我就是单纯的保留一份,晚点自己好看,不是原创,切勿上纲上线。
随着物联网lOT的到来,万物连接一切,使得各大企业的数据也会井喷的增加。传统的大数据处理架构已经无法满足当前企业的发展,这个时候流式架构的出现,让企业的数据能够在较短的时间内处理快速响应迭代,满足企业各种场景下的不同需求。Flink的到来,很好的解决了这种问题。Flink是一个高性能,高吞吐,低延迟的流处理框架。它不仅仅是作为一个流式处理框架,更将批处理统一了起来(在Flink种,批处理是流处理的一种特例)。Flink的这种架构,也更好的解决了传统大数据架构那种繁琐的组件堆积,让批流能够在不改变原有代码的基础上,进行批处理或者流处理。实现了Flink支持多种部署方式local,standalone,yarn以及k8s,现在大多数企业因为大数据平台都以yarn作为资源管理器,所以为了方便管理,很多企业选择了Flink on yarn这种模式。当然随着容器云火热,不少企业选择K8S作为大数据平台的整个资源管理器,这个时候可以选择将Flink部署到K8S之上。下面重点介绍现阶段Flink on yarn在企业中的应用。
本文主要分5块内容讲解
-
Flink解压安装;
-
Flink作业提交介绍;
-
Flink yarn session的部署;
-
Flink run 方式提交;
-
Flink HA部署;
下面我们将按照以上的5个部分分别讲解Flink on yarn的应用部署。
一.Flink解压安装
本次讲解选择了当前最新版本Flink-1.6.0,hadoop版本根据自己的需求选择即可,假定现在已经安装好了Hadoop,我的Hadoop版本是2.7.4,并且主从节点是1个master,2个slaves。

1.软件下载地址:
https://flink.apache.org/downloads.html
2.解压安装
[root@cdh1 soft]# tar -zxvf flink-1.5.3-bin-hadoop27-scala_2.11.tgz -C /usr/local/
3.将Flink安装分发到各个节点
[root@cdh1 local]# scp -r flink-1.6.0 root@cdh2:/usr/local/
注明: cdh3分发和cdh2的分发是一样的步骤。
二.Flink 作业提交介绍
因Flink强大的灵活性及开箱即用的原则, 因此提交作业分为2种情况:
-
yarn seesion
-
Flink run
这2者对于现有大数据平台资源使用率有着很大的区别:
-
第一种yarn seesion(Start a long-running Flink cluster on YARN)这种方式需要先启动集群,然后在提交作业,接着会向yarn申请一块空间后,资源永远保持不变。如果资源满了,下一个作业就无法提交,只能等到yarn中的其中一个作业执行完成后,释放了资源,那下一个作业才会正常提交.
-
第二种Flink run直接在YARN上提交运行Flink作业(Run a Flink job on YARN),这种方式的好处是一个任务会对应一个job,即没提交一个作业会根据自身的情况,向yarn申请资源,直到作业执行完成,并不会影响下一个作业的正常运行,除非是yarn上面没有任何资源的情况下。
综合以上这2种的示意图如下:

注意事项:如果是平时的本地测试或者开发,可以采用第一种方案;如果是生产环境推荐使用第二种方案;
Flink on yarn模式部署时,不需要对Flink做任何修改配置,只需要将其解压传输到各个节点之上。但如果要实现高可用的方案,这个时候就需要到Flink相应的配置修改参数,具体的配置文件是FLINK_HOME/conf/flink-conf.yaml。高可用HA参数配置会在讲解HA部署的时候具体说明怎么配置;
对于Flink on yarn模式,我们并不需要在conf配置下配置 masters和slaves。因为在指定TM的时候可以通过参数“-n”来标识需要启动几个TM;Flink on yarn启动后,如果是在分离式模式你会发现,在所有的节点只会出现一个 YarnSessionClusterEntrypoint进程;如果是客户端模式会出现2个进程一个YarnSessionClusterEntrypoint和一个FlinkYarnSessionCli进程。
三.Flink yarn session部署
用yarn session在启动集群时,有2种方式可以进行集群启动分别是:
-
客户端模式;
-
分离式模式;
客户端模式
对于客户端模式,启动方式:
bin/yarn-session.sh -n 2 -jm 1024 -tm 4096 -s 6
对于客户端模式进程如下图:
