1. 简介
Flink on Yarn模式的原理是依靠Yarn来调度Flink任务,这种模式可以充分的利用集群资源,提高集群机器的利用率。Flink on Yarn模式主要分为如下两种:
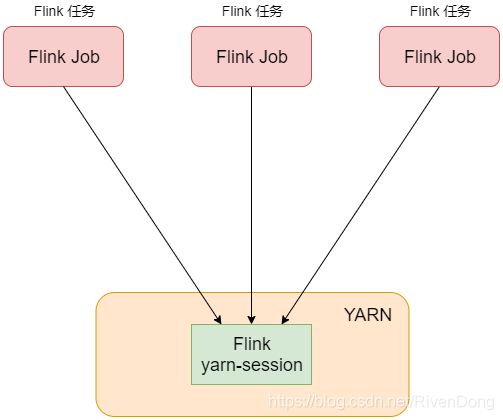
- 第1种模式:在Yarn中提前初始化一个Flink集群(称为Flink yarn-session),开辟指定的资源,以后的Flink任务都提交到这里。这个Flink集群会常驻在Yarn集群中,除非手动停止。这种方式创建的Flink集群会独占资源,不管有没有Flink任务在执行,Yarn上面的其他任务都无法使用这些资源。
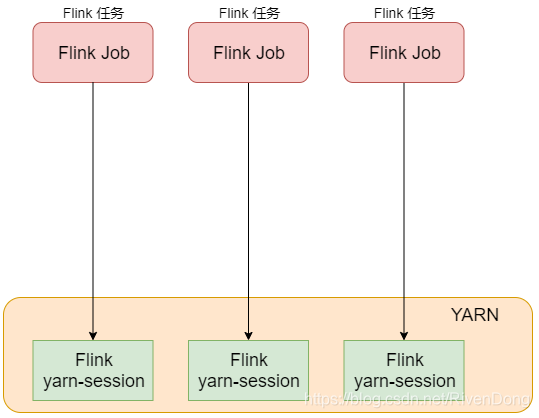
- 第2种模式:每次提交Flink任务都会创建一个新的Flink集群,每个Flink任务之间相互独立、互不影响。任务执行完成之后创建的Flink集群也会消失,不会额外占用资源,按需使用,这使资源利用率达到最大。
2. 基于Yarn的集群部署
2.1 第1种模式
- 创建一个一直运行着的Flink集群(也可以称为Flink yarn-session)
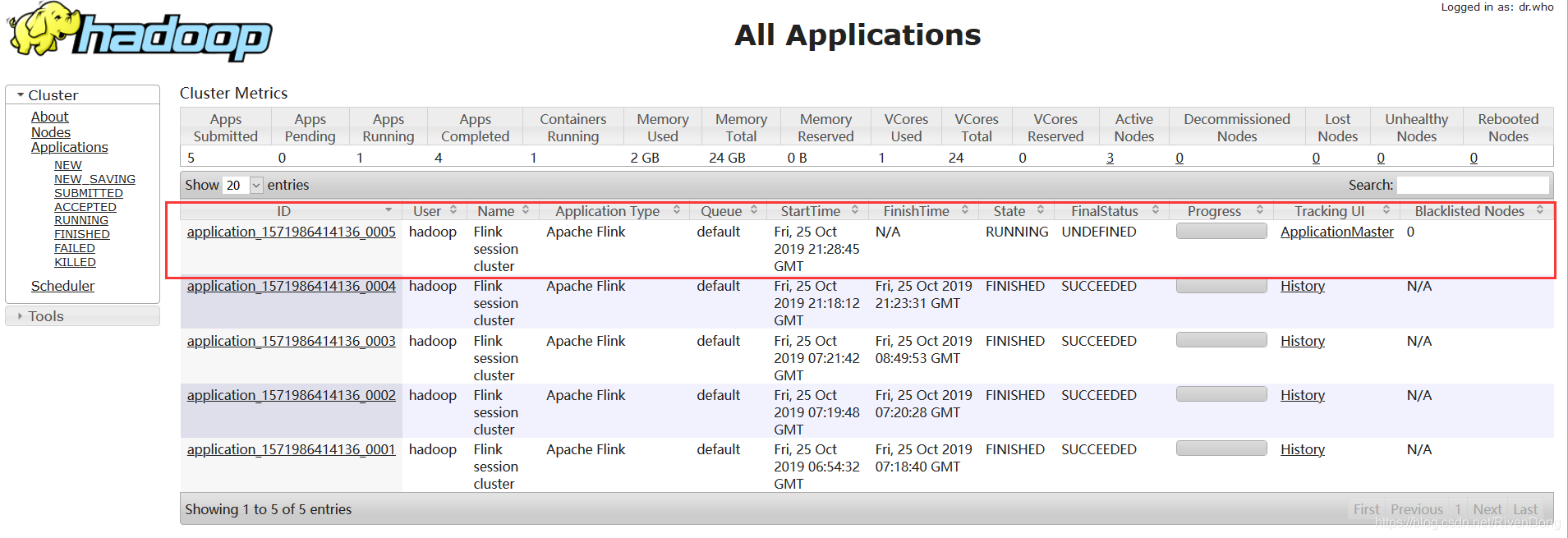
