简介
这篇文章是CVPR2017的oral,非常厉害。众所周知,最近一两年卷积神经网络提高效果的方向,要么深(比如ResNet,解决了网络深时候的梯度消失问题)要么宽(比如GoogleNet的Inception),而作者则是从feature入手,通过对feature的极致利用达到更好的效果和更少的参数。
原论文地址:https://arxiv.org/pdf/1608.06993.pdf
(-2017-)DenseNet:
说起DenseNet模型,它的基本思路与ResNet一致,但是它建立的是前面所有层与后面层的密集连接(dense connection),它的名称也是由此而来。DenseNet的另一大特色是通过特征在channel上的连接来实现特征重用(feature reuse)。这些特点让DenseNet在参数和计算成本更少的情形下实现比ResNet更优的性能。先放一个dense block的结构图:
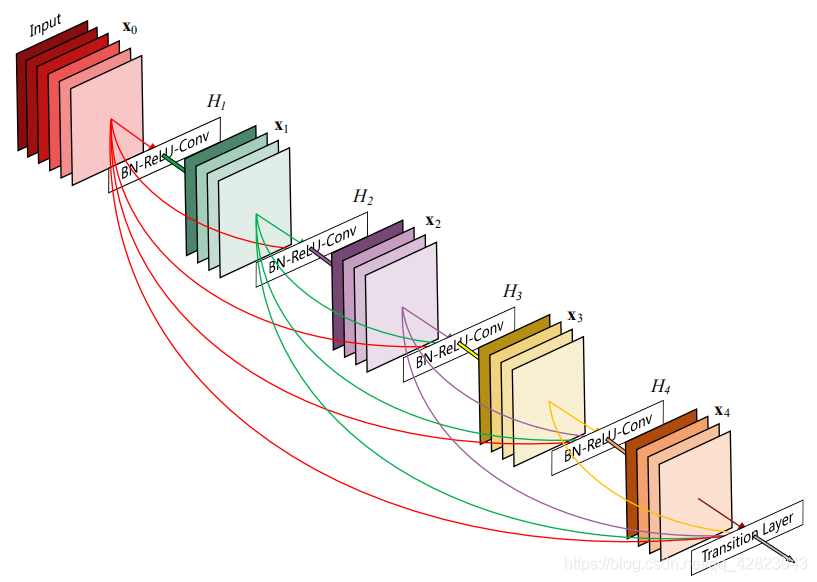
DenseNet 是受什么启发提出来的?
DenseNet 的想法很大程度上源于我们去年发表在 ECCV 上的一个叫做随机深度网络(Deep networks with stochastic depth)工作。
当时我们提出了一种类似于 Dropout 的方法来改进ResNet。我们发现在训练过程中的每一步都随机地Dropout一些层,可以显著的提高 ResNet 的泛化性能。这个方法的成功至少带给我们两点启发:
- 首先,它说明了神经网络其实并不一定要是一个递进层级结构,也就是说网络中的某一层可以不仅仅依赖于紧邻的上一层的特征,而可以依赖于更前面层学习的特征。(想像一下在随机深度网络中,当第 L 层被扔掉之后,第 L+1 层就被直接连到了第 L-1 层;当第 2 到了第 L 层都被扔掉之后,第 L+1 层就直接用到了第 1 层的特征。因此,随机深度网络其实可以看成一个具有随机密集连接的 DenseNet。)
- 其次,我们在训练的过程中随机扔掉很多层也不会破坏算法的收敛,说明了 ResNet 具有比较明显的冗余性,网络中的每一层都只提取了很少的特征(即所谓的残差)。实际上,我们将训练好的 ResNet 随机的去掉几层,对网络的预测结果也不会产生太大的影响。既然每一层学习的特征这么少,能不能降低它的计算量来减小冗余呢?
