Author: Lijb
Email: [email protected]
WeChat: ljb1121
- 背景
2013~2014 年,以 Cloud Foundry 为代表的 PaaS 项目,逐渐完成了教育用户和开拓市场的艰巨任务,也正是在这个将概念逐渐落地的过程中,应用“打包”困难这个问题,成了整个后端 技术圈子的一块心病。
Docker 项目的出现,则为这个根本性的问题提供了一个近乎完美的解决方案。这正是 Docker 项目刚刚开源不久,就能够带领一家原本默默无闻的 PaaS 创业公司脱颖而出,然后迅速占领了所有云计算领域头条的技术原因。
而在成为了基础设施领域近十年难得一见的技术明星之后,dotCloud 公司则在 2013 年底大胆改名为 Docker 公司。不过,这个在当时就颇具争议的改名举动,也成为了日后容器技术圈风云 变幻的一个关键伏笔。
- Docker
Docker 项目在短时间内迅速崛起的三个重要原因:
1. Docker 镜像通过技术手段解决了 PaaS 的根本性问题;
2. Docker 容器同开发者之间有着与生俱来的密切关系;
3. PaaS 概念已经深入人心的完美契机。
崭露头角的 Docker 公司,也终于能够以一个更加强硬的姿态来面对这个曾经无比强势,但现在 却完全不知所措的云计算市场。而 2014 年底的 DockerCon 欧洲峰会,则正式拉开了 Docker 公司扩张的序幕。
容器与进程
- 容器
容器,其实是一种特殊的进程
Docker实际上是在创建容器进程时,指定了这个进程 所需要启用的一组 Namespace 参数。这样,容器就只能“看”到当前 Namespace 所限定的 资源、文件、设备、状态,或者配置。而对于宿主机以及其他不相关的程序,它就完全看不到 了。
所以说,容器,其实是一种特殊的进程而已。
- 容器化技术的Namespace机制
其实只是 Linux 创建新进程的一个可选参数。在 Linux 系统中创建线程的系统调用是 clone(),比如:
int pid = clone(main_function, stack_size, SIGCHLD, NULL);
2. 这个系统调用就会为我们创建一个新的进程,并且返回它的进程号 pid。
3. 而当我们用 clone() 系统调用创建一个新进程时,就可以在参数中指定 CLONE_NEWPID 参数,比如:
int pid = clone(main_function, stack_size, CLONE_NEWPID | SIGCHLD, NULL);
4. 新创建的这个进程将会“看到”一个全新的进程空间,在这个进程空间里,它的 PID 是 1。之所以说“看到”,是因为这只是一个“障眼法”,在宿主机真实的进程空间里,这个进程 的 PID 还是真实的数值,比如 100。
5. 我们还可以多次执行上面的 clone() 调用,这样就会创建多个 PID Namespace,而每个 Namespace 里的应用进程,都会认为自己是当前容器里的第 1 号进程,它们既看不到宿主机 里真正的进程空间,也看不到其他 PID Namespace 里的具体情况。
除了刚刚用到的 PID Namespace,Linux 操作系统还提供了 Mount、UTS、IPC、 Network 和 User 这些 Namespace,用来对各种不同的进程上下文进行“障眼法”操作。
比如,Mount Namespace,用于让被隔离进程只看到当前 Namespace 里的挂载点信息; Network Namespace,用于让被隔离进程看到当前 Namespace 里的网络设备和配置。
总结:
Namespace 技术实际上修改了应用进程看待整个计算机“视图”,即它的“视线”被操作系统做了限制,只能“看到”某些指定的内容,但对于宿主机来说,这些被“隔离”了的进程跟其他进程并没有太大区别
容器的隔离与限制
隔离
Namespace
虚拟机和容器的对比
- 共同点
虚拟机和容器化都可以起到将不同的应用进程相互隔离的作用
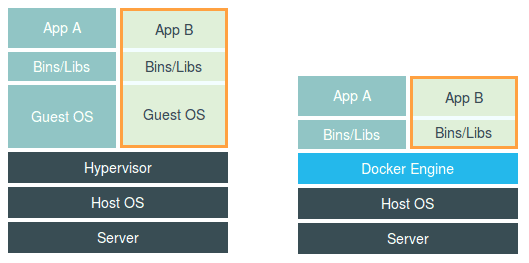
1. 虚拟机: Hypervisor是虚拟机主要的部分。它通过硬件虚拟化功能,模拟出了运行一个操作系统需要的各种硬件,比如 CPU、内存、 I/O 设备等等。然后,它在这些虚拟的硬件上安装了一个新的操作系统,即 Guest OS。
