RandomForestRegressor
class sklearn.ensemble.RandomForestRegressor (n_estimators=’warn’, criterion=’mse’, max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=’auto’, max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, bootstrap=True, oob_score=False, n_jobs=None, random_state=None, verbose=0, warm_start=False)
from sklearn.datasets import load_boston #标签是连续变量的数据集 from sklearn.model_selection import cross_val_score from sklearn.ensemble import RandomForestRegressorboston = load_boston()regressor = RandomForestRegressor(n_estimators=100,random_state=0) #实例化 cross_val_score(regressor, boston.data, boston.target, cv=10,scoring = "neg_mean_squared_error") >>>array([-11.22504076, -5.3945749 , -4.74755867, -22.54699078, -12.31243335, -17.18030718, -6.94019868, -94.14567212, -28.541145 , -14.6250416 ])#sklearn当中模型评估指标(打分性质) import sklearn sorted(sklearn.metrics.SCORERS.keys())
实战:用随机森林回归填补缺失值
我们从现实中收集的数据,几乎不可能是完美无缺的,往往都会有一些缺失值。面对缺失值,很多人选择的方式是 直接将含有缺失值的样本删除,这是一种有效的方法,但是有时候填补缺失值会比直接丢弃样本效果更好,即便我 们其实并不知道缺失值的真实样貌。在sklearn中,我们可以使用sklearn.impute.SimpleImputer来轻松地将均 值,中值,或者其他最常用的数值填补到数据中,在这个案例中,我们将使用均值,0,和随机森林回归来填补缺 失值,并验证四种状况下的拟合状况,找出对使用的数据集来说最佳的缺失值填补方法。
导入库
import numpy as np import pandas as pd import matplotlib.pyplot as plt from sklearn.datasets import load_boston from sklearn.impute import SimpleImputer #用来填补缺失值 from sklearn.ensemble import RandomForestRegressor from sklearn.model_selection import cross_val_score
以波士顿房价数据集为例,导入完整的数据集并且进行探索
dataset = load_boston() dataset.data.shape >>>(506, 13)X_full, y_full = dataset.data, dataset.target n_samples = X_full.shape[0] n_features = X_full.shape[1]
为数据集放入缺失值
首先要确定我们要放入的缺失值的比例,在此我们假设为50%,即为3289个数
rng = np.random.RandomState(0) #确认随机模式 missing_rate = 0.5 n_missing_samples = int(np.floor(n_samples * n_features * missing_rate)) # np.floor 向下取整,返回 .0 格式的浮点数,未雨绸缪,避免出现小数
所有数据都要随机遍布在数据集的各行各列中,而一个缺失的数据会需要一个行索引和一个列索引。如果能够创造一个数组,包含3289个分布在0-506中间的行索引,和3289个分布于0-13之间的列索引,我们就可以用索引来为数据中的任意3289个位置赋值。然后我们用0,均值和随机森林来填写这些缺失值,然后查看回归的结果如何。
#randint(下限, 上线, n) 请在上限和下限之间取出n个整数 missing_features = rng.randint(0, n_features, n_missing_samples) missing_samples = rng.randint(0, n_samples, n_missing_samples)missing_features >>>array([12, 5, 0, ..., 11, 0, 2]) missing_samples >>>array([150, 125, 28, ..., 132, 456, 402]) len(missing_samples) >>>3289
我们现在采样了3289个数据,远远超过我们的样本量506,所以我们使用随机抽取的函数randint。但如果我们需要的数据量小于我们的样本量506,那我们可以采用np.random.choice来抽样,choice会随机抽取不重复的随机数,因此可以帮助我们让数据更加分散,确保数据不会集中在一些行中.