DenseNet 的设计正是基于以上两点观察。我们让网络中的每一层都直接与其前面层相连,实现特征的重复利用;同时把网络的每一层设计得特别"窄",即只学习非常少的特征图(最极端情况就是每一层只学习一个特征图),达到降低冗余性的目的。这两点也是 DenseNet 与其他网络最主要的不同。需要强调的是,第一点是第二点的前提,没有密集连接,我们是不可能把网络设计得太窄的,否则训练会出现欠拟合现象,即使 ResNet 也是如此。
在传统的卷积神经网络中,如果你有L层,那么就会有L个连接。但是在DenseNet中,会有L(L+1)/2个连接。
简单讲,就是每一层的输入来自前面所有层的输出。
相比ResNet,这是一种密集连接。而且DenseNet是直接concat来自不同层的特征图,这可以实现特征重用,提升效率,这一特点是DenseNet与ResNet最主要的区别。

其中,上面的H()代表是非线性转化函数,它是一个组合操作,其可能包括一系列的BN(Batch Normalization),ReLU,Pooling及Conv操作。
网络结构:
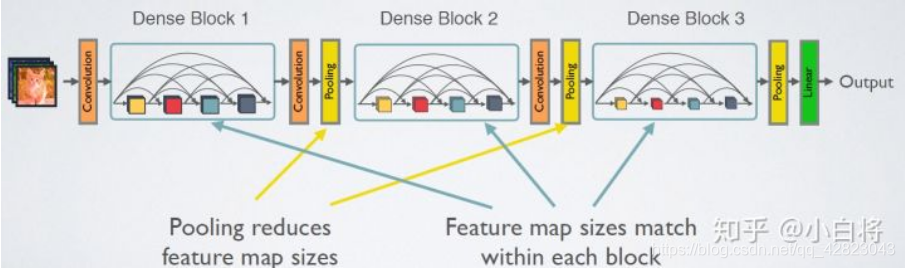
CNN网络一般要经过Pooling或者stride>1的Conv来降低特征图的大小,而DenseNet的密集连接方式需要特征图大小保持一致。
为了解决这个问题,DenseNet网络中使用DenseBlock+Transition的结构,其中DenseBlock是包含很多层的模块,每个层的特征图大小相同,层与层之间采用密集连接方式。而Transition模块是连接两个相邻的DenseBlock,并且通过Pooling使特征图大小降低。
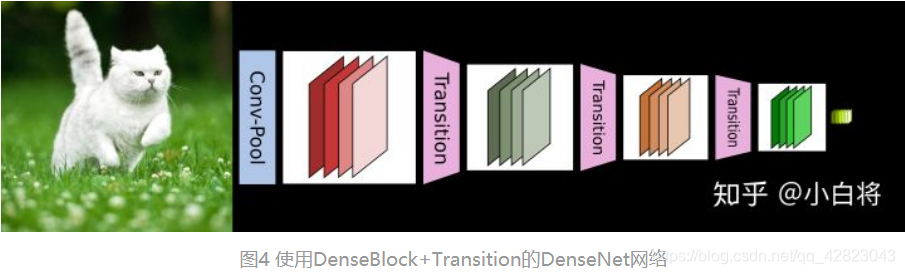
1、在DenseBlock中,各个层的特征图大小一致,可以在channel维度上连接。
DenseBlock中的非线性组合函数 H() 采用的是BN+ReLU+3x3 Conv的结构,如图6所示。另外值得注意的一点是,与ResNet不同,所有DenseBlock中各个层卷积之后均输出k个特征图,即得到的特征图的channel数为k,或者说采用k个卷积核。k在DenseNet称为growth rate,这是一个超参数。一般情况下使用较小的k(比如12),就可以得到较佳的性能。
假定输入层的特征图的channel数为k0,那么L层输入的channel数为k0+k(L-1),因此随着层数增加,尽管k设定得较小,DenseBlock的输入会非常多,不过这是由于特征重用所造成的,每个层仅有k个特征是自己独有的。
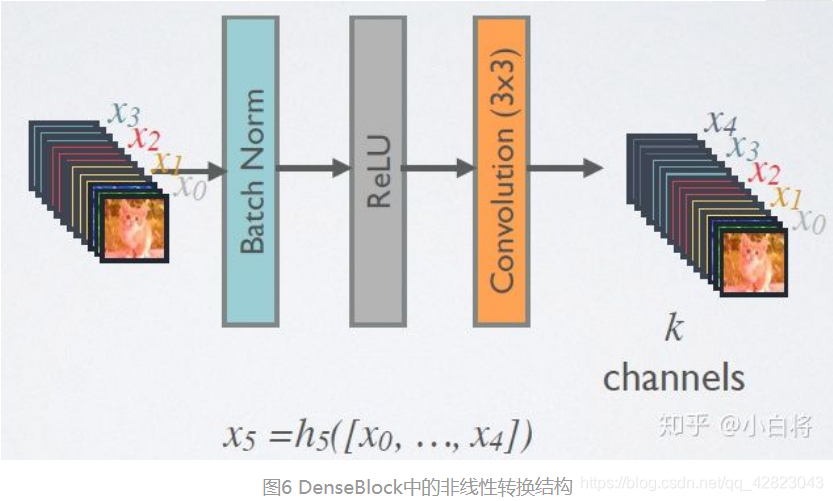
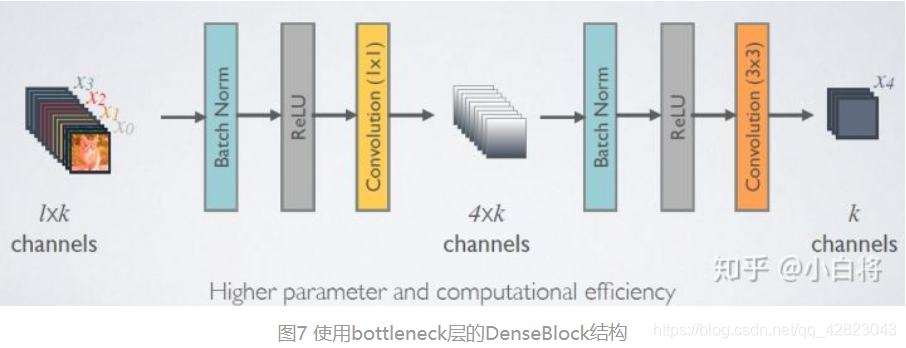
由于后面层的输入会非常大,DenseBlock内部可以采用bottleneck层来减少计算量,主要是原有的结构中增加1x1 Conv,如图7所示,即BN+ReLU+1x1 Conv+BN+ReLU+3x3 Conv,称为DenseNet-B结构。其中1x1 Conv得到 4k 个特征图它起到的作用是降低特征数量,从而提升计算效率。
2、对于Transition层,它主要是连接两个相邻的DenseBlock,并且降低特征图大小。Transition层包括一个1x1的卷积和2x2的AvgPooling,结构为BN+ReLU+1x1 Conv+2x2 AvgPooling。另外,Transition层可以起到压缩模型的作用。