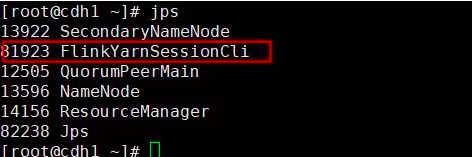
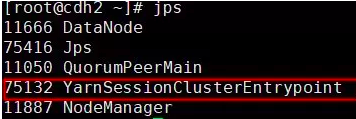
对于客户端模式而言,你可以启动多个yarn session,一个yarn session模式对应一个JobManager,并按照需求提交作业,同一个Session中可以提交多个Flink作业。如果想要停止Flink Yarn Application,需要通过yarn application -kill命令来停止
分离式模式
对于分离式模式,并不像客户端那样可以启动多个yarn session,如果启动多个,会出现下面的session一直处在等待状态。JobManager的个数只能是一个,同一个Session中可以提交多个Flink作业。如果想要停止Flink Yarn Application,需要通过yarn application -kill命令来停止。通过-d指定分离模式,即客户端在启动Flink Yarn Session后,就不再属于Yarn Cluster的一部分。分离式模式进程如下:

综上,可以看到客户端模式和分离式模式的区别,除了进程外,其他都一样。
作业提交
以上不管采用客户端模式还是分离式模式,提交作业都是一样的。下面以Flink目录下的LICENSE为例,计算WordCount将处理后的数据放到HDFS。
数据准备
首先上传数据到HDFS
[root@cdh1 flink-1.6.0]# hadoop fs -mkdir /user/root/test
[root@cdh1 flink-1.6.0]# hadoop fs -put LICENSE /user/root/test
提交作业并查看结果
[root@cdh1 flink-1.6.0]# bin/flink run ./examples/batch/WordCount.jar --input hdfs://192.168.44.135:9000/user/root/test/LICENSE --output hdfs://192.168.44.135:9000/user/root/test/result.txt
[root@cdh1 flink-1.6.0]# hadoop fs -cat /user/root/test/result.txt
对于Flink on yarn作业提交后,若要在Flink WEB UI上查看作业的额详细可以通过如下操作进入:
Flink WEB UI
参数介绍
yarn-session的参数介绍
-n : 指定TaskManager的数量;
-d: 以分离模式运行;
-id:指定yarn的任务ID;
-j:Flink jar文件的路径;
-jm:JobManager容器的内存(默认值:MB);
-nl:为YARN应用程序指定YARN节点标签;
-nm:在YARN上为应用程序设置自定义名称;
-q:显示可用的YARN资源(内存,内核);
-qu:指定YARN队列;
-s:指定TaskManager中slot的数量;
-st:以流模式启动Flink;
-tm:每个TaskManager容器的内存(默认值:MB);
-z:命名空间,用于为高可用性模式创建Zookeeper子路径;
四.Flink run 方式提交
对于前面介绍的yarn session需要先启动一个集群,然后在提交作业。对于Flink run直接提交作业就相对比较简单,不需要额外的去启动一个集群,直接提交作业,即可完成Flink作业。
启动作业
[root@cdh1 flink-1.6.0]#bin/flink run -m yarn-cluster -d -yn 2 -yjm 2048 -ytm 5120 ./examples/batch/WordCount.jar --input hdfs://192.168.44.135:9000/user/root/test/LICENSE --output hdfs://192.168.44.135:9000/user/root/test/result.txt
[root@cdh1 flink-1.6.0]#hadoop fs -cat /user/root/test/results.txt

flink run参数介绍:
-c:如果没有在jar包中指定入口类,则需要在这里通过这个参数指定;
-m:指定需要连接的jobmanager(主节点)地址,使用这个参数可以指定一个不同于配置文件中的jobmanager,可以说是yarn集群名称;
-p:指定程序的并行度。可以覆盖配置文件中的默认值;
-n:允许跳过保存点状态无法恢复。 你需要允许如果您从中删除了一个运算符你的程序是的一部分保存点时的程序触发;
-q:如果存在,则禁止将日志记录输出标准出来;
