SSD 网络框架
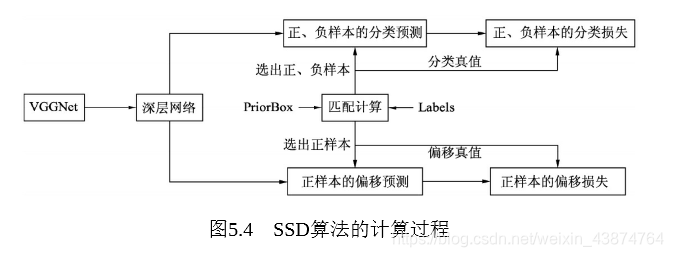
SSD在VGGNet的基础上又增加了多个卷积层,并利用多个特征图进行边框提取得到深层网络,之后利用人为设置的PriorBox与标签内的边框进行匹配,根据重叠程度筛选出正负样本,得到分类与偏移的真值然后与预测值一同计算损失.
SSD的VGG16
输入经过SSD预处理后大小固定为300300,之后进入VGG16基础网络,SSD保留了VGG的前13层卷积网络,之后添加了Conv6和Conv7取代了全连接网络。Conv6中使用了空洞数为6的空洞卷积,并且padding也为6,这样可以在维持特征图尺寸不变时增加感受野。Conv7为11的卷积层降低了维数以便减少参数数量。此外VGG的池化层参数也有所改变。
ssd.py中VGG16的定义
def vgg(cfg, i, batch_norm=False):
layers = []
in_channels = i
for v in cfg:
if v == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
elif v == 'C':
layers += [nn.MaxPool2d(kernel_size=2, stride=2, ceil_mode=True)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
if batch_norm:
layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace=True)]
else:
layers += [conv2d, nn.ReLU(inplace=True)]
in_channels = v
pool5 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
conv6 = nn.Conv2d(512, 1024, kernel_size=3, padding=6, dilation=6)
conv7 = nn.Conv2d(1024, 1024, kernel_size=1)
layers += [pool5, conv6,
nn.ReLU(inplace=True), conv7, nn.ReLU(inplace=True)]
return layers
base = {
'300': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'C', 512, 512, 512, 'M',
512, 512, 512],
'512': [],
}
ssd_vgg = vgg(base['300'],3) 完成基础网络构造
深度卷积层
SSD在VGG16(包括conv6,conv7)之后又添加了四个深度卷积层,
def add_extras(cfg, i, batch_norm=False):
# Extra layers added to VGG for feature scaling
layers = []
in_channels = i
flag = False
for k, v in enumerate(cfg):
if in_channels != 'S':
if v == 'S':
layers += [nn.Conv2d(in_channels, cfg[k + 1],
kernel_size=(1, 3)[flag], stride=2, padding=1)]
else:
layers += [nn.Conv2d(in_channels, v, kernel_size=(1, 3)[flag])]
flag = not flag
in_channels = v
return layers
extras = {
'300': [256, 'S', 512, 128, 'S', 256, 128, 256, 128, 256],
'512': [],
}
extraconv = add_extra(extras['300'],1024)
PriorBox与边框特征提供网络
SSD采用了PriorBox进行区域生成,PriorBox本质上是一系列固定大小的矩形框,SSD先验性地提供了以某个坐标为中心的4个或6个不同大小的PriorBox,然后利用特征图的特征去预测PriorBox的类别和位置偏移量。在SSD中,虽然矩形框的大小固定,但是作用于不同的特征图中可以得到不同大小的图片,浅层的特征图感受野比较小,适合检测小物体,深层适合大物体。
SSD利用conv4,conv7,conv8,conv9,conv10,conv11六个卷积层分别进行矩形框操作
prior_box.py中对priorbox的定义
class PriorBox(object):
"""Compute priorbox coordinates in center-offset form for each source
feature map.