假定Transition的上接DenseBlock得到的特征图channels数为m,Transition层可以产生[θm]个特征(通过卷积层),其中θ∈(0,1],是压缩系数(compression rate)。当θ=1 时,特征个数经过Transition层没有变化,即无压缩,而当压缩系数小于1时,这种结构称为DenseNet-C。文中使用θ=0.5,这样传给下一个Dense Block的时候channel数量就会减少一半,这就是Transition的作用。而对于使用bottleneck层的DenseBlock结构和压缩系数小于1的Transition组合结构称为DenseNet-BC。
总结:
综合来看,DenseNet的优势主要体现在以下几个方面:
- 由于密集连接方式,DenseNet提升了梯度的反向传播,使得网络更容易训练。由于每层可以直达最后的误差信号,实现了隐式的“deep supervision”。
- 参数更小且计算更高效,由于DenseNet是通过concat特征来实现短路连接,实现了特征重用,并且采用较小的growth rate,每个层所独有的特征图是比较小的。
- 由于特征的重复利用,最后的分类器使用了低级特征。
要注意的一点是,如果实现方式不当的话,DenseNet可能耗费很多GPU显存。训练 DenseNet 跟训练其他网络没有什么特殊的地方,对于训练 ResNet 的代码,只需要把模型替换成 DenseNet 就可以了。
Tensorflow实现:
class DenseNet():
def __init__(self, x, nb_blocks, filters, training):
self.nb_blocks = nb_blocks
self.filters = filters
self.training = training
self.model = self.Dense_net(x)
def bottleneck_layer(self, x, scope):
# print(x)
with tf.name_scope(scope):
x = Batch_Normalization(x, training=self.training, scope=scope+'_batch1')
x = Relu(x)
x = conv_layer(x, filter=4 * self.filters, kernel=[1,1], layer_name=scope+'_conv1')
x = Drop_out(x, rate=dropout_rate, training=self.training)
x = Batch_Normalization(x, training=self.training, scope=scope+'_batch2')
x = Relu(x)
x = conv_layer(x, filter=self.filters, kernel=[3,3], layer_name=scope+'_conv2')
x = Drop_out(x, rate=dropout_rate, training=self.training)
# print(x)
return x
def transition_layer(self, x, scope):
with tf.name_scope(scope):
x = Batch_Normalization(x, training=self.training, scope=scope+'_batch1')
x = Relu(x)
# x = conv_layer(x, filter=self.filters, kernel=[1,1], layer_name=scope+'_conv1')
# https://github.com/taki0112/Densenet-Tensorflow/issues/10
in_channel = x.shape[-1]
x = conv_layer(x, filter=in_channel*0.5, kernel=[1,1], layer_name=scope+'_conv1')
