文章目录
知识点
1. 什么是restful规范
是一套规则,用于程序之间进行数据交换的约定。
他规定了一些协议,对我们感受最直接的的是,以前写增删改查需要写4个接口,restful规范的就是1个接口,根据method的不同做不同的操作,比如:get/post/delete/put/patch/delete.
初次之外,resetful规范还规定了:
- 数据传输通过json
扩展:前后端分离、app开发、程序之间(与编程语言无关)
JSON:
{
name:'alex',
age:18,
gender:'男'
}
以前用webservice,数据传输格式xml。
XML
<name>alex</name>
<age>alex</age>
<gender>男</gender>
2. 什么是drf?
drf是一个基于django开发的组件,本质是一个django的app。
drf可以办我们快速开发出一个遵循restful规范的程序。
3. drf如何帮助我们快速开发的?drf提供了那些功能?
- 视图,APIView用处还不知道。
- 解析器,根据用户请求体格式不同进行数据解析,解析之后放在request.data中。
在进行解析时候,drf会读取http请求头 content-type.
如果content-type:x-www-urlencoded,那么drf会根据 & 符号分割的形式去处理请求体。
user=wang&age=19
如果content-type:application/json,那么drf会根据 json 形式去处理请求体。
{"user":"wang","age":19}
- 序列化,可以对QuerySet进行序列化,也可以对用户提交的数据进行校验。
- 渲染器,可以帮我们把json数据渲染到页面上进行友好的展示。(内部会根据请求设备不同做不同的展示)
4. 序列化:
many=True or False
5. 序列化:展示特殊的数据(choices、FK、M2M)可使用
- depth
- source,无需加括号,在源码内部会去判断是否可执行,如果可执行自动加括号。【fk/choice】
- SerializerMethodField,定义钩子方法。【m2m】
## 扩展
1. restful规范
- URL中一般用名词:
http://www.luffycity.com/article/ (面向资源编程,网络上东西都视为资源) - 根据请求不同做不同操作:GET/POST/PUT/DELTE/PATCH
- 筛选条件,在URL参数中进行传递:
http://www.luffycity.com/article/?page=1&category=1
一般传输的数据格式都是JSON
2. drf组件
…
3. 潜规则:类的约束
4. drf的配置
setting.py
REST_FRAMEWORK = {
…
}
5. 分页
- page
- offset
# 呼啦圈项目
## 创建Django程序
source ~/.bashrc
mkvirtualenv hula_django_framework
workon hula_django_framework
pip install djangorestframework
## drf的配置


## 创建程序并初始化数据库
python manage.py makemigrations
python manage.py migrate

测试api

## drf 增删改查
```py
from django.shortcuts import render
# Create your views here.
from rest_framework.views import APIView
from rest_framework.response import Response
from api import models
from django.forms.models import model_to_dict
class DrfCategory(APIView):
pass
class DrfCategoryView(APIView):
def get(self, request, *args, **kwargs):
"""
获取所有文章列表
"""
pk = kwargs.get('pk')
if not pk:
data = models.Category.objects.all().values('id', 'name')
data_list = list(data)
return Response(data_list)
category_object = models.Category.objects.filter(id=pk).first()
data = model_to_dict(category_object)
return Response(data)
def post(self, request, *args, **kwargs):
"""
增加一条分类信息
"""
# name = request.POST.get('name')
print(request.body)
print(request.data)
models.Category.objects.create(**request.data)
return Response('成功')
def delete(self, request, *args, **kwargs):
"""
删除一条分类信息
"""
pk = kwargs.get('pk')
if not pk:
return Response('请选择删除的 id')
data = models.Category.objects.filter(id=pk).delete()
if data[0] == 0:
return Response('删除--无此数据')
return Response('删除成功')
def put(self, request, *args, **kwargs):
"""
更新一条分类信息
"""
pk = kwargs.get('pk')
if not pk:
return Response('请选择删除的 id')
data = models.Category.objects.filter(id=pk).update(**request.data)
print(data)
if data == 0:
return Response('更新--无此数据')
return Response('更新成功')
到目前为止,使用drf与django不通在于取数据的方式
drf–serializers的序列化与表单验证
我们把变量从内存中变成可存储或传输的过程称之为序列化
把变量内容从序列化的对象重新读到内存里称之为反序列化
class NewCategorySerializer(serializers.ModelSerializer):
"""
序列化
"""
class Meta:
model = models.Category
# fields = "__all__"
fields = ['id', 'name']
class NewCategoryView(APIView):
def get(self, request, *args, **kwargs):
pk = kwargs.get('pk')
print(pk)
if not pk:
queryset = models.Category.objects.all()
ser = NewCategorySerializer(instance=queryset, many=True)
return Response(ser.data)
else:
model_object = models.Category.objects.filter(id=pk).first()
ser = NewCategorySerializer(instance=model_object, many=False)
return Response(ser.data)
def post(self, request, *args, **kwargs):
ser = NewCategorySerializer(data=request.data)
if ser.is_valid():
ser.save()
return Response(ser.data)
return Response(ser.errors)
def put(self, request, *args, **kwargs):
pk = kwargs.get('pk')
category_object = models.Category.objects.filter(id=pk).first()
ser = NewCategorySerializer(instance=category_object,data=request.data)
if ser.is_valid():
ser.save()
return Response(ser.data)
return Response(ser.errors)
def delete(self, request, *args, **kwargs):
"""
删除一条分类信息
"""
pk = kwargs.get('pk')
if not pk:
return Response('请选择删除的 id')
data = models.Category.objects.filter(id=pk).delete()
if data[0] == 0:
return Response('删除--无此数据')
return Response('删除成功')
可以通过继承rest_framework.generics的类来实现上述功能
class NewCategorySerializer(serializers.ModelSerializer):
"""
序列化
"""
class Meta:
model = models.Category
# fields = "__all__"
fields = ['id', 'name']
from rest_framework.generics import ListAPIView, RetrieveAPIView, CreateAPIView, UpdateAPIView, DestroyAPIView
class NewCategoryView(ListAPIView, RetrieveAPIView, CreateAPIView, UpdateAPIView, DestroyAPIView):
queryset = models.Category.objects.all()
serializer_class = NewCategorySerializer
drf与django小结

实现对文章的增删改查
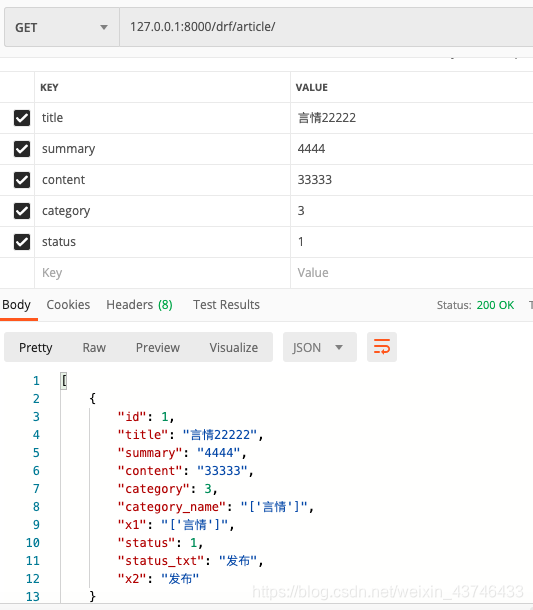
部分字段更新
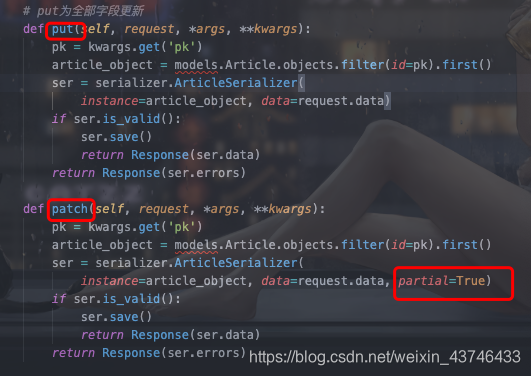
添加返回的字段(choices)
from rest_framework import serializers
from api import models
class ArticleSerializer(serializers.ModelSerializer):
"""
序列化
"""
# 2.添加一个category分类文本字段
category_name = serializers.CharField(source='category.name', required=False)
# 3 get_x1()
x1 = serializers.SerializerMethodField()
x2 = serializers.SerializerMethodField()
# ststus 2.变为中文
status_txt = serializers.CharField(source='get_status_display', required=False)
class Meta:
model = models.Article
fields = ['id', 'title', 'summary', 'content', 'category',
'category_name', 'x1', 'status', 'status_txt', 'x2'] # category category_name可覆盖
# fields = "__all__"
# depth = 1 # 1. 关联表1级关联,2为2级,但不推荐,有多余数据
def get_x1(self, obj):
# obj为Article对象,将category.name返回给x1中
return obj.category.name
# ststus 3.变为中文
def get_x2(self, obj):
return obj.get_status_display()
class ArticleView(APIView):
def get(self, request, *args, **kwargs):
pk = kwargs.get('pk')
if not pk:
queryset = models.Article.objects.all()
ser = serializer.ArticleSerializer(instance=queryset, many=True)
return Response(ser.data)
article_object = models.Article.objects.filter(id=pk).first()
ser = serializer.ArticleSerializer(
instance=article_object, many=False) # 单条记录
return Response(ser.data)
def post(self, request, *args, **kwargs):
ser = serializer.ArticleSerializer(data=request.data)
if ser.is_valid():
ser.save()
return Response(ser.data)
return Response(ser.errors)
# put为全部字段更新
def put(self, request, *args, **kwargs):
pk = kwargs.get('pk')
article_object = models.Article.objects.filter(id=pk).first()
ser = serializer.ArticleSerializer(
instance=article_object, data=request.data)
