You will now use everything that you learned to create a matrix that corresponds to all the features of your training example. Specifically, I will walk you through an algorithm that allows you to gererate this x matrix. Let’s take a look at how you can build it. Previously, you saw how to preprocess a tweet like this one to get a list of words that contain all the relevant information for the sentiment analysis tasks in NLP. With that list of words, you would be able to get a nice representation using a frequency dictionary mapping. And finally, get a vector with a bias unit and two additional features that store the sum of the number of times that every word on your process tweets appear in positive tweets and the sum of the number of times they appear in negative ones.
你现在使用你所学的一切来创建一个与你的训练示例的所有特征相对应的矩阵。具体来讲,我会带你进入一个算法允许你生成这个x矩阵。让我们看看你怎么创建吧。你先前看到如何预训练一个像这样的推特得到一个单词列表,包含NLP中情感分析任务所有的相关信息。有了这个单词列表,你能够使用频率字典映射得到一个很好的表示。最后,得到一个带有偏差单位的向量和两个额外的特征,用来存储你的进程推特中出现在正推文中的次数之和和它们出现在负推文中的次数之和。

In practice, you would have to perform this process on a set of m tweets. So given a set of multiple raw tweets, you would have to preprocess them one by one to get these sets of lists of words one for each of your tweets. And finally, you’d be able to extract features using a frequencies dictionary mapping.
在实践中,你必须对一组m个推文执行此过程。因此给定一组多个原始推文,你必须一个接一个的对它们进行预处理,已获得每个推文的对应的一组单词列表。最后,你能够使用一个频率字典映射来提取特征。

At the end, you would have a matrix, X with m rows and three columns where every row would contain the features for each one of your tweets.
最后,你会得到一个矩阵X,m行3列,每行会包含你的每一条推特的特征。
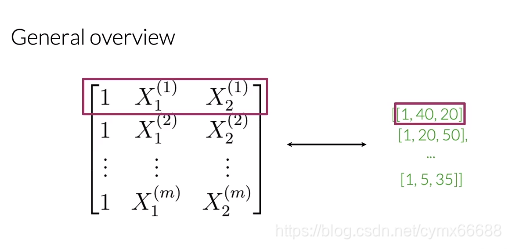
The general implementation of this process is rather easy. First, you build the frequencies dictionary, then initialize the matrix X to match your number of tweets. After that, you’ll want to go over through your sets of tweets carefully deleting stop words, stemming, deleting URLs, and handles and lower casing. And finally, extract the features by summing up the positive and negative frequencies of the tweets. For this week’s assignment, you’ve been provided some helper funitons, build_frequs and process_tweet. However, you’ll have to implement the function to extract the features of a single tweet.
这个过程的综合实现是比较容易的。首先,你创建频率字典,然后初始化矩阵X来匹配你的推文个数。之后,你需要仔细检查你的一组推文,删除停用词、词干,删除URL、@,和小写转换。最后,通过对推文的正向频率和负向频率求和来提取特征。这周的设计,已经提供了一些帮助函数,build_frequs和process_tweet。然而,你必须实现提取单个推文特征的函数。

That was a lot of code, but at least now you have your X matrix. And in the next video, we will show you how you can feed in that X matix into your logistic regression classifier. Let’s take a look at how you can do that.
有大量代码,但是至少现在你有X矩阵,在下个视频中,我们将给你展示你如何将X矩阵feed到你的逻辑回归分类器中。让我们看下你如何做吧。