爬取百度地图迁徙数据的方法请参考这篇文章:
python_爬虫_百度地图迁徙_迁入地来源_迁出目的地
将json数据处理成excel请参考这篇文章:
python_将爬取的百度地图迁徙json数据写入到excel
原始数据格式:
“jsonp_1584195671576_1286958({“errno”:0,“errmsg”:“SUCCESS”,“data”:{“list”:[{“province_name”:“山东省”,“value”:42.64},{“province_name”:“河南省”,“value”:24.15},
…
{“province_name”:“青海省”,“value”:0.02},{“province_name”:“新疆维吾尔自治区”,“value”:0.01}]}})”
处理成功的数据格式,矩阵的格式可用于机器学习研究
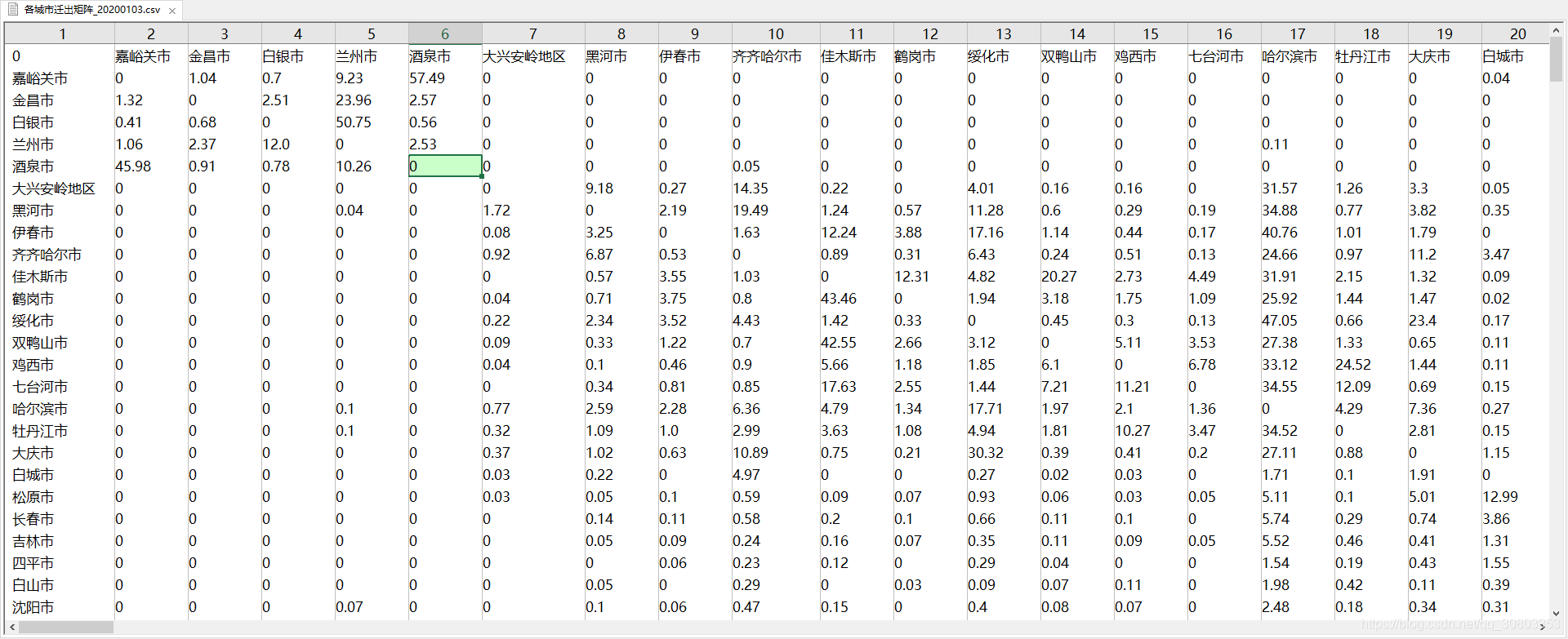
import os
import re
from utils.read_write import readTXT, writeOneJSON, eachFile, writeOneCSV
os.chdir(r'D:\data\百度迁徙大数据\最新城市省份流入流出数据\json')
# 把txt文件读取成字符串数组
lines = readTXT('D:\project\jianguiyuan\data\BaiduMap_cityCode_1102.txt')
title = [0]
for i in range(1, 327):
obj = lines[i].split(',')
title.append(obj[1])
def writeTitle(riqi):
writeOneCSV(title,dir+'各城市迁入矩阵'+ "_" + riqi +'.csv')
writeOneCSV(title,dir+'各城市迁出矩阵'+ "_" + riqi +'.csv')
# writeOneCSV(title,dir+'各省份迁入矩阵'+ "_" + riqi +'.csv')
# writeOneCSV(title,dir+'各省份迁出矩阵'+ "_" + riqi +'.csv')
# 先将数据下载为json文件
def city_range(n,riqi):
shengqianru = []
shengqianchu = []
titles = title
for i in range(n, 327):
qianru = []
qianchu = []
# print(i)
# 把城市id号和城市名分开
obj = lines[i].split(',')
# print(obj[1])
fileline = readTXT("城市迁入_" + obj[1] + "_" + riqi + ".json")
ner = fileline[0].replace('\\','')
pat = '{"city_name":"(.*?)","province_name":".*?","value":.*?}'
pat1 = '{"city_name":".*?","province_name":".*?","value":(.*?)}'
city_name = re.compile(pat).findall(ner)
value = re.compile(pat1).findall(ner)
qianru.append(obj[1])
combine = []
# 获取每一列对应的索引
for name in city_name:
for k in range(1, len(title)):
if title[k] == name:
combine.append(title.index(name))
# 获取数组索引所对应的值
for m in range(1,327):
if m in combine:
col_value = value[combine.index(m)]
qianru.append(float(col_value))
else:
qianru.append(0)
fileline = readTXT("城市迁出_" + obj[1] + "_" + riqi + ".json")
fileline[0] = fileline[0].replace('\\', '')
pat = '{"city_name":"(.*?)","province_name":".*?","value":.*?}'
pat1 = '{"city_name":".*?","province_name":".*?","value":(.*?)}'
result2 = re.compile(pat).findall(fileline[0])
result12 = re.compile(pat1).findall(fileline[0])
qianchu.append(obj[1])
combine = []
for name in result2:
for k in range(1, len(title)):
if title[k] == name:
combine.append(title.index(name))
for m in range(1,327):
if m in combine:
col_value = result12[combine.index(m)]
qianchu.append(float(col_value))
else:
qianchu.append(0)
writeOneCSV(qianru, dir + '各城市迁入矩阵' + "_" + riqi + '.csv')
writeOneCSV(qianchu, dir + '各城市迁出矩阵' + "_" + riqi + '.csv')
def date_change(date):
date_list=[]
# 注意这个日期,一个月只有31天,爬取2月份的数据需要重新改
for riqi in range(date, 20200131):
date_list.append(str(riqi))
for riqi in range(20200201, 20200230):
date_list.append(str(riqi))
for riqi in range(20200301, 20200328):
date_list.append(str(riqi))
for riqi in date_list:
print(riqi)
writeTitle(riqi)
city_range(1,riqi)
print("大吉大利,今晚吃鸡啊!")
if __name__ == '__main__':
dir = 'D:\data\人口数据\百度迁徙大数据\最新城市省份流入流出数据\矩阵\\'
date_change(20200101)
其中的参考文件请移步到我的下载
我的下载
如需帮忙处理数据和爬取数据请私聊我。。。