./yarn-session.sh -n 3
执行此命令后,可以通过访问:master:8088,打开任务界面确认是否有Flink任务成功运行:
也可以附着到一个已存在的Flink集群中:
./yarn-session.sh -id applicationId
通过点击ApplicationMaster可以进入到Flink的管理界面:
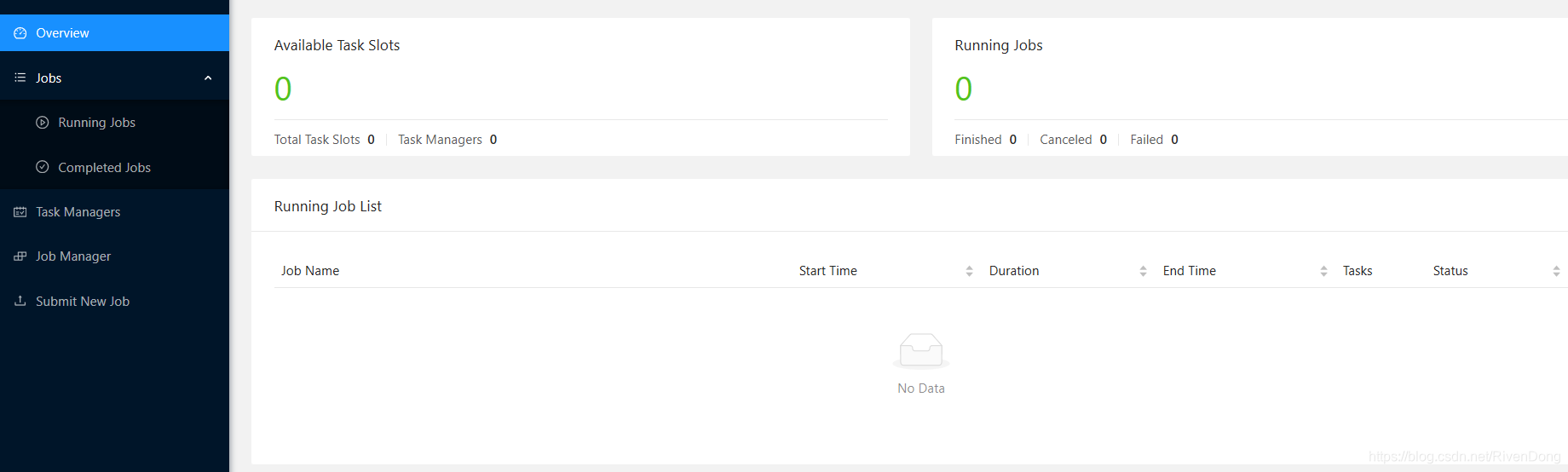
可以看到此时Available Task Slots为0,下面通过该集群执行Flink任务:
./flink run ../examples/batch/WordCount.jar
此时 Available Task Slots 变为了8个:

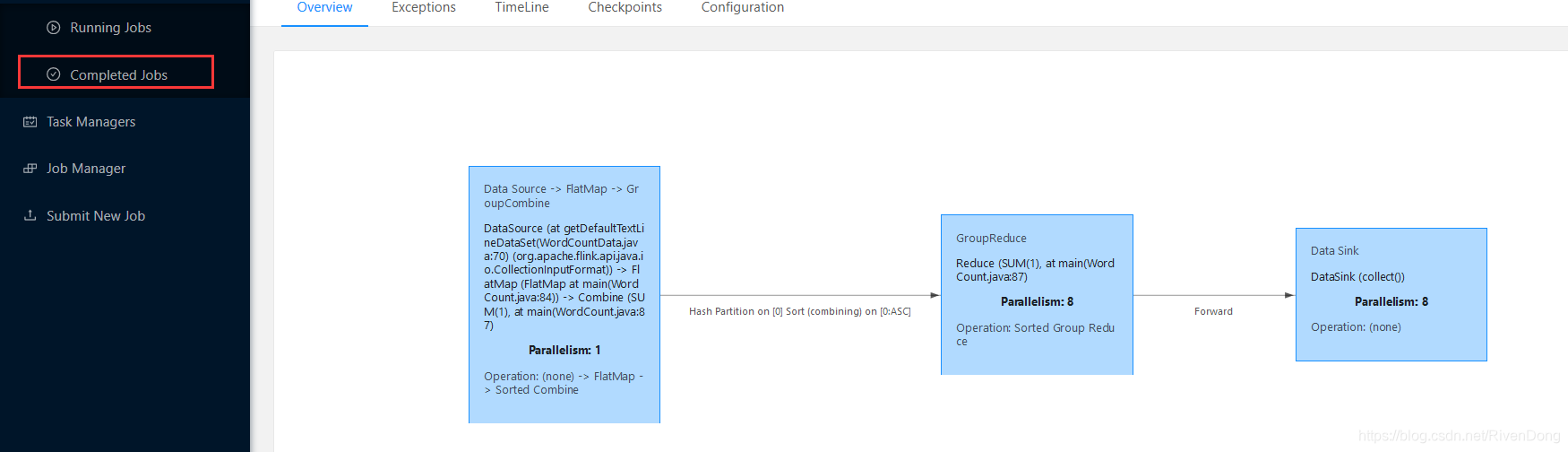
可以在这里看到任务已完成
2.2 第2种模式
提交Flink任务的同时创建Flink集群
./flink run -m yarn-cluster ../examples/batch/WordCount.jar
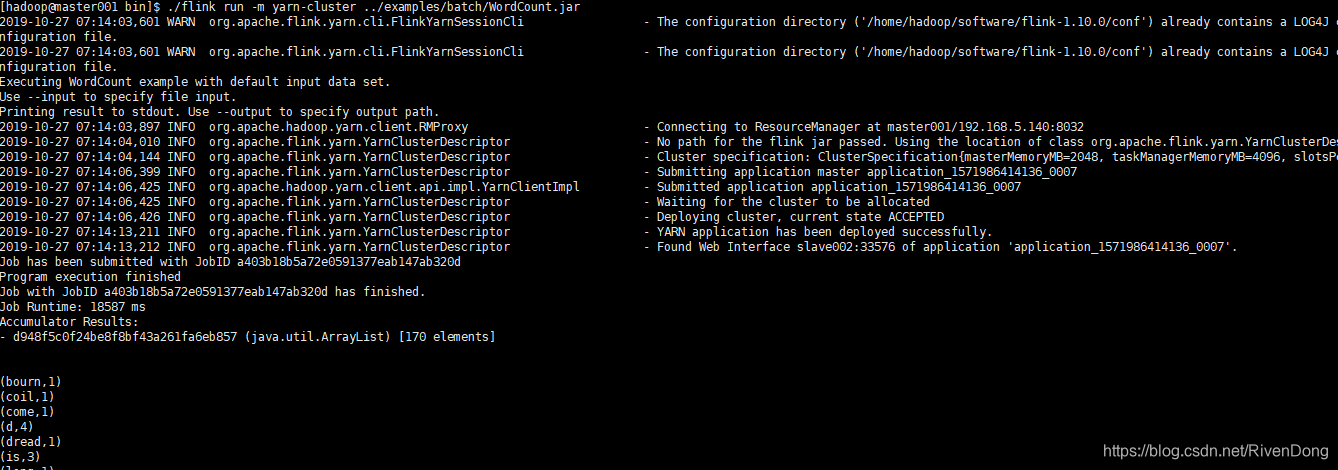