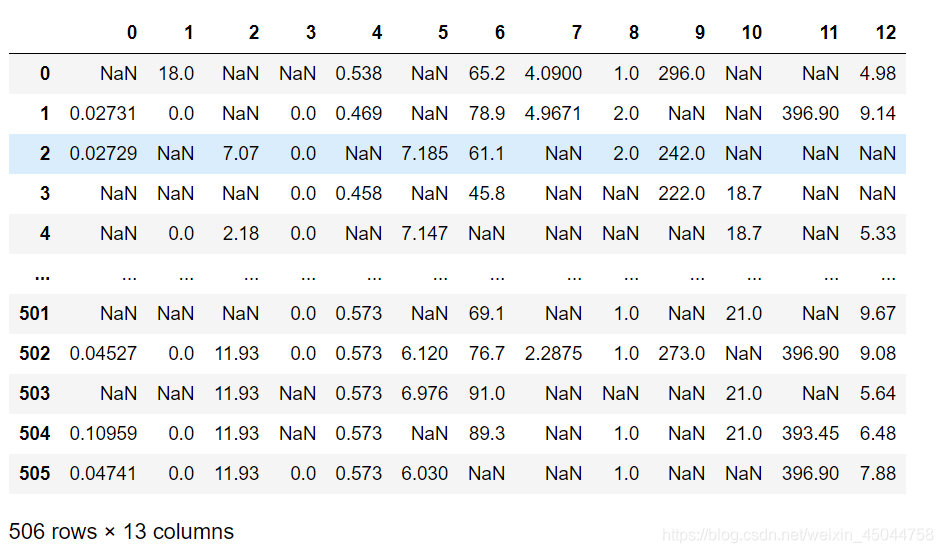
# missing_samples = rng.choice(dataset.data.shape[0],n_missing_samples,replace=False)X_missing = X_full.copy() # 构造完整数据集 y_missing = y_full.copy() # 标签不能空 # 填补缺失值是填补特征矩阵的缺失值X_missing[missing_samples,missing_features] = np.nan #把所有行和所有列取出来并定义为空值 X_missing = pd.DataFrame(X_missing) X_missing
使用均值进行填补
from sklearn.impute import SimpleImputer imp_mean = SimpleImputer(missing_values=np.nan, strategy='mean') #实例化:填补缺失值,第一个参数表示缺失值是什么,此处为空值;第二个是表示用均值替换缺失值 X_missing_mean = imp_mean.fit_transform(X_missing) #训练fit + 导出predict -----> 特殊接口 fit_transformpd.DataFrame(X_missing_mean).isnull().sum() #布尔值 对应的整数,false=0,true=1, 所以加和之后,得数一定会大于1 >>>0 0 1 0 2 0 3 0 4 0 5 0 6 0 7 0 8 0 9 0 10 0 11 0 12 0 dtype: int64使用0进行填补
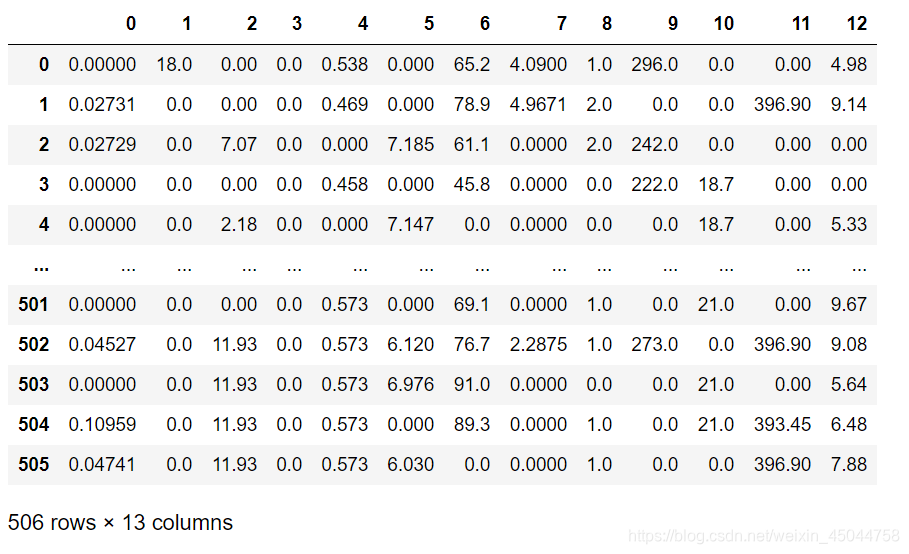
imp_0 = SimpleImputer(missing_values=np.nan, strategy="constant", fill_value=0) #constant表示常数 X_missing_0 = imp_0.fit_transform(X_missing) pd.DataFrame(X_missing_0)
使用随机森林填补缺失值
使用随机森林回归填补缺失值
任何回归都是从特征矩阵中学习,然后求解连续型标签y的过程,之所以能够实现这个过程,是因为回归算法认为,特征矩阵和标签之前存在着某种联系。实际上,标签和特征是可以相互转换的,比如说,在一个“用地区,环境,附近学校数量”预测“房价”的问题中,我们既可以用“地区”,“环境”,“附近学校数量”的数据来预测“房价”,也可以反过来, 用“环境”,“附近学校数量”和“房价”来预测“地区”。而回归填补缺失值,正是利用了这种思想。
对于一个有n个特征的数据来说,其中特征T有缺失值,我们就把特征T当作标签,其他的n-1个特征和原本的标签组成新的特征矩阵。那对于T来说,它没有缺失的部分,就是我们的Y_test,这部分数据既有标签也有特征,而它缺失的部 分,只有特征没有标签,就是我们需要预测的部分。
特征T不缺失的值对应的其他n-1个特征 + 本来的标签:X_train
特征T不缺失的值:Y_train
特征T缺失的值对应的其他n-1个特征 + 本来的标签:X_test
特征T缺失的值:未知,我们需要预测的Y_test
这种做法,对于某一个特征大量缺失,其他特征却很完整的情况,非常适用。
那如果数据中除了特征T之外,其他特征也有缺失值怎么办?