if ser.is_valid():
ser.save()
return Response(ser.data)
return Response(ser.errors)
def patch(self, request, *args, **kwargs):
pk = kwargs.get('pk')
article_object = models.Article.objects.filter(id=pk).first()
ser = serializer.ArticleSerializer(
instance=article_object, data=request.data, partial=True)
if ser.is_valid():
ser.save()
return Response(ser.data)
return Response(ser.errors)
def delete(self, request, *args, **kwargs):
"""
删除一条分类信息
"""
pk = kwargs.get('pk')
if not pk:
return Response('请选择删除的 id')
data = models.Article.objects.filter(id=pk).delete()
if data[0] == 0:
return Response('删除--无此数据')
return Response('删除成功')
两种分页
drf PageNumberPagination
drf LimitOffsetPagination
# 分页
url(r'^page/article/$', views.PageArticleView.as_view()),
settings.py设置
# 分页
REST_FRAMEWORK = {
"PAGE_SIZE": 2,
# 引入类的路径
"DEFAULT_PAGINATION_CLASS": "rest_framework.pagination.PageNumberPagination"
}
class HulaLimitOffsetPagination(LimitOffsetPagination):
max_limit = 2
class PageArticleView(APIView):
def get(self, request, *args, **kwargs):
queryset = models.Article.objects.all()
# 方式一:仅数据
"""
page_object = PageNumberPagination()
result = page_object.paginate_queryset(queryset,request,self)
ser = PageArticleSerializer(instance=result,many=True)
return Response(ser.data)
"""
# 方式二:数据 + 分页信息
"""
page_object = PageNumberPagination()
result = page_object.paginate_queryset(queryset, request, self)
ser = PageArticleSerializer(instance=result, many=True)
return page_object.get_paginated_response(ser.data)
"""
# 方式三:数据 + 部分分页信息, 如分页页数等等
"""
page_object = PageNumberPagination()
result = page_object.paginate_queryset(queryset, request, self)
ser = PageArticleSerializer(instance=result, many=True)
return Response({'count':page_object.page.paginator.count,'result':ser.data})
"""
# offset=1&limit=2, 从第一条数据后、取两条数据
page_object = HulaLimitOffsetPagination()
result = page_object.paginate_queryset(queryset, request, self)
ser = PageArticleSerializer(instance=result, many=True)
return Response(ser.data)
drf 内置ListAPIView显示列表
urls.py
url(r'^page/view/article/$', views.PageViewArticleView.as_view()),
不再继承drf的APIView, 内部会调用分页
from rest_framework.generics import ListAPIView
class PageViewArticleSerializer(serializers.ModelSerializer):
class Meta:
model = models.Article
fields = "__all__"
class PageViewArticleView(ListAPIView):
queryset = models.Article.objects.all()
serializer_class = PageViewArticleSerializer
REST_FRAMEWORK = { "PAGE_SIZE":2, "DEFAULT_PAGINATION_CLASS":"rest_framework.pagination.PageNumberPagination" }
1.呼啦圈
1.1 表结构设计
- 不会经常变化的值放在内存:choices形式,避免跨表性能低。
- 分表:如果表中列太多/大量内容可以选择水平分表
- 表自关联
外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传
from django.db import models
class UserInfo(models.Model):
""" 用户表 """
username = models.CharField(verbose_name='用户名',max_length=32)
password = models.CharField(verbose_name='密码',max_length=64)
class Article(models.Model):
""" 文章表 """
category_choices = (
(1,'咨询'),
(2,'公司动态'),
(3,'分享'),
(4,'答疑'),
(5,'其他'),
)
category = models.IntegerField(verbose_name='分类',choices=category_choices)
title = models.CharField(verbose_name='标题',max_length=32)
image = models.CharField(verbose_name='图片路径',max_length=128) # /media/upload/....
