We’ll now learn to generates counts, which you can then use as features into your logistic regression classifier. Specifically, given a word, you want to keep track of the number of times, that’s where it shows up as the positive class. Given another word you want to keep track of the number of times that word showed up in the negative class. Using both these counts, you can then extract features and use those features into your logistic regression classifier. So let’s take a look at how you can do that.
现在我们来学习生成"计数",然后你使用"计数"作为特征进入到你的逻辑回归分类器中。具体的做法是,给定一个单词,你需要记录次数,也就是它出现正类的次数。给定另一个单词你需要记录它出现负类的次数。使用这两种计数,然后你抽取特征,使用这些特征进入到你的逻辑回归分类器中。让我们看下你该怎么做吧。
It is helpful to first imagine how these two classes would look. Here for instance, you could have a corpus consisting of four tweets. Associated with that corpus, you would have a set of unique words, your vocabulary. In this example, your vocabulary would have eight unique words.
首先想象一下这两个类的样子是有帮助的。例如,在这里,你有一个语料库包含4个推特。与这个语料库相关联,你会有一组唯一的单词,你的词汇表。在这个例子中,你的词汇表有8个唯一的单词。

For this particular example of sentiment analysis, you have two classes. One classes associated with positive sentiment and the other with negative sentiment. So taking your corpus, you’d have a set of two tweets that belong to the positive class, and the sets of two tweets that belong to the negative class.
在这个情感分析的例子中,你有两类。一类与积极情绪相关联,另一类带有消极情绪。所以在你的语料库中,你有一组属于正类的2条推特和一组属于负类的2条推特。

Let’s take the sets of positive tweets. Now, take a look at your vocabulary. To get the positive frequency in any word in your vocabulary, you will have to count the times as it appears in the positive tweets. For instance, the word “happy” appears one time in the first positive tweet, and another time in the second positive tweet. So it’s positive frequency is two. The complete table looks like this. Feel free to take a pause and check any of its entries.
让我们以正类为例。现在,看你的语料库。要想在你的词汇表中得到任何一个单词的正频数,你必须计算它出现在正推特中的次数。例如,单词"happy"在第一条正推特中出现一次,另一次在第二条正推特中,所以它的正频数是2。完整的表像这样。请随时暂停并检查其中的任何条目。

The same logic applies for getting the negative frequency. However, for the sake of clarity, look at some example, the word “am” appears two times in the first tweet and another time in the second one. So it’s negative frequency is three. Take a look at the entire table for negative frequencies and feel free to check its values.
同样的逻辑也适用于得到负频数。然而,为了清晰起见,来看一些例子,单词"am"在第一条推特中出现了2次,在第二条推特中有出现了一次。所以它的负频数是3。查看整个表中的负频数,随意检查它的值。

So this is the entire table with the positive and negative frequencies for your corpus. In practice when coding, this table is a dictionary mapping from a word class there to its frequency. So it maps the word and its corresponding class to the frequency or the number of times that’s where it showed up in the class.
这整张表包括了语料库的正频数和负频数。在实际编码时,这个表是一个从一个单词到它频率的字典映射。所以它把单词和她对应的类映射到它在类中出现的频率或次数。
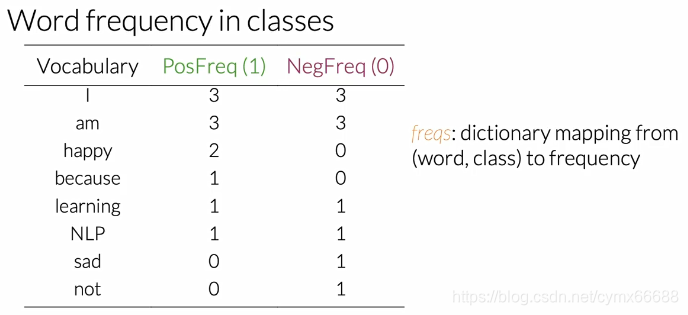
You now know how to create a frequency dictionary,which maps a word and the class to the number of times that word showed up in the corresponding class.
你现在了解了如何创建一个频数字典,它把单词和类映射到单词在相应类出现的次数。