答案是遍历所有的特征,从缺失最少的开始进行填补(因为填补缺失最少的特征所需要的准确信息最少)。填补一个特征时,先将其他特征的缺失值用0代替,每完成一次回归预测,就将预测值放到原本的特征矩阵中,再继续填补下一个特征。每一次填补完毕,有缺失值的特征会减少一个,所以每次循环后,需要用0来填补的特征就越来越少。当 进行到最后一个特征时(这个特征应该是所有特征中缺失值最多的),已经没有任何的其他特征需要用0来进行填补了,而我们已经使用回归为其他特征填补了大量有效信息,可以用来填补缺失最多的特征。遍历所有的特征后,数据就完整,不再有缺失值了。
X_missing_reg = X_missing.copy()sortindex = np.argsort(X_missing_reg.isnull().sum(axis=0)).values #缺失值从少到多排序X_missing_reg.isnull().sum(axis=0) #返回了缺失值的数量 >>> 0 200 1 201 2 200 3 203 4 202 5 201 6 185 7 197 8 196 9 197 10 204 11 214 12 189 dtype: int64np.sort(X_missing_reg.isnull().sum(axis=0)) # 直接使用sort会损失索引 >>>array([185, 189, 196, 197, 197, 200, 200, 201, 201, 202, 203, 204, 214],dtype=int64)np.argsort(X_missing_reg.isnull().sum(axis=0)) #返回从小到大排序的顺序所对应的索引,第6列最少 >>>0 6 1 12 2 8 3 7 4 9 5 0 6 2 7 1 8 5 9 4 10 3 11 10 12 11 dtype: int64sortindex = np.argsort(X_missing_reg.isnull().sum(axis=0)).valuesfor i in sortindex: #构建我们的新特征矩阵(没有被选中去填充的特征+原始的标签)和新标签(被选中去填充的特征) df = X_missing_reg #新标签,用切片的方式取出第i列所有的行 fillc = df.iloc[:,i] #新特征矩阵,用concat把两个连接起来,并且通过axis=1的参数,将其作为列放在最后,而非放在下面 df = pd.concat([df.iloc[:,df.columns != i],pd.DataFrame(y_full)],axis=1) #在新特征矩阵中,对含有缺失值的列,进行0的填补 df_0 =SimpleImputer(missing_values=np.nan,strategy='constant',fill_value=0).fit_transform(df) #找出我们的训练集和测试集 #被选中要填充的特征中(现在是我们的标签),存在的那些值,非空值 Ytrain = fillc[fillc.notnull()] #被选中的要填充的特征中(现在是我们的标签),不存在的那些值,是空值 #我们需要的不是Y_test的值,而是其索引 Ytest = fillc[fillc.isnull()] #在新的特征矩阵上,被选出来的要填充的特征的非空值所对应的记录 Xtrain = df_0[Ytrain.index,:] Xtest = df_0[Ytest.index,:] #用随机森林回归来填补缺失值 