summary = models.CharField(verbose_name='简介',max_length=255)
comment_count = models.IntegerField(verbose_name='评论数',default=0)
read_count = models.IntegerField(verbose_name='浏览数',default=0)
author = models.ForeignKey(verbose_name='作者',to='UserInfo')
date = models.DateTimeField(verbose_name='创建时间',auto_now_add=True)
class ArticleDetail(models.Model):
article = models.OneToOneField(verbose_name='文章表',to='Article')
content = models.TextField(verbose_name='内容')
class Comment(models.Model):
""" 评论表 """
article = models.ForeignKey(verbose_name='文章',to='Article')
content = models.TextField(verbose_name='评论')
user = models.ForeignKey(verbose_name='评论者',to='UserInfo')
# 评论自关联
# parent = models.ForeignKey(verbose_name='回复',to='self', null=True,blank=True)
2. 筛选
案例:在文章列表时候,添加筛选功能。
- 全部:http://127.0.0.1:8000/hg/article/
- 筛选:http://127.0.0.1:8000/hg/article/?category=2
class ArticleView(APIView):
""" 文章视图类 """
def get(self,request,*args,**kwargs):
""" 获取文章列表 """
pk = kwargs.get('pk')
if not pk:
condition = {}
category = request.query_params.get('category')
if category:
condition['category'] = category
queryset = models.Article.objects.filter(**condition).order_by('-date')
pager = PageNumberPagination()
result = pager.paginate_queryset(queryset,request,self)
ser = ArticleListSerializer(instance=result,many=True)
return Response(ser.data)
article_object = models.Article.objects.filter(id=pk).first()
ser = PageArticleSerializer(instance=article_object,many=False)
return Response(ser.data)
drf的组件:内置了筛选的功能
from django.shortcuts import render
from rest_framework.views import APIView
from rest_framework.response import Response
from . import models
from rest_framework.filters import BaseFilterBackend
class MyFilterBackend(BaseFilterBackend):
def filter_queryset(self, request, queryset, view):
val = request.query_params.get('cagetory')
return queryset.filter(category_id=val)
class IndexView(APIView):
def get(self,request,*args,**kwargs):
# http://www.xx.com/cx/index/
# models.News.objects.all()
# http://www.xx.com/cx/index/?category=1
# models.News.objects.filter(category=1)
# http://www.xx.com/cx/index/?category=1
queryset = models.News.objects.all()
obj = MyFilterBackend()
result = obj.filter_queryset(request,queryset,self)
# print(result)
return Response('...')
3. drf视图应用
from rest_framework.generics import GenericAPIView, ListAPIView, CreateAPIView, UpdateAPIView, DestroyAPIView, RetrieveAPIView
from rest_framework.pagination import PageNumberPagination
from rest_framework import serializers
from django.shortcuts import render
from rest_framework.views import APIView
from rest_framework.response import Response
from . import models
from rest_framework.filters import BaseFilterBackend
class MyFilterBackend(BaseFilterBackend):
def filter_queryset(self, request, queryset, view):
val = request.query_params.get('cagetory')
return queryset.filter(category_id=val)
class IndexView(APIView):
def get(self, request, *args, **kwargs):
# http://www.xx.com/cx/index/
# models.News.objects.all()
# http://www.xx.com/cx/index/?category=1
# models.News.objects.filter(category=1)
# http://www.xx.com/cx/index/?category=1
# queryset = models.News.objects.all()
# obj = MyFilterBackend()
# result = obj.filter_queryset(request,queryset,self)
# print(result)
return Response('...')