用户的应用进程就可以运行在这个虚拟的机器中,它能看到的自然也只有 Guest OS 的文件和目录,以及这个机器里的虚拟设备。这就是为什么虚拟机也能起到将不同的应用进程相互隔离的作用。
2. 容器: Docker Engine 替换了虚拟机中的 Hypervisor。很多人会把 Docker 项目称为“轻量级”虚拟化技术的原因,实际上就是把虚拟机的概念套在了容 器上。
3. 说明:
Namespace在使用 Docker 的时候,并没有一个真正的“Docker 容器”运行在宿主机里面。Docker 项目帮助用户启动的,还是原来的应用进程,只不过在创建这些进程时,Docker 为它们加上了各种各样的 Namespace 参数。
这时,这些进程就会觉得自己是各自 PID Namespace 里的第 1 号进程,只能看到各自 Mount Namespace 里挂载的目录和文件,只能访问到各自 Network Namespace 里的网络设备,就仿佛运行在一个个“容器”里面,与世隔绝。
Docker 项目称为“轻量级”虚拟化技术,当然该说法不严谨。
- 不同点
1. “敏捷”和“高性能”是容器相较于虚拟机大的优势,也是它能够在 PaaS 这种更细粒度的资源管理平台上大行其道的重要原因
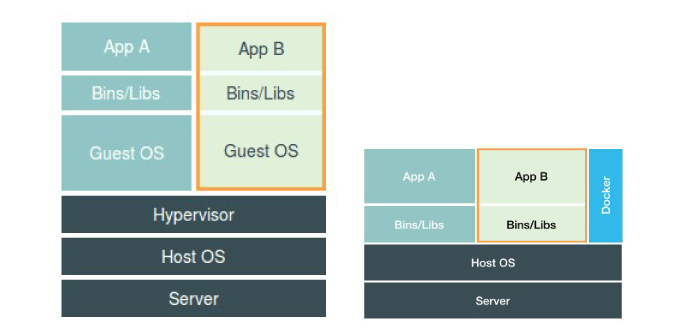
1. Docker Engine并不像 Hypervisor 那样对应用进程的隔离环境负责,也不会创建任何实体的“容器”,正真对隔离环境负责的是宿主机操作系统本身。
2. 所以,在这个对比图里,我们应该把 Docker 画在跟应用同级别并且靠边的位置。这意味着,用 户运行在容器里的应用进程,跟宿主机上的其他进程一样,都由宿主机操作系统统一管理,只不 过这些被隔离的进程拥有额外设置过的 Namespace 参数。而 Docker 项目在这里扮演的角 色,更多的是旁路式的辅助和管理工作。
3. 虚拟化技术作为应用沙盒,就必须要由 Hypervisor 来负责创建虚拟机,这个虚拟机是真实存在的,并且它里面必须运行一个完整的 Guest OS 才能执行用户的应用进程。这就不可避免地带来了额外的资源消耗和占用。
4. 容器只是运行在宿主机上的一种特殊的进程,那么多个容器之间使用的就还是同一个宿主机的操作系统内核。即:共享宿主机内核,因此,容器给应用暴露出来的攻击面是相当大的,应用“越狱”的难度自然也比虚拟机低得多。
5. 在 Linux 内核中,有很多资源和对象是不能被 Namespace 化的,典型的例子就是: 时间。
- 总结虚拟机和容器化的优缺点
1. 虚拟机可以完美的隔离运行进程;但是对计算资源、网络和磁盘 I/O 的损耗非常大。
2. 容器化隔离不彻底;但是不存在真正的docker容器,所占资源可以忽略不计。
3. 虚拟机不仅有模拟出来的硬件机器充当沙盒,而且每个沙盒里还运行着一个完整的 Guest OS。
限制
Cgroups
1. Linux Cgroups 的全称是 Linux Control Group。它主要的作用,就是限制一个进程组能够使用的资源上限,包括 CPU、内存、磁盘、网络带宽等等。
2. Linux Cgroups 的设计还是比较易用的,简单粗暴地理解就是一个子系统目录加上一组资源限制文件的组合。而对于 Docker 等 Linux 容器项目来说,它们只需要在每个子系统下面,为每个容器创建一个控制组(即创建一个新目录),然后在启动容器进程之后,把这个进程 的 PID 填写到对应控制组的 tasks 文件中就可以了
限制进程资源
- 在 Linux 中,Cgroups 给用户暴露出来的操作接口是文件系统,即它以
文件和目录的方式组织 在操作系统的 /sys/fs/cgroup 路径下。在 Ubuntu 16.04 机器里,我可以用 mount 指令把它 们展示出来,这条命令是:
$ mount -t cgroup cpuset on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,cpuset) cpu on /sys/fs/cgroup/cpu type cgroup (rw,nosuid,nodev,noexec,relatime,cpu) cpuacct on /sys/fs/cgroup/cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpuacct) blkio on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,blkio) memory on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,memory)
