一、损失函数概念
损失函数:衡量模型输出与真实标签的差异
class _Loss(Module):
def __init__(self, size_average=None, reduce=None,
reduction='mean'):
super(_Loss, self).__init__()
if size_average is not None or reduce is not None:
self.reduction = _Reduction.legacy_get_string(size_average, reduce)
else:
self.reduction = reduction损失函数(Loss Function):Loss=f(y',y)
代价函数(Cost Function):

目标函数(Objective Function):Obj = Cost + Regularization
二、具体代码
1、nn.CrossEntropyLoss,功能: nn.LogSoftmax()与nn.NLLLoss()结合,进行
nn.CrossEntropyLoss(weight=None,size_average=None,ignore_index=-100,reduce=None,reduction=‘mean’‘)主要参数:
• weight:各类别的loss设置权值
• ignore_index:忽略某个类别
• reduction :计算模式,可为none/sum/mean,none- 逐个元素计算,sum- 所有元素求和,返回标量,mean- 加权平均,返回标量
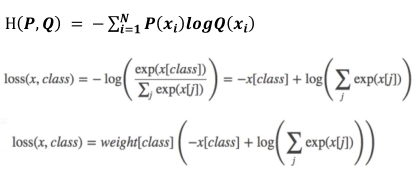
2、 nn.NLLLoss,功能:实现负对数似然函数中的负号功能
nn.NLLLoss(weight=None,size_average=None,ignore_index=-100,reduce=None,reduction='mean')
主要参数:
• weight:各类别的loss设置权值
• ignore_index:忽略某个类别
• reduction :计算模式,可为none/sum/mean,none- 逐个元素计算,sum- 所有元素求和,返回标量,mean- 加权平均,返回标量
3、 nn.BCELoss,功能:二分类交叉熵,输入值取值在[0,1]
nn.BCELoss(weight=None,size_average=None,reduce=None,reduction='mean’)
主要参数:
• weight:各类别的loss设置权值
• ignore_index:忽略某个类别
• reduction :计算模式,可为none/sum/mean,none- 逐个元素计算,sum- 所有元素求和,返回标量,mean- 加权平均,返回标量
4、 nn.BCEWithLogitsLoss,功能:结合Sigmoid与二分类交叉熵
nn.BCEWithLogitsLoss(weight=None,size_average=None,reduce=None, reduction='mean',
pos_weight=None)![]()
主要参数:
• pos_weight :正样本的权值
• weight:各类别的loss设置权值
• ignore_index:忽略某个类别
• reduction :计算模式,可为none/sum/mean,none-逐个元素计算,sum-所有元素求和,返回标量,mean-加权平均,返回标量
注意:网络最后不加sigmoid函数
5、nn.L1Loss,功能: 计算inputs与target之差的绝对值

6、nn.MSELoss,功能: 计算inputs与target之差的平方

主要参数:
• reduction :计算模式,可为none/sum/mean,none- 逐个元素计算,sum- 所有元素求和,返回标量,mean- 加权平均,返回标量
7、SmoothL1Loss


8、PoissonNLLLoss,功能:泊松分布的负对数似然损失函数

主要参数:
• log_input :输入是否为对数形式,决定计算公式
• full :计算所有loss,默认为False
• eps :修正项,避免log(input)为nan
9、nn.KLDivLoss功能:计算KLD(divergence),KL散度,相对熵
注意事项:需提前将输入计算 log-probabilities,如通过nn.logsoftmax()

主要参数:
• reduction :none/sum/mean/batchmean,none- 逐个元素计算
10、nn.MarginRankingLoss,功能:计算两个向量之间的相似度,用于排序任务
该方法计算两组数据之间的差异,返回一个n*n的 loss 矩阵。y = 1时, 希望x1比x2大,当x1>x2时,不产生loss;y = -1时,希望x2比x1大,当x2>x1时,不产生loss。

主要参数:
• margin :边界值,x1与x2之间的差异值
• reduction :计算模式,可为none/sum/mean
11、nn.MultiLabelMarginLoss
12、 nn.SoftMarginLoss,功能:计算二分类的logistic损失

主要参数:
• reduction :计算模式,可为none/sum/mean
13、nn.MultiLabelSoftMarginLoss,功能:SoftMarginLoss多标签版本

nn.MultiLabelSoftMarginLoss(weight=None,size_average=None, reduce=None, reduction='mean')主要参数:
• weight:各类别的loss设置权值
• reduction :计算模式,可为none/sum/mean
14、nn.MultiMarginLoss,功能:计算多分类的折页损失

nn.MultiMarginLoss(p=1, margin=1.0, weight=None,size_average=None, reduce=None,reduction='mean')主要参数:
• p :可选1或2
• weight:各类别的loss设置权值
• margin :边界值
• reduction :计算模式,可为none/sum/mean
15、nn.TripletMarginLoss,计算三元组损失,人脸验证中常用


nn.TripletMarginLoss(margin=1.0, p=2.0, eps=1e-06,swap=False, size_average=None,reduce=None,reduction='mean') 主要参数:
• p :范数的阶,默认为2
• margin :边界值
• reduction :计算模式,可为none/sum/mean
16、 nn.HingeEmbeddingLoss,功能:计算两个输入的相似性,常用于非线性embedding和半监督学习

nn.HingeEmbeddingLoss(margin=1.0, size_average=None,reduce=None, reduction='mean’) 主要参数:
• margin :边界值
• reduction :计算模式,可为none/sum/mean
特别注意:输入x应为两个输入之差的绝对值
17、nn.CosineEmbeddingLoss,功能:采用余弦相似度计算两个输入的相似性

nn.CosineEmbeddingLoss(margin=0.0, size_average=None,reduce=None, reduction='mean')主要参数:
• margin :可取值[-1, 1] , 推荐为[0, 0.5]
• reduction :计算模式,可为none/sum/mean
18、nn.CTCLoss,功能: 计算CTC损失,解决时序类数据的分类
torch.nn.CTCLoss( blank=0 , reduction='mean' , zero_infinity=False)主要参数:
• blank :blank label
• zero_infinity :无穷大的值或梯度置0
• reduction :计算模式,可为none/sum/mean