✌ 填补缺失值
1、✌ 导入相关库
import pandas as pd
import numpy as np
from sklearn.impute import SimpleImputer
from sklearn.ensemble import RandomForestRegressor
2、✌ 创建数据
x=np.random.randint(1,100,(10000,5))
y=np.random.randint(1,10,10000)
rows=np.random.randint(0,1000,20)
cols=np.random.randint(0,5,20)
x=pd.DataFrame(x)
x.iloc[rows,cols]=np.nan
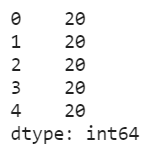
3、✌ 利用Pandas填补数据
x1=x.copy()
for i in x1.columns:
x1[x1.isnull()]=x1[i].mean()
x1.isnull().sum()

4、✌ sklearn库填补
from sklearn.impute import SimpleImputer
sim=SimpleImputer(missing_values=np.nan,strategy='constant',fill_value=0)
x2=x.copy()
x2=sim.fit_transform(x2)
pd.DataFrame(x2).isnull().sum()

5、✌ 利用模型预测
from sklearn.ensemble import RandomForestRegressor
x3= x.copy()
sortindex = np.argsort(x3.isnull().sum(axis=0)).values
for i in sortindex:
df = x3
fillc = df.iloc[:,i]
df = pd.concat([df.iloc[:,df.columns != i],pd.DataFrame(y)],axis=1)
df_0 =SimpleImputer(missing_values=np.nan,
strategy='constant',
fill_value=0).fit_transform(df)
y_train = fillc[fillc.notnull()]
y_test = fillc[fillc.isnull()]
x_train = df_0[y_train.index,:]
x_test = df_0[y_test.index,:]
clf = RandomForestRegressor(n_estimators=100)
clf = clf.fit(x_train, y_train)
y_pred = clf.predict(x_test)
x3.loc[x3.iloc[:,i].isnull(),i] = y_pred
x3.isnull().sum()