x = Drop_out(x, rate=dropout_rate, training=self.training)
x = Average_pooling(x, pool_size=[2,2], stride=2)
return x
def dense_block(self, input_x, nb_layers, layer_name):
with tf.name_scope(layer_name):
layers_concat = list()
layers_concat.append(input_x)
x = self.bottleneck_layer(input_x, scope=layer_name + '_bottleN_' + str(0))
layers_concat.append(x)
for i in range(nb_layers - 1):
x = Concatenation(layers_concat)
x = self.bottleneck_layer(x, scope=layer_name + '_bottleN_' + str(i + 1))
layers_concat.append(x)
x = Concatenation(layers_concat)
return x
def Dense_net(self, input_x):
x = conv_layer(input_x, filter=2 * self.filters, kernel=[7,7], stride=2, layer_name='conv0')
x = Max_Pooling(x, pool_size=[3,3], stride=2)
for i in range(self.nb_blocks) :
# 6 -> 12 -> 48
x = self.dense_block(input_x=x, nb_layers=4, layer_name='dense_'+str(i))
x = self.transition_layer(x, scope='trans_'+str(i))
"""
x = self.dense_block(input_x=x, nb_layers=6, layer_name='dense_1')
x = self.transition_layer(x, scope='trans_1')
x = self.dense_block(input_x=x, nb_layers=12, layer_name='dense_2')
x = self.transition_layer(x, scope='trans_2')
x = self.dense_block(input_x=x, nb_layers=48, layer_name='dense_3')
x = self.transition_layer(x, scope='trans_3')
"""
x = self.dense_block(input_x=x, nb_layers=32, layer_name='dense_final')
# 100 Layer
x = Batch_Normalization(x, training=self.training, scope='linear_batch')
x = Relu(x)
x = Global_Average_Pooling(x)
x = flatten(x)
x = Linear(x)
# x = tf.reshape(x, [-1, 10])
return x
系列传送门:
CNN发展简史——LeNet(一)
CNN发展简史——AlexNet(二)
CNN发展简史——VGG(三)
CNN发展简史——GoogLeNet(四)
CNN发展简史——ResNet(五)