rfc = RandomForestRegressor(n_estimators=100) #实例化 rfc = rfc.fit(Xtrain, Ytrain) #导入训练集进行训练 Ypredict = rfc.predict(Xtest) #将Xtest导入,得到我们的预测结果(回归结果),就是我们要用来填补空值的这些值 #将填补好的特征返回到我们的原始的特征矩阵中 X_missing_reg.loc[X_missing_reg.iloc[:,i].isnull(),i] = YpredictX_missing_reg
没有缺失值了

对填充好的数据进行建模
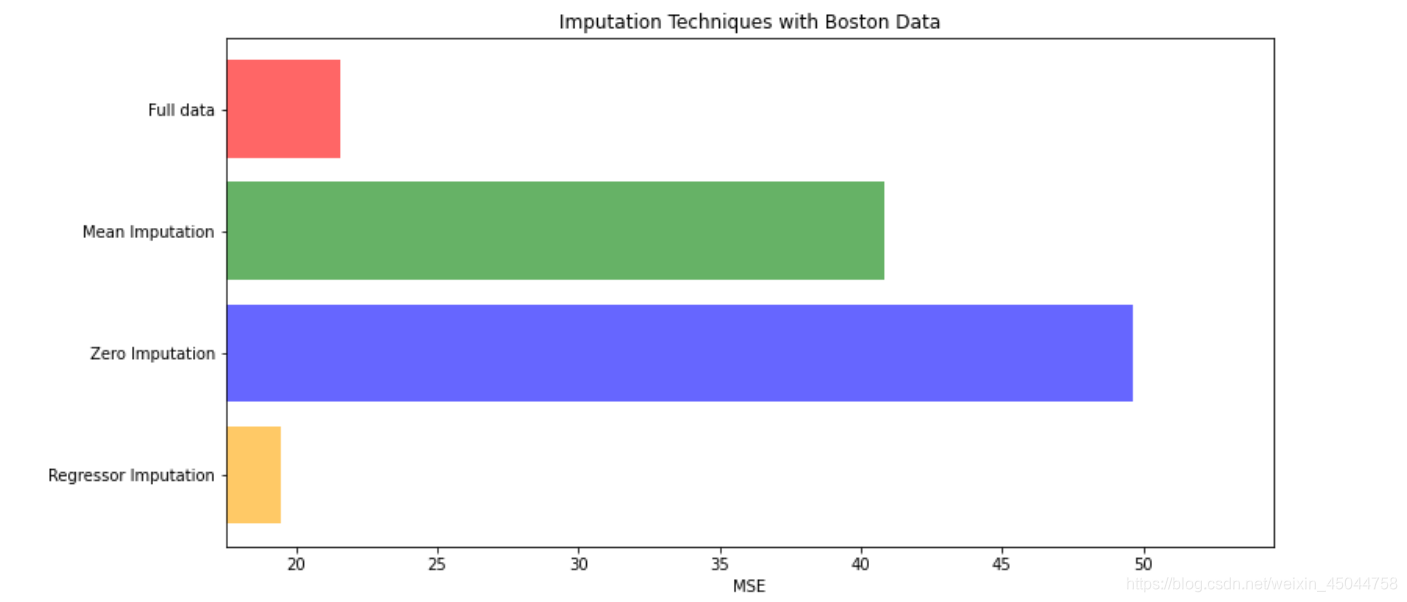
X = [X_full,X_missing_mean,X_missing_0,X_missing_reg] #四种构造好的数据集 mse = [] for x in X: estimator = RandomForestRegressor(random_state=0, n_estimators=100) #实例化 scores = cross_val_score(estimator,x,y_full,scoring='neg_mean_squared_error',cv=5).mean() mse.append(scores * -1)mse #越小越好 >>>[21.571667100368845, 40.848037216676374, 49.626793201980185, 19.490047121025036][*zip(["X_full","X_missing_mean","X_missing_0","X_missing_reg"],mse)] #将数据集和其得分连接起来 >>>[('X_full', 21.571667100368845), ('X_missing_mean', 40.848037216676374), ('X_missing_0', 49.626793201980185), ('X_missing_reg', 19.490047121025036)]
用所得结果画出条形图
x_labels = ['Full data','Mean Imputation','Zero Imputation','Regressor Imputation'] colors = ['r', 'g', 'b', 'orange'] plt.figure(figsize=(12, 6)) #定义图片大小 ax = plt.subplot(111) #添加子图 for i in np.arange(len(mse)): ax.barh(i, mse[i],color=colors[i], alpha=0.6, align='center') #barh 是横着的条形图 ax.set_title('Imputation Techniques with Boston Data') #标题 ax.set_xlim(left=np.min(mse) * 0.9,right=np.max(mse) * 1.1) #x轴的区间,因为不希望x从0开始 ax.set_yticks(np.arange(len(mse))) #设置y的刻度 ax.set_xlabel('MSE') ax.invert_yaxis() ax.set_yticklabels(x_labels) #用x_labels列表的元素作为y的命名 plt.show()