adaboost是典型的boosting算法。
核心思想
boosting算法的核心思想是:上一个模型对单个样本预测的结果越差,下个模型越重视这个样本(增大该样本的权重,加大模型预测错的成本)。提升树就是每个模型都是决策树,提升树种效果比较好的是GBDT和XGBOOST,入门是adaboost。adaboost的损失函数是指数函数。
训练过程(分类)
adaboost模型的训练过程可以简单的分为这几步:
1.更新样本权重。
2.训练模型。
3.计算误差。
4.计算该模型的投票权重。back to step1
SAMME算法具体说明:
1.初始化样本权重,所有样本权重一致,1/N。
2.用所有样本进行第一个模型的训练。
3.用训练集数据对该模型进行评估,得到一个评估结果(下面公式以分类误差率为例)
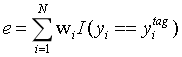
4.计算该模型的投票权重。
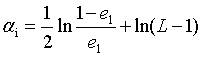
其中L是类别数量。
return to 1:更新样本权重
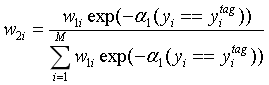
final:adaboost会选择所有模型计算的结果中,权重和最大的类别(回归则是加权和)。
notice:若单模型的分类准确率小于0.5,则该模型的权重会是负值,开心不。
SAMME.R算法具体说明
1.更新样本权重。
2.训练模型,模型需要返回各个类别的概率。
3.计算该模型对各个类别的加权权重。
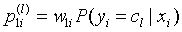
4.计算该模型对该样本分类为各个类别的话语权。
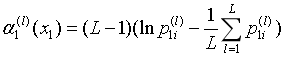
5.更新样本的权重。
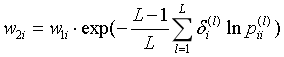
其中,
样本权重再归一化就OK了。
最终,分类结果是权重最大的类别。