...
- 可以看到,在 /sys/fs/cgroup 下面有很多诸如 cpuset、cpu、 memory 这样的子目录,也叫 子系统。这些都是这台机器当前可以被 Cgroups 进行限制的资源种类。而在子系统对应的资 源种类下,就可以看到该类资源具体可以被限制的方法。比如,对 CPU 子系统来说,我们就 可以看到如下几个配置文件,这个指令是:
$ ls /sys/fs/cgroup/cpu
cgroup.clone_children cpu.cfs_period_us cpu.rt_period_us cpu.shares notify_on_release cgroup.procs cpu.cfs_quota_us cpu.rt_runtime_us cpu.stat tasks
-
可以看到cfs_period 和 cfs_quota 这样的 关键词。这两个参数需要组合使用,可以用来限制进程在长度为 cfs_period 的一段时间内,只 能被分配到总量为 cfs_quota 的 CPU 时间。
-
创建配置文件
root@ubuntu:/sys/fs/cgroup/cpu$ mkdir container
root@ubuntu:/sys/fs/cgroup/cpu$ ls container/
cgroup.clone_children cpu.cfs_period_us cpu.rt_period_us cpu.shares notify_on_release cgroup.procs cpu.cfs_quota_us cpu.rt_runtime_us cpu.stat tasks
这个目录就称为一个“控制组”。操作系统会在新创建的 container 目录下,自 动生成该子系统对应的资源限制文件。
模拟限制过程
- 执行了一个死循环,可以把计算机的 CPU 吃到 100%,
$ while : ; do : ; done & [1] 226
- 用 top 指令来确认一下 CPU 有没有被打满
$ top %Cpu0 :100.0 us, 0.0 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
# 在输出里可以看到,CPU 的使用率已经 100% 了(%Cpu0 :100.0 us)。
- 通过查看 container 目录下的文件,看到 container 控制组里的 CPU quota 还没有任何限制(即:-1),CPU period 则是默认的 100 ms(100000 us):
$ cat /sys/fs/cgroup/cpu/container/cpu.cfs_quota_us -1 $ cat /sys/fs/cgroup/cpu/container/cpu.cfs_period_us 100000
- 通过修改这些文件的内容来设置限制,比如向 container 组里的 cfs_quota 文件写入 20 ms(20000 us):
$ echo 20000 > /sys/fs/cgroup/cpu/container/cpu.cfs_quota_us
#意味着在每 100 ms 的时间里,被该控制组 限制的进程只能使用 20 ms 的 CPU 时间,也就是说这个进程只能使用到 20% 的 CPU 带宽。
- 把被限制的进程的 PID 写入 container 组里的 tasks 文件,上面的设置就会对该 进程生效了:
$ echo 226 > /sys/fs/cgroup/cpu/container/tasks
- 我们可以用 top 指令查看一下
$ top %Cpu0 : 20.3 us, 0.0 sy, 0.0 ni, 79.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
#可以看到,计算机的 CPU 使用率立刻降到了 20%(%Cpu0 : 20.3 us)
除 CPU 子系统外,Cgroups 的每一项子系统都有其独有的资源限制能力,比如:
blkio,为 块 设 备 设 定 I/O 限制,一般用于磁盘等设备;
cpuset,为进程分配单独的 CPU 核和对应的内存节点;
memory,为进程设定内存使用的限制