-s:保存点的路径以还原作业来自(例如hdfs:///flink/savepoint-1537);
还有参数如果在yarn-session当中没有指定,可以在yarn-session参数的基础上前面加“y”,即可控制所有的资源,这里就不獒述了。
五.Flink HA部署
Flink 高可用HA参数配置
Flink on yarn 高可用HA参数配置可以参考官方文档。
在Flink on yarn 下对于HA相对来说,是非常容易的,它的实现是通过YArn来完成的。如果某个节点YarnSessionClusterEntrypoint死了或者是宕机了。这个时候Attempt ID会自动切换,保证了Flink故障转移,并从xxxxxx__000001变为xxxxxx_000002。对于高可用的数据目录是如果存放的呢?现在一般是HDFS作为HA的共享存储目录,但你也可以选择其他的系统作为HA的共享目录。
注意:Flink On Yarn环境中,当Jobmanager(Application Master)失败时,yarn会尝试重启JobManager(AM),重启后,会重新启动Flink的Job(application)。因此,yarn.application-attempts的设置不应该超过yarn.resourcemanager.am.max-attemps。
Flink on yarn HA配置时,如果出现问题了,需要用到zookeeper作为协调锁,即用到其中的选举机制来做到HA的自动故障切换,具体操作步骤如下。
Flink参数配置
如果你已经安装了zookeeper,无需在Flink中配置相应的zookeeper信息,只需要保证正常启动即可。接下来在flink-conf.yaml中配置高可用HA的相关信息。
| [root@cdh1 conf]# vim flink-conf.yaml taskmanager.heap.mb: 3072 taskmanager.numberOfTaskSlots: 4 #parallelism.default: 2 taskmanager.tmp.dirs: /tmp #jobmanager.heap.mb: 1024 #jobmanager.web.port: 8081 #jobmanager.rpc.port: 6123 yarn.application-attempts: 8 env.java.home: /usr/java/jdk1.8.0_111 high-availability: zookeeper high-availability.zookeeper.quorum: cdh1:2181,cdh2:2181,cdh3:2181 high-availability.storageDir: hdfs://cdh1:9000/flink/recovery high-availability.zookeeper.path.root: /flink state.backend: filesystem state.backend.fs.checkpointdir: hdfs://cdh1:9000/flink/checkpoints taskmanager.network.numberOfBuffers: 1024 fs.hdfs.hadoopconf: /usr/local/hadoop-2.7.4/etc/hadoop |
配置hadoop(yarn-site.xml)
此配置需要在$HADOOP_CONF_DIR 的yarn-site.xml添加
`[root@h001 ~]# cd /usr/bigdata/hadoop/etc/hadoop/
[root@h001 hadoop]# vim yarn-site.xml
<property>
<name>yarn.resourcemanager.am.max-attempts</name>
<value>4</value>
</property>`
此配置代表application master在重启时,尝试的最大次数
注意,Flink On Yarn环境中,当Jobmanager(Application Master)失败时,yarn会尝试重启JobManager(AM),重启后,会重新启动Flink的Job(application)。因此,yarn.application-attempts的设置不应该超过yarn.resourcemanager.am.max-attemps。以上的2个配置文件都需要分发到各个节点。
Flink HA测试
这里假设我已经启动了Flink集群,那么首先我先杀死进程
如图看到Attempt ID由000001变为000002,示进程也有所变化,,说明HA切换成功了。
