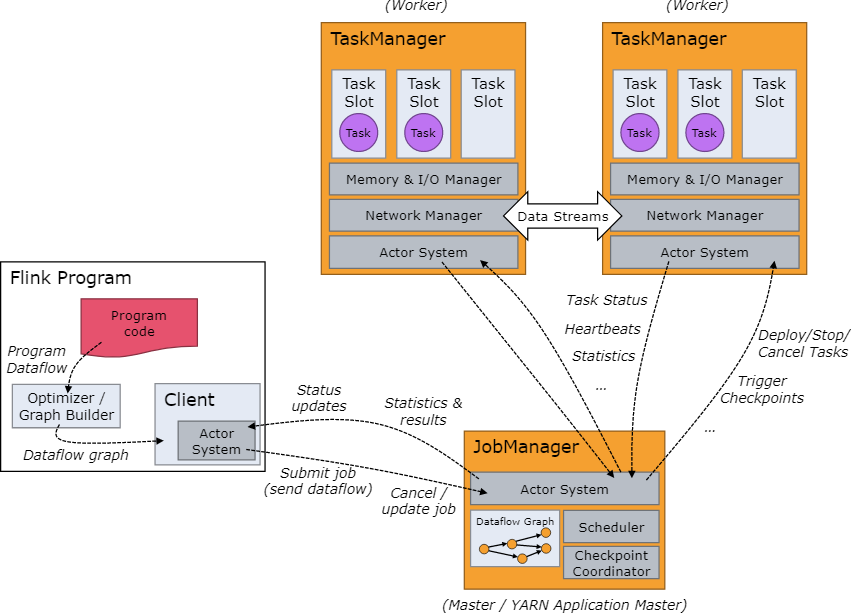
JobManager协调每个Flink部署。它既负责调度又负责资源管理。
默认情况下,每个Flink集群只有一个JobManager实例。这将创建一个单点故障(SPOF):如果JobManager崩溃,则无法提交任何新程序,并且正在运行的程序也会失败。
使用JobManager高可用性,您可以从JobManager故障中恢复,从而消除SPOF。您可以为独立群集和YARN群集配置高可用性。
在运行高可用的YARN群集时,我们不会运行多个JobManager(ApplicationMaster)实例,而只能运行一个实例,当实例出现故障时,YARN会重新启动该实例。 确切的行为取决于您使用的特定YARN版本。
配置 yarn-site.xml
<property>
<name>yarn.resourcemanager.am.max-attempts</name>
<value>4</value>
<description>
The maximum number of application master execution attempts.
</description>
</property>
注:重试次数最大为 4次,默认为 2(允许单个jobmanager的故障)
不同的hadoop版本上,yarn container 有不同的异常恢复行为:
- YARN 2.3.0 < version < 2.4.0:所以container重启
- YARN 2.4.0 < version < 2.6.0:master的container挂了,taskmanager的container可以继续执行;恢复更快
- YARN 2.6.0 <= version:根据Flink配置,只有任务在一定时间内连续尝试了一定次数才会被kill。
flink-conf.yaml 配置:
high-availability: zookeeper high-availability.zookeeper.quorum: localhost:2181 high-availability.storageDir: hdfs:///flink/recovery high-availability.zookeeper.path.root: /flink yarn.application-attempts: 10
具体配置就这样的,官网都有描述。
关于测试,我起了下面这么一个简单的任务:读kafka,写kafka

测试内容是:在有无 checkpoint、有无 HA 的情况下 kill taskmanager 和 jobmanager
测试用例和测试结果如下:
1、无checkpoint kill taskmanager : 直接挂掉 2、有checkpoint 1、先不配置HA kill taskmanager : 1 次:回退上一次checkpoint, taskmanager 迁移,jobmanager 不迁移 (可配置精确一次) 2 次:回退上一次checkpoint, taskmanager 迁移,jobmanager 不迁移 3 次: kill jobmanager : 1 次: 直接挂掉 2、配置HA kill taskmanager : 1 次:回退上一次checkpoint, taskmanager 迁移,jobmanager 不迁移 2 次:回退上一次checkpoint, taskmanager 迁移,jobmanager 不迁移 kill jobmanager : 1 次:taskmanager 正常写数据,webui 短时不能访问,jobmanager 恢复后,会迁移,tm 会从checkpoint 恢复一次 2 次:taskmanager 正常写数据,webui 短时不能访问,jobmanager 恢复后,会迁移,tm 会从checkpoint 恢复一次 3 次:同上 taskmanager kill 次数: 10 任务运行正常 jobmanager kill 次数: 10 任务运行正常 # yarn 和 flink 的重试次数都是短时间内的尝试,如果任务已经正常了,基本就重新计数了
搞定
关于checkpoint 重启,精确一次的测试,可以参考下一篇 Flink kafka connector 端到端精确一次测试 (还没写,写了回来更新)
欢迎关注Flink菜鸟公众号,会不定期更新Flink(开发技术)相关的推文