Linux Cgroups 的设计还是比较易用的,简单粗暴地理解呢,它就是一个子系统目录加上一组 资源限制文件的组合。而对于 Docker 等 Linux 容器项目来说,它们只需要在每个子系统下面,为每个容器创建一个控制组(即创建一个新目录),然后在启动容器进程之后,把这个进程 的 PID 填写到对应控制组的 tasks 文件中就可以了。
而至于在这些控制组下面的资源文件里填上什么值,就靠用户执行 docker run 时的参数指定 了,比如这样一条命令:
$ docker run -it --cpu-period=100000 --cpu-quota=20000 ubuntu /bin/bash
在启动这个容器后,我们可以通过查看 Cgroups 文件系统下,CPU 子系统中,“docker”这 个控制组里的资源限制文件的内容来确认:
$ cat /sys/fs/cgroup/cpu/docker/5d5c9f67d/cpu.cfs_period_us
100000
$ cat /sys/fs/cgroup/cpu/docker/5d5c9f67d/cpu.cfs_quota_us
20000
#此时就意味着这个 Docker 容器,只能使用到 20% 的 CPU 带宽
- 小结
1. 通过以上讲述,能够理解,一个正在运行的 Docker 容器,其实就是一个启用了多个 Linux Namespace 的应用进程,而这个进程能够使用的资源量,则受 Cgroups 配置的限制。这也是容器技术中一个非常重要的概念,即:容器是一个“单进程”模型。
2. 由于一个容器的本质就是一个进程,用户的应用进程实际上就是容器里 PID=1 的进程,也是其 他后续创建的所有进程的父进程。这就意味着,在一个容器中,你没办法同时运行两个不同的应 用,除非你能事先找到一个公共的 PID=1 的程序来充当两个不同应用的父进程,这也是为什么 很多人都会用 systemd 或者 supervisord 这样的软件来代替应用本身作为容器的启动进程。
- 注意事项
跟 Namespace 的情况类似,Cgroups 对资源的限制能力也有很多不完善的地方,被提 及多的自然是 /proc 文件系统的问题。比如:如果在容器里执行 top 指令,就会发现,它显示的信息居然是宿主机的 CPU 和内存数 据,而不是当前容器的数据。造成这个问题的原因就是,/proc 文件系统并不知道用户通过 Cgroups 给这个容器做了什么样 的资源限制,即:/proc 文件系统不了解 Cgroups 限制的存在。在生产环境中,这个问题必须进行修正,否则应用程序在容器里读取到的 CPU 核数、可用内存 等信息都是宿主机上的数据,这会给应用的运行带来非常大的困惑和风险。这也是在企业中,容 器化应用碰到的一个常见问题,也是容器相较于虚拟机另一个不尽如人意的地方。
容器内的文件系统
根据容器的隔离与线制我们知道, /tmp 目录下的内容跟宿主机的内容是一样的,换句话说即使开启了 Mount Namespace,容器进程看到的文件系统也跟宿主机完全一 样。原因是因为只有在“挂载”这个操作发生之后,进程的视图 才会被改变。而在此之前,新创建的容器会直接继承宿主机的各个挂载点。
推导
有一个解决办法:创建新进程时,除了声明要启用 Mount Namespace 之外,我们还可以告诉容器进程,有哪些目录需要重新挂载,就比如这个 /tmp 目录。于是,我 们在容器进程执行前可以添加一步重新挂载 /tmp 目录的操作:
int container_main(void* arg)
{
printf("Container - inside the container!\n");
// 如果你的机器的根目录的挂载类型是 shared,那必须先重新挂载根目录
// mount("", "/", NULL, MS_PRIVATE, "");
mount("none", "/tmp", "tmpfs", 0, "");
execv(container_args[0], container_args);
printf("Something's wrong!\n");
return 1;
}
可以看到,在修改后的代码里,我在容器进程启动之前,加上了一句 mount(“none”, “/tmp”, “tmpfs”, 0, “”) 语句。就这样,我告诉了容器以 tmpfs(内存盘)格式,重新挂载了 /tmp 目录。
- 编译修改后的代码
$ gcc -o ns ns.c
$ ./ns
Parent - start a container!