"""
def __init__(self, cfg):
super(PriorBox, self).__init__()
self.image_size = cfg['min_dim'] #图片尺寸
# number of priors for feature map location (either 4 or 6)
self.num_priors = len(cfg['aspect_ratios'])
self.variance = cfg['variance'] or [0.1]
self.feature_maps = cfg['feature_maps']
self.min_sizes = cfg['min_sizes']
self.max_sizes = cfg['max_sizes']
self.steps = cfg['steps']
self.aspect_ratios = cfg['aspect_ratios']
self.clip = cfg['clip']
self.version = cfg['name']
for v in self.variance:
if v <= 0:
raise ValueError('Variances must be greater than 0')
def forward(self):
mean = []
for k, f in enumerate(self.feature_maps):#以六个框为例
for i, j in product(range(f), repeat=2):
# f_k为每个conv层的特征图尺寸
f_k = self.image_size / self.steps[k]
# unit center x,y 框的中心坐标
cx = (j + 0.5) / f_k
cy = (i + 0.5) / f_k
# aspect_ratio: 1 正方形框
# rel size: min_size
s_k = self.min_sizes[k]/self.image_size
mean += [cx, cy, s_k, s_k]
# aspect_ratio: 1 正方形框
# rel size: sqrt(s_k * s_(k+1))
s_k_prime = sqrt(s_k * (self.max_sizes[k]/self.image_size))
mean += [cx, cy, s_k_prime, s_k_prime]
# rest of aspect ratios 不同比例的矩形框
for ar in self.aspect_ratios[k]:
mean += [cx, cy, s_k*sqrt(ar), s_k/sqrt(ar)]
mean += [cx, cy, s_k/sqrt(ar), s_k*sqrt(ar)]
# back to torch land
output = torch.Tensor(mean).view(-1, 4)
if self.clip:
output.clamp_(max=1, min=0)
return output
#cfg的参数
voc = {
'num_classes': 21,
'lr_steps': (80000, 100000, 120000),
'max_iter': 120000,
'feature_maps': [38, 19, 10, 5, 3, 1],
'min_dim': 300,
'steps': [8, 16, 32, 64, 100, 300],
'min_sizes': [30, 60, 111, 162, 213, 264],
'max_sizes': [60, 111, 162, 213, 264, 315],
'aspect_ratios': [[2], [2, 3], [2, 3], [2, 3], [2], [2]],
'variance': [0.1, 0.2],
'clip': True,
'name': 'VOC',
}
生成矩形框之后需要为每个边框提取特征值 代码在ssd.py中
def multibox(vgg, extra_layers, cfg, num_classes):
loc_layers = []
conf_layers = []
vgg_source = [21, -2]
for k, v in enumerate(vgg_source):
loc_layers += [nn.Conv2d(vgg[v].out_channels,
cfg[k] * 4, kernel_size=3, padding=1)]
conf_layers += [nn.Conv2d(vgg[v].out_channels,
cfg[k] * num_classes, kernel_size=3, padding=1)]
for k, v in enumerate(extra_layers[1::2], 2):
loc_layers += [nn.Conv2d(v.out_channels, cfg[k]
* 4, kernel_size=3, padding=1)]
conf_layers += [nn.Conv2d(v.out_channels, cfg[k]
* num_classes, kernel_size=3, padding=1)]
return vgg, extra_layers, (loc_layers, conf_layers)
总体网络计算过程
在ssd.py中class ssd类的forward
def forward(self, x):
sources = list() 保存特征图
loc = list() 保存PriorBox的位置预测
conf = list() 保存ProrBox的类别预测
# apply vgg up to conv4_3 relu,并保存特征(即保存之前提到过的六层卷积层输出的特征图)
for k in range(23):
x = self.vgg[k](x)
s = self.L2Norm(x)
sources.append(s)
# apply vgg up to fc7
for k in range(23, len(self.vgg)):
x = self.vgg[k](x)
sources.append(x)
# apply extra layers and cache source layer outputs
for k, v in enumerate(self.extras):
x = F.relu(v(x), inplace=True)
if k % 2 == 1:
sources.append(x)
# apply multibox head to source layers (对特征图进行位置和类别卷积运算并保存在loc和conf中)
for (x, l, c) in zip(sources, self.loc, self.conf):