class NewFilterBackend(BaseFilterBackend):
def filter_queryset(self, request, queryset, view):
val = request.query_params.get('cagetory')
return queryset.filter(category_id=val)
class NewSerializers(serializers.ModelSerializer):
class Meta:
model = models.News
fields = "__all__"
"""
class NewsView(GenericAPIView):
queryset = models.News.objects.all()
filter_backends = [NewFilterBackend,]
serializer_class = NewSerializers
pagination_class = PageNumberPagination
def get(self,request,*args,**kwargs):
v = self.get_queryset()
queryset = self.filter_queryset(v)
data = self.paginate_queryset(queryset)
ser = self.get_serializer(instance=data,many=True)
return Response(ser.data)
"""
class NewsView(ListAPIView):
queryset = models.News.objects.all()
filter_backends = [NewFilterBackend, ]
serializer_class = NewSerializers
pagination_class = PageNumberPagination
# #########################################################
class TagSer(serializers.ModelSerializer):
class Meta:
model = models.Tag
fields = "__all__"
class TagView(ListAPIView, CreateAPIView):
queryset = models.Tag.objects.all()
serializer_class = TagSer
# def get_serializer_class(self):
# # self.request
# # self.args
# # self.kwargs
# if self.request.method == 'GET':
# return TagSer
# elif self.request.method == 'POST':
# return OtherTagSer
# def perform_create(self,serializer):
# serializer.save(author=1)
class TagDetailView(RetrieveAPIView, UpdateAPIView, DestroyAPIView):
queryset = models.Tag.objects.all()
serializer_class = TagSer
resful规范补充
-
建议用https代替http
-
在URL中体现api,添加api标识
- https://www.cnblogs.com/xwgblog/p/11812244.html # 错误
- https://www.cnblogs.com/api/xwgblog/p/11812244.html # 正确
- https://api.cnblogs.com/xwgblog/p/11812244.html # 正确
- 建议:https://www.cnblogs.com/api/…
-
在URL中要体现版
- https://www.cnblogs.com/api/v1/userinfo/
- https://www.cnblogs.com/api/v2/userinfo/
-
一般情况下对于api接口,用名词不用动词。 https://www.cnblogs.com/api/v1/userinfo/
-
如果有条件的话,在URL后面进行传递。 https://www.cnblogs.com/api/v1/userinfo/?page=1&category=2
-
根据method不同做不同操作 get/post/put/patch/delete
request请求对象封装
API版本
局部版本控制
- urls.py
urlpatterns += [ url(r'^api/(?P<version>\w+)/', include('kka.urls')), ] - settings.py
REST_FRAMEWORK = { "PAGE_SIZE":2, "DEFAULT_PAGINATION_CLASS":"rest_framework.pagination.PageNumberPagination", "DEFAULT_VERSIONING_CLASS":"rest_framework.versioning.URLPathVersioning", "ALLOWED_VERSIONS":['v1','v2'], 'VERSION_PARAM':'version', "DEFAULT_AUTHENTICATION_CLASSES":["kka.auth.TokenAuthentication",] } - view.py
from rest_framework.views import APIView
from rest_framework.response import Response
from rest_framework.request import Request
from rest_framework.versioning import URLPathVersioning
class OrderView(APIView):
versioning_class = URLPathVersioning
def get(self,request,*args,**kwargs):
print(request.version)
print(request.versioning_scheme)
return Response('...')
def post(self,request,*args,**kwargs):
return Response('post')
全局
REST_FRAMEWORK = {
"PAGE_SIZE":2,
"DEFAULT_PAGINATION_CLASS":"rest_framework.pagination.PageNumberPagination",
设置全局
"DEFAULT_VERSIONING_CLASS":"rest_framework.versioning.URLPathVersioning",
"ALLOWED_VERSIONS":['v1','v2'],
'VERSION_PARAM':'version',
"DEFAULT_AUTHENTICATION_CLASSES":["kka.auth.TokenAuthentication",]
}