Container - inside the container!
$ ls /tm
可以看到,这次 /tmp 变成了一个空目录,这意味着重新挂载生效了。我们可以用 mount -l 检 查一下:
$ mount -l | grep tmpfs
none on /tmp type tmpfs (rw,relatime)
可以看到,容器里的 /tmp 目录是以 tmpfs 方式单独挂载的。
因为我们创建的新进程启用了 Mount Namespace,所以这次重新挂载的操作, 只在容器进程的 Mount Namespace 中有效。如果在宿主机上用 mount -l 来检查一下这个挂 载,你会发现它是不存在的:
# 在宿主机上
$ mount -l | grep tmpfs
- 结论
Mount Namespace 跟其他 Namespace 的使用略有不同的地方:它对容器进程视图的 改变,一定是伴随着挂载操作(mount)才能生效。
思考:
每当创建一个新容器时,我希望容 器进程看到的文件系统就是一个独立的隔离环境,而不是继承自宿主机的文件系统。怎么才能做 到这一点呢?
rootfs
在 Linux 操作系统里,有一个名为 chroot 的命令可以帮助你在 shell 中方便地完成这个工作。 顾名思义,它的作用就是帮你“change root file system”,即改变进程的根目录到你指定的 位置。它的用法也非常简单。假设,我们现在有一个 $HOME/test 目录,想要把它作为一个 /bin/bash 进程的根目录。
- 首先,创建一个 test 目录和几个 lib 文件夹
$ mkdir -p $HOME/test
$ mkdir -p $HOME/test/{bin,lib64,lib}
$ cd $T
- 然后,把 bash 命令拷贝到 test 目录对应的 bin 路径下:
$ cp -v /bin/{bash,ls} $HOME/test/bin
- 接下来,把 bash 命令需要的所有 so 文件,也拷贝到 test 目录对应的 lib 路径下。找到 so 文 件可以用 ldd 命令:
$ T=$HOME/test
$ list="$(ldd /bin/ls | egrep -o '/lib.*\.[0-9]')"
$ for i in $list; do cp -v "$i" "${T}${i}"; done
- 最后,执行 chroot 命令,告诉操作系统,我们将使用 $HOME/test 目录作为 /bin/bash 进程 的根目录:
$ chroot $HOME/test /bin/bash
这时,你如果执行 “ls /”,就会看到,它返回的都是 $ HOME/test 目录下面的内容,而不是宿 主机的内容。
更重要的是,对于被 chroot 的进程来说,它并不会感受到自己的根目录已经被“修改”成 $HOME/test 了。
类似于 Linux Namespace 实际上,Mount Namespace 正是基于对 chroot 的不断改良才被发明出来的,它也是 Linux 操作系统里的第一个 Namespace。
当然,为了能够让容器的这个根目录看起来更“真实”,我们一般会在这个容器的根目录下挂载 一个完整操作系统的文件系统,比如 Ubuntu16.04 的 ISO。这样,在容器启动之后,我们在容 器里通过执行 “ls /” 查看根目录下的内容,就是 Ubuntu 16.04 的所有目录和文件。
而这个挂载在容器根目录上、用来为容器进程提供隔离后执行环境的文件系统,就是所谓的“容 器镜像”。它还有一个更为专业的名字,叫作:rootfs(根文件系统)。
所以,一个最常见的 rootfs,或者说容器镜像,会包括如下所示的一些目录和文件,比如 /bin,/etc,/proc 等等:
$ ls
/ bin dev etc home lib lib64 mnt opt proc root run sbin sys tmp usr var
当进入容器之后执行的 /bin/bash,就是 /bin 目录下的可执行文件,与宿主机的 /bin/bash 完全不同。
- 结论
对 Docker 来说,它最核心的原理实际上就是为待创建的用户进程执行如下操作
1. 启用 Linux Namespace 配置;
Linux Namespace保证了容器环境隔离
2. 设置指定的 Cgroups 参数;
Cgroups限制了容器使用资源
3. 切换进程的根目录(Change Root)。
rootfs保证了容器运行环境的一致性,打通了应用在本地开发和远端执行环境之间难以逾越的鸿沟。
Union File System
Docker 公司在实现 Docker 镜像时并没有沿用以前制作 rootfs 的标准流程, 而是做了一个小小的创新:
当然,这个想法不是凭空臆造出来的,而是用到了一种叫作联合文件系统(Union File System)的能力。
Union File System 也叫 UnionFS,最主要的功能是将多个不同位置的目录联合挂载(union mount)到同一个目录下。
- 比如,我现在有两个目录 A 和 B,它们分别有两个文件:
$ tree
.