可以通过地址http://master001:8088/cluster,发现yarn集群运行完后就接着退出了。
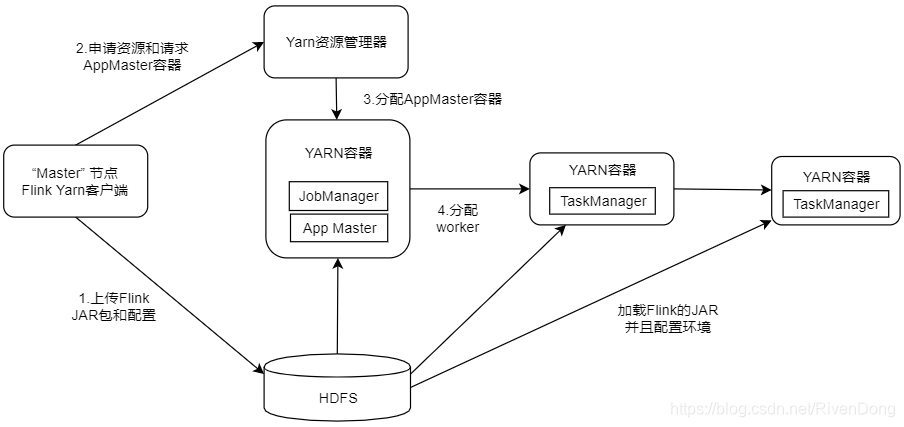
3. Flink on Yarn内部实现
当启动一个新的Flink Yarn Client会话时,客户端首先会检查所请求的资源(容器和内存)是否可用。之后,它会上传Flink配置和JAR文件到HDFS。客户端的下一步是请求一个YARN容器启动ApplicationMaster。JobManager和ApplicationMaster运行在同一个容器中,一旦它们成功地启动了,AM就能够知道JobManager的地址,他会为TaskManager生成一个新的Flink配置文件(这样才能够连上JobManager),该文件也同样会被上传到HDFS。另外,AM容器还提供了Flink的Web界面服务。Flink用来提供服务的端口是由用户和应用程序ID作为偏移配置的,这使得用户能够并行执行多个YARN会话。之后,AM开始为Flink的TaskManager分配容器,从HDFS下载JAR文件和修改过的配置文件。一旦这些步骤完成了,Flink就安装完成并准备接受任务了。