loc.append(l(x).permute(0, 2, 3, 1).contiguous())
conf.append(c(x).permute(0, 2, 3, 1).contiguous())
loc = torch.cat([o.view(o.size(0), -1) for o in loc], 1)
conf = torch.cat([o.view(o.size(0), -1) for o in conf], 1)
if self.phase == "test":
测试时包括loc conf预测值和真实边框信息
output = self.detect(
loc.view(loc.size(0), -1, 4), # loc preds
self.softmax(conf.view(conf.size(0), -1,
self.num_classes)), # conf preds
self.priors.type(type(x.data)) # default boxes
)
else:
训练时包括loc conf预测值与PriorBox的信息
output = (
loc.view(loc.size(0), -1, 4),
conf.view(conf.size(0), -1, self.num_classes),
self.priors
)
return output
匹配与损失求解
定位损失:计算标签为正样本的PriorBox与真实边框的位置误差
类别损失:筛选出正样本与数量为正样本3倍的负样本计算类别损失
预选框与真实框的匹配
利用IoU,当一个PriorBox与所有真实框的IoU都小于0.5则为负样本,将PriorBox与其拥有最大IoU的真实框作为其真实位置标签。每个真实框都有IoU最大的预测框,但是这个预测框可能与别的真实框IoU更大,在实际处理时以真实框为对象,即便IoU不是此PriorBox的最大值,也将该Box对应到该真实框上,预测偏移量的代码如下
box_utils.py中的match函数
def match(threshold, truths, priors, variances, labels, loc_t, conf_t, idx):
"""Match each prior box with the ground truth box of the highest jaccard
overlap, encode the bounding boxes, then return the matched indices
corresponding to both confidence and location preds.
Args:
threshold: (float) The overlap threshold used when mathing boxes.
truths: (tensor) Ground truth boxes, Shape: [num_obj, num_priors].
priors: (tensor) Prior boxes from priorbox layers, Shape: [n_priors,4].
variances: (tensor) Variances corresponding to each prior coord,
Shape: [num_priors, 4].
labels: (tensor) All the class labels for the image, Shape: [num_obj].
loc_t: (tensor) Tensor to be filled w/ endcoded location targets.
conf_t: (tensor) Tensor to be filled w/ matched indices for conf preds.
idx: (int) current batch index
Return:
The matched indices corresponding to 1)location and 2)confidence preds.
"""
# jaccard index
overlaps = jaccard(
truths,
point_form(priors)
)
# (Bipartite Matching)
# [1,num_objects] best prior for each ground truth
best_prior_overlap, best_prior_idx = overlaps.max(1, keepdim=True)
# [1,num_priors] best ground truth for each prior
best_truth_overlap, best_truth_idx = overlaps.max(0, keepdim=True)
best_truth_idx.squeeze_(0)
best_truth_overlap.squeeze_(0)
best_prior_idx.squeeze_(1)
best_prior_overlap.squeeze_(1)
best_truth_overlap.index_fill_(0, best_prior_idx, 2) # ensure best prior
# TODO refactor: index best_prior_idx with long tensor
# ensure every gt matches with its prior of max overlap
for j in range(best_prior_idx.size(0)):
best_truth_idx[best_prior_idx[j]] = j
matches = truths[best_truth_idx] # Shape: [num_priors,4]
conf = labels[best_truth_idx] + 1 # Shape: [num_priors]
conf[best_truth_overlap < threshold] = 0 # label as background
loc = encode(matches, priors, variances) #进一步计算定位的偏移真值
loc_t[idx] = loc # [num_priors,4] encoded offsets to learn
conf_t[idx] = conf # [num_priors] top class label for each prior
def encode(matched, priors, variances):
"""Encode the variances from the priorbox layers into the ground truth boxes
we have matched (based on jaccard overlap) with the prior boxes.