├── A
│ ├── a
│ └── x
└── B
├── b
└── x
- 然后,我使用联合挂载的方式,将这两个目录挂载到一个公共的目录 C 上
$ mkdir C
$ mount -t aufs -o dirs=./A:./B none ./C
- 这时,我再查看目录 C 的内容,就能看到目录 A 和 B 下的文件被合并到了一起:
$ tree ./C
./C
├── a
├── b
└── x
可以看到,在这个合并后的目录 C 里,有 a、b、x 三个文件,并且 x 文件只有一份。这,就 是“合并”的含义。此外,如果你在目录 C 里对 a、b、x 文件做修改,这些修改也会在对应的 目录 A、B 中生效。
思考:
在 Docker 项目中,又是如何使用这种 Union File System 的呢?
Docker镜像的分层
Docker 从 Docker Hub 上拉取一个 Ubuntu 镜像实际上就是一个 Ubuntu 操作系统的 rootfs,它的内容是 Ubuntu 操作 系统的所有文件和目录。不过,与 rootfs 稍微不同的是,Docker 镜像使用的 rootfs,往往由多个“层”组成:
- 镜像信息
$ docker image inspect ubuntu:latest
...
"RootFS": {
"Type": "layers",
"Layers": [
"sha256:f49017d4d5ce9c0f544c...",
"sha256:8f2b771487e9d6354080...",
"sha256:ccd4d61916aaa2159429...",
"sha256:c01d74f99de40e097c73...",
"sha256:268a067217b5fe78e000..."
]
}
可以看到,这个 Ubuntu 镜像,实际上由五个层组成。这五个层就是五个增量 rootfs,每一层 都是 Ubuntu 操作系统文件与目录的一部分;而在使用镜像时,Docker 会把这些增量联合挂载 在一个统一的挂载点上(等价于前面例子里的“/C”目录)。
这个挂载点就是 /var/lib/docker/aufs/mnt/,比如
/var/lib/docker/aufs/mnt/6e3be5d2ecccae7cc0fcfa2a2f5c89dc21ee30e166be823ceaeba15dce645b3e
不出意外的,这个目录里面正是一个完整的 Ubuntu 操作系统
$ ls /var/lib/docker/aufs/mnt/6e3be5d2ecccae7cc0fcfa2a2f5c89dc21ee30e166be823ceaeba15dce645b3 bin boot dev etc home lib lib64 media mnt opt proc root run sbin srv sys tmp usr var
那么,前面提到的五个镜像层,又是如何被联合挂载成这样一个完整的 Ubuntu 文件系统的呢?
