一、list
name_list = [“zhangsan”,“lisi”,“wangwu”]
1.取值和取索引
print(name_list[0])
知道数据的内容,想确定数据在列表中的位置
使用index方法需要注意,如果传递的数据不在列表中,程序会报错!
print(name_list.index(“wangwu”))
2.修改
name_list[1] = “李四”
列表指定的索引超出范围,程序会报错!list assignment index out of range
name_list[3] = “王小二”
3.增加
append方法可以向列表的末尾追加数据
name_list.append(“王小二”)
insert方法可以在列表的指定索引位置插入数据

name_list.insert(1,“小美眉”)
extend 方法可以把其他列表中的完整内容,追加到当前列表的末尾
temp_list = [“孙悟空”,“猪二哥”,“沙师弟”]
name_list.extend(temp_list)
4.删除
#remove 方法可以从列表删除指定的数据
name_list.remove(“wangwu”)
name_list.pop()
#pop 方法可以指定要删除元素的索引
name_list.pop(3)
5.clear 可以清空列表
name_list.clear()
print(name_list)
二、ndrary
python中的list是python的内置数据类型,list中的数据类不必相同的,而array的中的类型必须全部相同。在list中的数据类型保存的是数据的存放的地址,简单的说就是指针,并非数据,这样保存一个list就太麻烦了,例如list1=[1,2,3,‘a’]需要4个指针和四个数据,增加了存储和消耗cpu。
numpy中封装的array有很强大的功能,里面存放的都是相同的数据类型
1、使用numpy生成数组,得到ndarray的类型
t1 = np.array([1,2,3])
t2= np.array(range(10))
t3 = np.arange(10)
t4 = np.arange(4,10,2) # 左闭右开
2、 numpy中的数据类型
t5 = np.array(range(1,4),dtype=“i1”)
#numpy中的bool类型
t6= np.array([1,1,0,1,0,0],dtype=bool)
3、调整数据类型
t7 = t6.astype(“int8”)
4、numpy中的小数
t8 = np.array([random.random() for i in range(10)])
t9 = np.round(t8,2)
5、取值
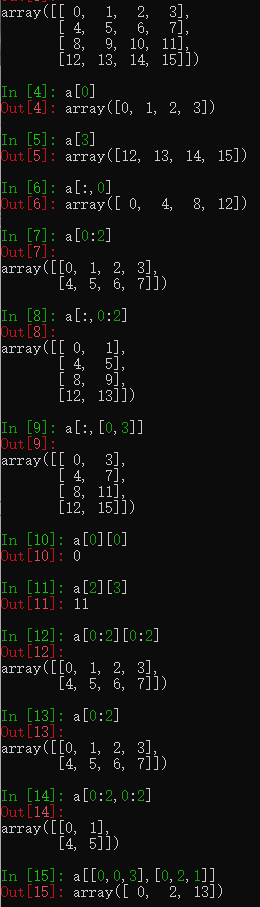
上图是对array取行、多行、取列、取连续多列及不连续多列、取行和列交叉的位置,取多个不相邻的点(0,0)
(0,2)(3,1)
三、Series
1、创建

2、取值和索引

上图对c=pd.Series([1,2,3,4,5,6,7,8,9],index=list(“ABCDEFGHI”))进行取值和索引。
切片:直接传入start end或者步长即可
索引:一个的时候直接传入序号或者index,多个的时候传入序号的列表或者index的列表
四、DataFrame
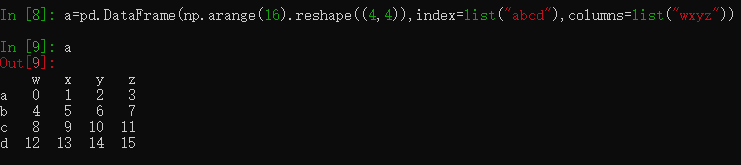
1、创建
2、基本属性

a.shape # 行数 列数
a.dtypes # 列数据类型
a.ndim # 数据维度
a.index # 行索引
a.columns # 列索引
a.values # 对象值,二维ndarray数组
a.head(2) # 显示头部几行,默认5行
a.tail(2) # 显示末尾几行,默认5行
a.info() # 相关信息概览:行数,列数,列索引,列非空值个数,列类型,列类型,内存占用
a.describe() # 快速综合统计结果:计数,均值,标准差,最大值,
四分位数,最小值
3、取值和索引
值得一提的是:DataFrame可以通过a.[“列名”]的方式来取列,实际应用中相对方便。


