
特异性低=误诊率高 敏感性高=漏诊率低
prediction position=TP+FP
正确率(precision) PPV= TP/prediction positive
FDR=FP/ prediction positive
prediction negative=FN+TN
FOR=FN/prediction negative
NFV=TN/ prediction negative
Condition positive=TP+FN condition negative=FP+TN
真阳性率TPR=TP/condition positive 假阳性率FP=FP/condition negative
灵敏度(Sensitivity) 误诊率=1-特异度
召回率(Recall)
假阳性率FNR=FN/condition positive 真阴性率TNR=TN/condition negative
漏诊率=1-灵敏度 特异度(specificity)
(1)真阳性(True Positive,TP): 检测不健康,且实际不健康;正确肯定的匹配数目;
(2)假阳性(False Positive,FP):检测不健康,但实际健康;误报,给出的匹配是不正确
(3)真阴性(True Negative,TN):检测健康,且实际健康;正确拒绝的非匹配数目;
(4)假阴性(False Negative,FN):检测健康,但实际不健康;漏报,没有正确找到的匹配的数目。

敏感性、特异性、假阳性、假阴性(sensitivity and specificity)
医学、机器学习等等,在统计结果时时长会用到这两个指标来说明数据的特性。 定义
敏感性:在金标准判断有病(阳性)人群中,检测出阳性的几率。真阳性(检测出确实有病的能力)
特异性:在金标准判断无病(阴性)人群中,检测出阴性的几率。真阴性(检测出确实没病的能力)
假阳性率:得到了阳性结果,但这个阳性结果是假的。即在金标准判断无病(阴性)人群中,检测出为阳性的几率。(没病,但却检测结果说有病),为误诊率。
假阴性率:得到了阴性结果,但这个阴性结果是假的。即在金标准判断有病(阳性)人群中,检测出为阴性的几率。(有病,但却检测结果说没病),为漏诊率。
计算方法
| True Positive (真正, TP)被模型预测为正的正样本; 可以称作判断为真的正确率 True Negative (真负 , TN)被模型预测为负的负样本;可以称作判断为假的正确率 False Positive (假正, FP)被模型预测为正的负样本; 可以称作误报率 False Negative (假负 , FN)被模型预测为负的正样本;可以称作漏报率 True Positive Rate(真正率,TPR) 或灵敏度(sensitivity) TPR = TP /(TP + FN) 正样本预测结果数/正样本实际数 True Negative Rate(真负率,TNR)或特异度(specificity) TNR = TN /(TN + FP) 负样本预测结果数/负样本实际数 False Positive Rate(假正率,FPR) FPR =FP/(FP+TN) 被预测为正的负样本结果数/负样本实际数 False Negative Rate(假负率,FNR) FNR = FN /(TP + FN) 被预测为负的正样本结果数/正样本实际数 |
|
|
|
金标准 |
金标准 |
|
|
|
|
阳性(+) |
阴性(-) |
合计 |
| 某筛检方法 |
阳性(+) |
a |
b |
a+b |
| 某筛检方法 |
阴性(-) |
c |
d |
c+d |
| 合计 |
|
a+c |
b+d |
N |
假阳性率α=b÷(b+d) 假阳性率=假阳性人数÷金标准阴性人数
(b:筛选为阳性,而标准分类为阴性的例数; d:阴性一致例数)
假阴性率β=c÷(a+c) 假阴性率=假阴性人数÷金标准阳性人数

研究对象是某个事物(疾病),评判的标准是某个准则(诊断的各项指标)。
所谓敏感性,就是发病之后,你的诊断方法对疾病的敏感程度(识别能力),记TP为真阳性发生的概率,FN为假阴性概率,则敏感性为sensitivity=TP/TP+FN
所谓特异性——不发病(我们这里称之为健康)的特征是有别于发病的特征的,我们利用这些差异避免误诊,那么诊断标准对于这些差异利用的如何就用特异性来表示。记TN为真阴性发生概率,FP为假阳性发生概率,则特异性为specificity=TN/TN+FP.
显然,我们希望我们的评判标准(诊断标准)的敏感性和特异性都尽可能地高,这样可以使我们的漏诊率(实际上发病了却认为没病)降低,误诊率(实际上没发病却认为发病了)降低。然而,二者很难兼顾(可以从其他答案中的那个正常人和糖尿病人血糖分布中思考),那么又要如何设立我们的评判标准呢?常用的如
分类准确度(classification accuracy) ![]()
平均错误率(balanced error rate) ![]()
Matthews相关系数(Matthews correlation coefficient)
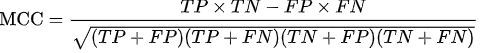 、真实水平α、p-value等。具体的标准还要视情况而定(比如你认为疾病很可怕,宁可信其有,当然要提高评判方法的敏感性,即使牺牲了特异性也认为值得等等,这是另外一个层面的问题了)
、真实水平α、p-value等。具体的标准还要视情况而定(比如你认为疾病很可怕,宁可信其有,当然要提高评判方法的敏感性,即使牺牲了特异性也认为值得等等,这是另外一个层面的问题了)