求n个数据中的中间大小的1个或2个数。
可以建两个大小都是n / 2的堆。第一个堆是小顶堆,第二个堆是大顶堆。要求大顶堆的堆顶元素 < 小顶堆的堆顶元素,如果不符合,就交换两个堆的堆顶元素,维护这两个堆。最后,两个堆的堆顶元素就是n个数据中的中间大小的2个数。
对于这个数组arr来说,前一半的空间用来建立小顶堆;后一半的空间建立大顶堆。对于这个小顶堆,如果某一个元素的编号是i,则它的左儿子的编号是:2 * i + 1; 右儿子的编号是:2 * i + 2。对于这个大顶堆,如果某一个元素的编号是i,则它的左儿子的编号是[i - (size / 2 - 1)] * 2 + 1 + size / 2 - 1 - 1 = 2 * i - size / 2 + 1; 右儿子的编号是 2 * i - size / 2 + 2。
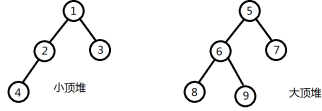
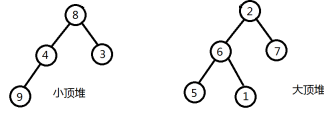
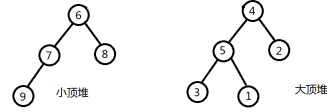
下面对这个过程进行分解:先把前一半数据当成一个小顶堆,后一半数据当成一个大顶堆。然后对这两组数据进行完整的调整,得到小顶堆和大顶堆。
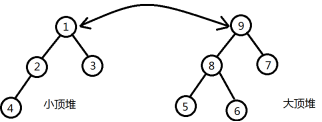
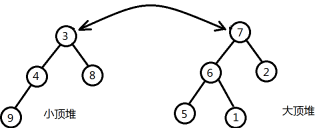
由于要求小顶堆的堆顶数据比大顶堆的堆顶数据大,所以要交换两个堆顶数据。之后对这两组数据重新调整,使它们重新符合小顶堆和大顶堆的定义。
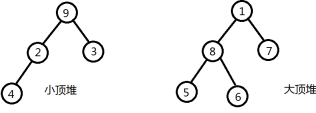
重复上述过程。
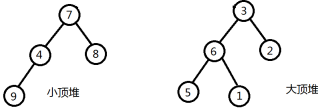
重复上述过程。
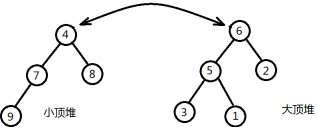
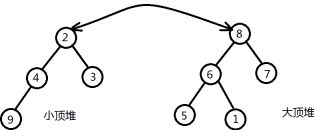
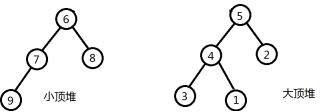
重复上述过程。最终得到如下两个堆,我们可以发现最大的4个数已经集中到小顶堆上,而最小的5个数集中到大顶堆。这时小顶堆和大顶堆的堆顶元素就是所有数中的中位数。
中位数的求解代码如下:
#include <stdio.h>
#include <stdlib.h>
int arr [] = {1, 2, 3, 4, 5, 6, 7, 8, 9};
int sizeOfMinHeap = 0; //小顶堆的大小
int sizeOfMaxHeap = 0; //大顶堆的大小
int size = 0; //数组的大小
void swap(int i, int j) //交换数组arr中编号为i和j的两个元素
{
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
//寻找3个元素中的最小值
int getMinForMinHeap(int father, int leftSon, int rightSon)
{
int minIndex = father; //较小元素的index
int min = arr[father]; //较小元素的值
if(leftSon < sizeOfMinHeap && arr[leftSon] < min)
{
min = arr[leftSon];
minIndex = leftSon;
}
if(rightSon < sizeOfMinHeap && arr[rightSon] < min)
{
minIndex = rightSon;
}
return minIndex; //返回最小值的元素的编号
}
//寻找3个元素中的最大值
int getMaxForMaxHeap(int father, int leftSon, int rightSon)
{
int maxIndex = father; //较大元素的index
int max = arr[father]; //较大元素的值
if(leftSon < size && arr[leftSon] > max)
{
max = arr[leftSon];
maxIndex = leftSon;
}
if(rightSon < size && arr[rightSon] > max)
{
maxIndex = rightSon;
}
return maxIndex; //返回最大值的元素的编号
}
//前一半数组用来建立小顶堆,向下调整函数
void shiftDownForMinHeap(int i)
{
int minIndex = 0; //较大元素的index
while(true)
{
//左儿子的编号是i * 2 + 1,右儿子的编号是i * 2 + 2
minIndex = getMinForMinHeap(i, i * 2 + 1, i * 2 + 2);
if(minIndex != i) //父节点不是最小结点时
{
swap(minIndex, i); //交换,使父节点成为最小结点
i = minIndex; //更新i结点,继续向下调整
}
else //父节点是最小结点时
{
break; //退出循环
}
}
}
//后一半数组用来建立大顶堆,用来向下调整的函数
void shiftDownForMaxHeap(int i)
{
int maxIndex = 0; //较大元素的index
while(true)
{
//利用后一半数组建堆,父节点的编号为i,
//左儿子的编号是2 * i - size / 2 + 1,右儿子的编号是2 * i - size / 2 + 2
maxIndex = getMaxForMaxHeap(i, 2 * i - size / 2 + 1, 2 * i - size / 2 + 2);
if(maxIndex != i) //父节点不是最大结点时
{
swap(maxIndex, i); //交换,使父节点成为最大结点
i = maxIndex; //更新i结点,继续向下调整
}
else //父节点是最大结点时
{
break; //退出循环
}
}
}
//建堆
void createHeap()
{
//建立小顶堆
for (int i = sizeOfMinHeap / 2; i >= 0; i--)
{
shiftDownForMinHeap(i);
}
//建立大顶堆,注意使用的是后一半元素
for (int i = sizeOfMinHeap + sizeOfMaxHeap / 2; i >= sizeOfMinHeap; i--)
{
shiftDownForMaxHeap(i);
}
}
void show(int start, int end) //显示数组
{
for(int i = start; i < end; i++)
{
printf("%d, ", arr[i]);
}
printf("\r\n\r\n");
}
int main()
{
size = sizeof(arr) / sizeof(int); //计算数组大小
sizeOfMinHeap = size / 2;
sizeOfMaxHeap = size - sizeOfMinHeap;
printf("原始数组:\r\n");
show(0, size);
createHeap(); //建堆
printf("初次建堆之后的数组:\r\n");
show(0, size);
while(arr[0] < arr[sizeOfMinHeap])
{
swap(0, sizeOfMinHeap); //交换两个堆的堆顶元素
shiftDownForMinHeap(0); //维护小顶堆
shiftDownForMaxHeap(sizeOfMinHeap); //维护大顶堆
//printf("中间调整过程:");
//show(0, size);
}
printf("最终调整完成之后的数组:\r\n");
show(0, size);
printf("小顶堆的堆顶元素:%d\r\n", arr[0]);
printf("大顶堆的堆顶元素:%d\r\n", arr[sizeOfMinHeap]);
printf("小顶堆的元素:\r\n");
show(0, sizeOfMinHeap);
printf("大顶堆的元素:\r\n");
show(sizeOfMinHeap, size);
printf("这些数的中位数:%d, %d\r\n", arr[0], arr[sizeOfMinHeap]);
return 0;
}
运行结果:

中位数问题其实就是前面top-K问题一种特殊形式。如果希望计算n个数据中,第20%~30%大的数,可以用类似的方式:建立两个堆。最前面的20%的数据放在一个小顶堆中。最后面的70%的数据放在一个大顶堆中。调整两个堆,让小顶堆中的数据都大于大顶堆中的数据。然后对剩余的10%的数据跟这两个堆进行比较,要求这10%的数据介于这两个堆顶元素之间,如果超出范围,就进行交换。这个算法就交给读者了。
堆的应用实例暂时就介绍到这里了。总的来说,堆是一种完全二叉树,可以很方便的用数组进行储存,而一般的树、二叉树则不适合用数组储存。使用数组储存的最大优势是可以快速的找到某个元素的父节点、子节点的下标,时间复杂度为O(1)。同时,由于堆的增加、删除、修改的效率都很高 (logN),所以经常利用堆进行加速计算。