pandas填补缺失值的方法
在处理数据的过程中,经常会遇到原数据部分内容的缺失,为了保证我们最终数据统计结果的正确性,通常我们有两种处理方式,第一种就是删除掉这些部分缺失的数据;第二种就是填补这些缺失的数据。接下来,我们主要介绍填补缺失值的方法。
填充法
咱们所用到的数据:
import pandas as pd
import numpy as np
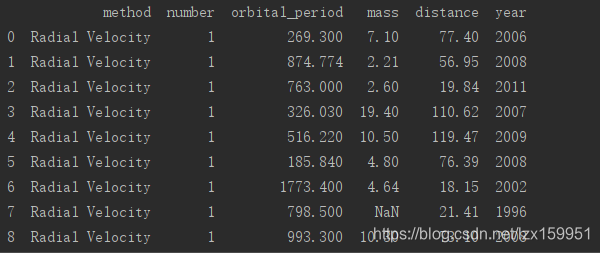
planets = pd.read_csv('planets.csv')
print(planets.head(10))
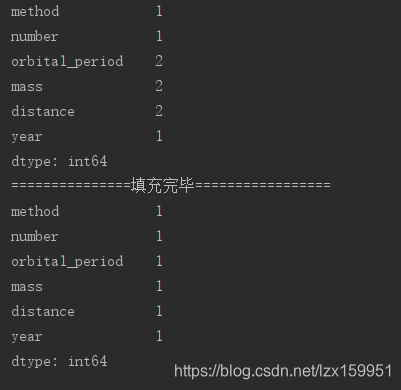
print(planets.notnull().nunique())#这里用来判断数据中是否存在为空,并且那些列存在为空的值
planets.fillna(value={'distance':planets['distance'].mean(),'mass':0,'orbital_period':0},inplace=True)
print("===============填充完毕=================")
print(planets.notnull().nunique())
好了,咱们先看一下运行结果:
接下来具体解释一下代码:
- 首先我们读取数据,然后使用head(10)获取数据的前十行数据
- notnull()方法是用来判断数据是否为空的,如果为空,返回False
- 接着跟着一个nunique() 这个方法是判断有多少不同的值。我的思路就是先通过notnull方法将空值和非空值分别使用False和True来表示,再使用nunique方法判断存在几种值。若该数为2,则代表该列中存在空值。反之若为1,则不存在空值。
- fillna(value={‘columns’:value},inplace=True) 这个方法是用来填充空值的。value这个参数需要传入字典型数据。若数据中有两列需要填补空值的,则需要写上两列的列名和需要填补的值。通常情况我们会使用mean()方法填入均值。
- 接着我们再使用3中的两个方法进行判断我们是否填值成功。
使用的planets数据链接:
