摘要
比赛当中数据处理有很多种,对图像数据的分析,和分析之后该如何加强比较低的ap类别,今天就讲解我最近使用的几种困难样本学习和专注低ap的数据增强后的处理。
困难样本就是loss比较大的,在每一个批次训练当中都占有很大部分的loss,导致loss很难继续降低。
困难样本提取
我使用的是pytorch版本efficientdet,整体流程也比较简单,就是在dataloader上改动getitem这个函数,返回的时候加上图像的name就可以了。因为大多数训练都是批次化训练说以collect这个函数返回也要带上图像的name就行,然后在到train中吧loss大于0.5左右的图像名字记录下来,写入到一个txt文本当中。具体操作如下,先看我train.py的修改吧
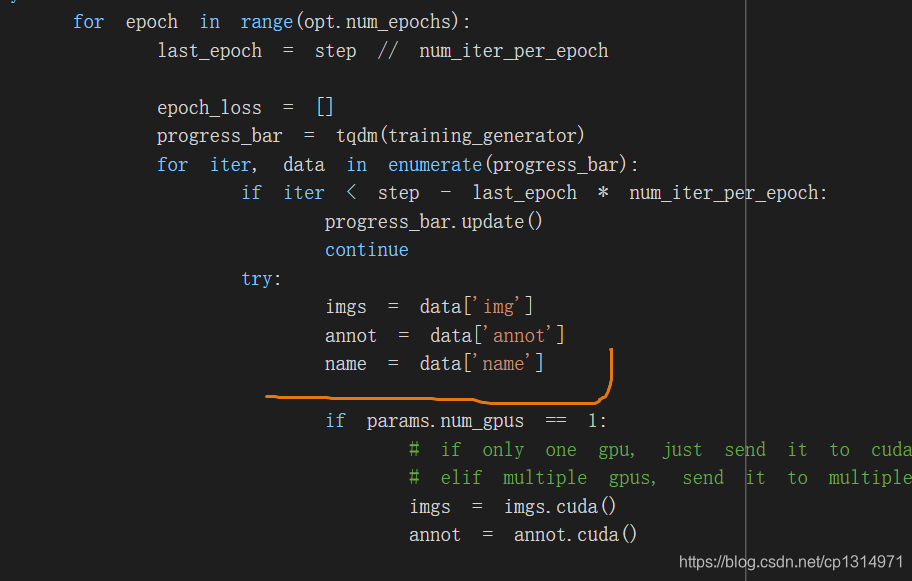
加载的时候要把图像的name加载进来,
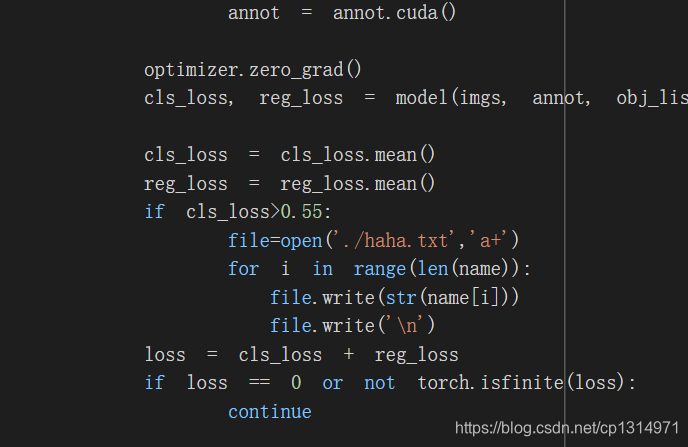
我这里就关注了分类的loss,所以处理的时候把名字加载到一个txt文件当中就可以了,在来仔细看下我dataloader的处理
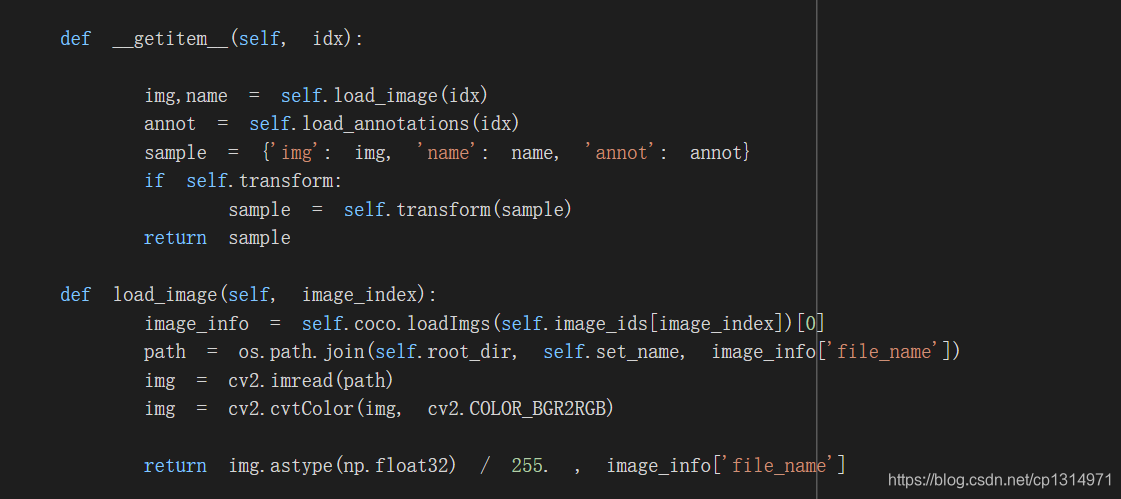
仔细看一下这里,在sample我就设置加载了name,还有一点地方需要修改, 比较简单,就是对数据加载的处理,可以看我之前写的博客数据加载就很容易掌握。
最后就是把这个txt文件中的照片从训练集中单独提取出来,代码如下
import numpy as np
# a = 'hahawqeq'
file=open('./haha.txt','r')
aa = []
for i in file.readlines():
aa.append(i.split('\n')[0])
print(len(aa))
dd = list(np.unique(aa))
print(len(dd))
import os
import shutil
xml_train = './coco/train2017/'
i = 0
while(i<len(dd)):
random_file = dd[i]
source_file = "%s/%s" % (xml_train, random_file)
xml_val = './coco/kunnan/'
if random_file not in os.listdir(xml_val):
shutil.move(source_file, xml_val)
i=i+1
代码很简单,就是几个细节就是source_file是生成相对路径的,然后转移到xml_val路径下,就处理成功了,xml文件也一样,之后再生成json文件就可以了。
低ap数据类别增强
我们训练的时候不可能每一个类别都很高,所以我们需要对json文件提取出来ap比较低的类别,
import os
import torch
import numpy as np
import matplotlib.pyplot as plt
from torch.utils.data import Dataset, DataLoader
from pycocotools.coco import COCO
import cv2
# 1,19,36
coco = COCO('./test/all.json')
ids1 = coco.getAnnIds()
# print(ids1)
ids2 = coco.getImgIds()
# print(ids2)
items = []
for i in range(len(ids1)):
data = coco.loadAnns(ids1[i])
#这一步我是对应我自己的类别来处理其中需要的类别
if data[0]['category_id']==1:
items.append(data[0]['image_id'])
elif data[0]['category_id']==5:
items.append(data[0]['image_id'])
elif data[0]['category_id']==18:
items.append(data[0]['image_id'])
elif data[0]['category_id']==0:
items.append(data[0]['image_id'])
elif data[0]['category_id']==19:
items.append(data[0]['image_id'])
elif data[0]['category_id']==36:
items.append(data[0]['image_id'])
elif data[0]['category_id']==22:
items.append(data[0]['image_id'])
elif data[0]['category_id']==27:
items.append(data[0]['image_id'])
elif data[0]['category_id']==35:
items.append(data[0]['image_id'])
elif data[0]['category_id']==42:
items.append(data[0]['image_id'])
else:
continue
# print(items)
item =np.unique(items)
# print(item)
name =[]
for j in range(len(item)):
data=coco.loadImgs(ids2[j])
name.append(data[0]['file_name'])
import os
import shutil
xml_train = './coco/train2017/'
i = 0
while(i<len(name)):
random_file = name[i].split('.')[0]+'.jpg'
source_file = "%s/%s" % (xml_train, random_file)
xml_val = './coco/lowap/'
print(i)
if random_file not in os.listdir(xml_val):
shutil.move(source_file, xml_val)
i=i+1
整体就是看一个流程吧,对json文件的充分利用,之后就在对提取出来的图像数据增强
import albumentations
import cv2
from PIL import Image, ImageDraw
import numpy as np
from albumentations import (GridDropout,GridDistortion)
import matplotlib.pyplot as plt
import glob
import numpy as np
import matplotlib.pyplot as plt
import cv2
def imread(image):
image=cv2.imread(image)
image=cv2.cvtColor(image,cv2.COLOR_BGR2RGB)
image=image.astype(np.uint8)
return np.array(image)
def show(image):
plt.imshow(image)
plt.axis('off')
plt.show()
# Path to data
data_folder = f"./lowap/"
# Read filenames in the data folder
filenames = glob.glob(f"{data_folder}*.jpg")
for i in range(len(filenames)):
b = filenames[i]
print(b)
a =imread(b)
image2 =GridDropout(0.2,10,p=1)(image=a)['image']
dd='./haha/'+filenames[i].split('/')[2]
cv2.imwrite(dd,image2)
我使用的是albu数据包增强比较方便,这种是离线增强。


总结
有很多的数据增强手段,我只是简单的使用了其中一种,比较高级点的是cutmix操作吧,大家也可以测试更多的增强手段