Args:
matched: (tensor) Coords of ground truth for each prior in point-form
Shape: [num_priors, 4].
priors: (tensor) Prior boxes in center-offset form
Shape: [num_priors,4].
variances: (list[float]) Variances of priorboxes
Return:
encoded boxes (tensor), Shape: [num_priors, 4]
"""
# dist b/t match center and prior's center
g_cxcy = (matched[:, :2] + matched[:, 2:])/2 - priors[:, :2]
# encode variance
g_cxcy /= (variances[0] * priors[:, 2:])
# match wh / prior wh
g_wh = (matched[:, 2:] - matched[:, :2]) / priors[:, 2:]
g_wh = torch.log(g_wh) / variances[1]
# return target for smooth_l1_loss
return torch.cat([g_cxcy, g_wh], 1) # [num_priors,4]
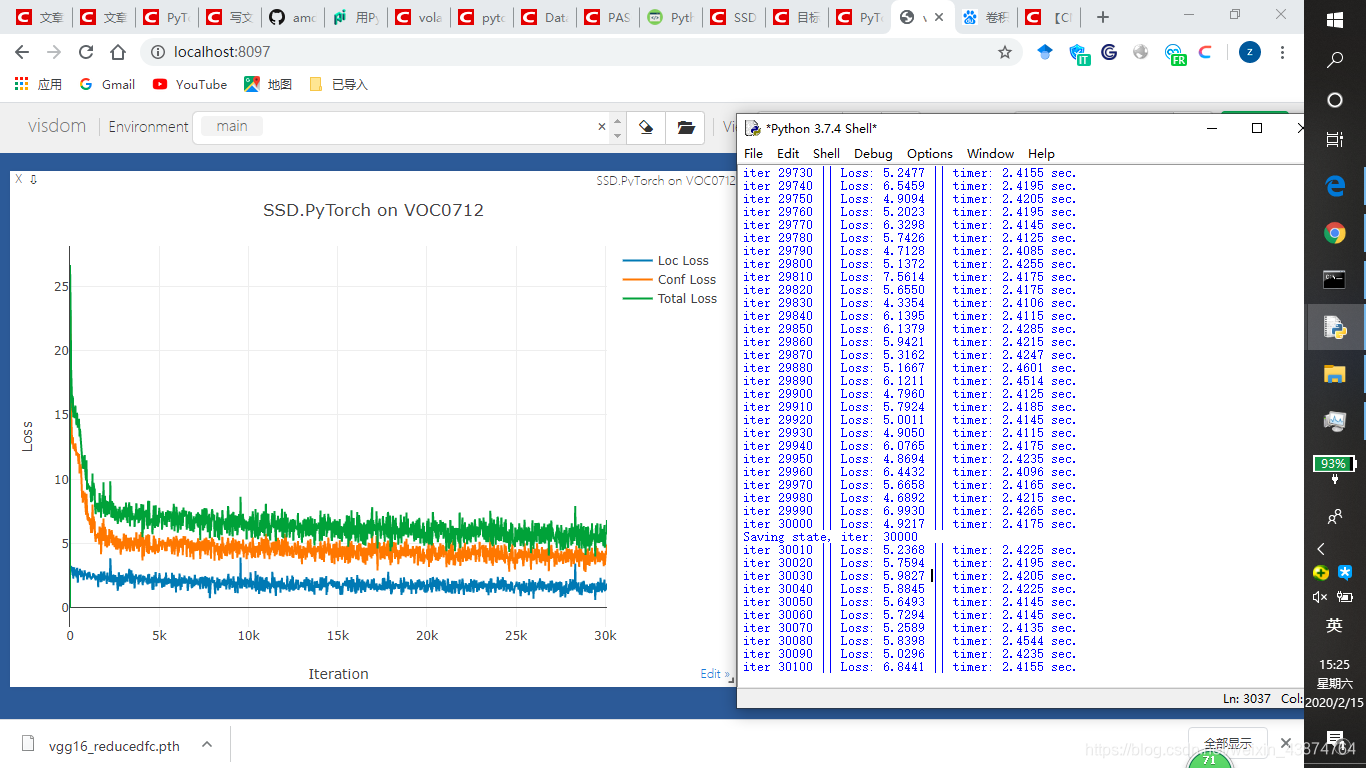
训练过程
运行train.py