这个信息记录在 AuFS 的系统目录 /sys/fs/aufs 下面。
- 首先,通过查看 AuFS 的挂载信息,我们可以找到这个目录对应的 AuFS 的内部 ID(也叫: si):
$ cat /proc/mounts| grep aufs
none /var/lib/docker/aufs/mnt/6e3be5d2ecccae7cc0fc... aufsrw,relatime,si=972c6d361e6b32ba,di
- 然后使用这个 ID:si=972c6d361e6b32ba,你就可以在 /sys/fs/aufs 下查看被联合挂载在一起的各个层的信息
$ cat /sys/fs/aufs/si_972c6d361e6b32ba/br[0-9]* /var/lib/docker/aufs/diff/6e3be5d2ecccae7cc...=rw /var/lib/docker/aufs/diff/6e3be5d2ecccae7cc...-init=ro+wh /var/lib/docker/aufs/diff/32e8e20064858c0f2...=ro+wh /var/lib/docker/aufs/diff/2b8858809bce62e62...=ro+wh /var/lib/docker/aufs/diff/20707dce8efc0d267...=ro+wh /var/lib/docker/aufs/diff/72b0744e06247c7d0...=ro+wh /var/lib/docker/aufs/diff/a524a729adadedb90...=ro+wh
从这些信息里,我们可以看到,镜像的层都放置在 /var/lib/docker/aufs/diff 目录下,然后被 联合挂载在 /var/lib/docker/aufs/mnt 里面。
而且,从这个结构可以看出来,这个容器的 rootfs 由如下图所示的三部分组成
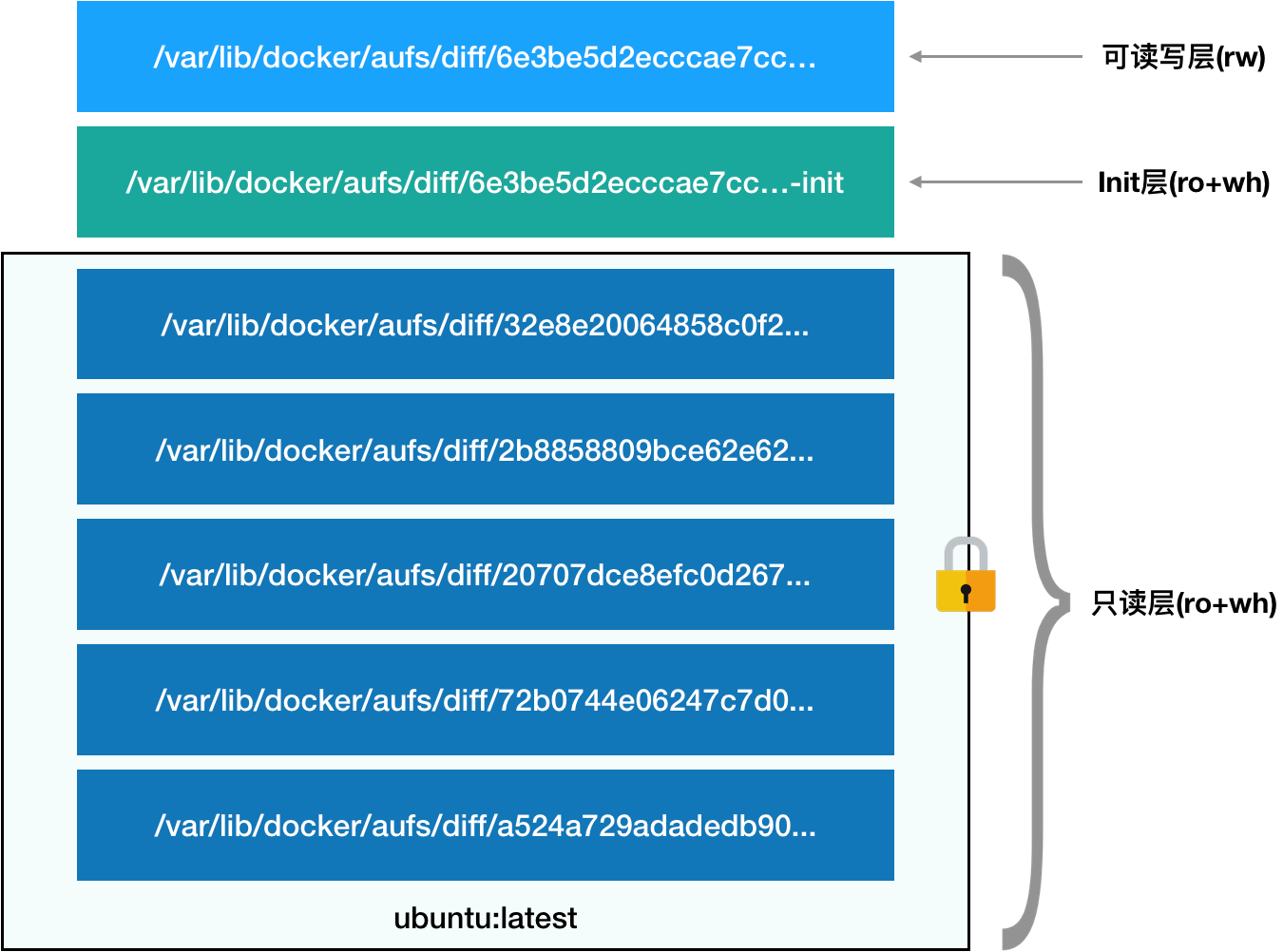
- 第一部分,只读层
只读层是这个容器的 rootfs 最下面的五层,对应的正是 ubuntu:latest 镜像的五层。可以看到,它 们的挂载方式都是只读的(ro+wh,即 readonly+whiteout)。这些层,都以增量的方式分别包含了 Ubuntu 操作系统的一部分
$ ls /var/lib/docker/aufs/diff/72b0744e06247c7d0...
etc sbin usr var
$ ls /var/lib/docker/aufs/diff/32e8e20064858c0f2...
run
$ ls /var/lib/docker/aufs/diff/a524a729adadedb900...
bin boot dev etc home lib lib64 media mnt opt proc root run sbin srv sys tmp usr var
- 第二部分,可读写层
它是这个容器的 rootfs 最上面的一层(6e3be5d2ecccae7cc),它的挂载方式为:rw,即 read write。在没有写入文件之前,这个目录是空的。而一旦在容器里做了写操作,你修改产生 的内容就会以增量的方式出现在这个层中。
可是,你有没有想到这样一个问题:如果我现在要做的,是删除只读层里的一个文件呢?
为了实现这样的删除操作,AuFS 会在可读写层创建一个 whiteout 文件,把只读层里的文 件“遮挡”起来。
比如,你要删除只读层里一个名叫 foo 的文件,那么这个删除操作实际上是在可读写层创建了 一个名叫.wh.foo 的文件。这样,当这两个层被联合挂载之后,foo 文件就会被.wh.foo 文 件“遮挡”起来,“消失”了。这个功能,就是“ro+wh”的挂载方式,即只读 +whiteout 的 含义。我喜欢把 whiteout 形象地翻译为:“白障”。
所以,最上面这个可读写层的作用,就是专门用来存放你修改 rootfs 后产生的增量,无论是 增、删、改,都发生在这里。而当我们使用完了这个被修改过的容器之后,还可以使用 docker commit 和 push 指令,保存这个被修改过的可读写层,并上传到 Docker Hub 上,供其他人 使用;而与此同时,原先的只读层里的内容则不会有任何变化。这,就是增量 rootfs 的好处
- 第三部分,Init 层
它是一个以“-init”结尾的层,夹在只读层和读写层之间。Init 层是 Docker 项目单独生成的一 个内部层,专门用来存放 /etc/hosts、/etc/resolv.conf 等信息。
需要这样一层的原因是,这些文件本来属于只读的 Ubuntu 镜像的一部分,但是用户往往需要 在启动容器时写入一些指定的值比如 hostname,所以就需要在可读写层对它们进行修改。
可是,这些修改往往只对当前的容器有效,我们并不希望执行 docker commit 时,把这些信息 连同可读写层一起提交掉。
所以,Docker 做法是,在修改了这些文件之后,以一个单独的层挂载了出来。而用户执行 docker commit 只会提交可读写层,所以是不包含这些内容的。
最终,这 7 个层都被联合挂载到 /var/lib/docker/aufs/mnt 目录下,表现为一个完整的 Ubuntu 操作系统供容器使用。
走进Docker
。。。。。。。。。。。。。。。后续更新!!!