| 前言
随着云计算的兴起,各大平台之争也落下了帷幕,Kubernetes作为后起之秀已经成为了事实上的PaaS平台标准,而网络又是云计算环境当中最复杂的部分,总是让人琢磨不透。本文尝试着围绕在Kubernetes环境当中同一个节点(work node)上的Pod之间是如何进行网络通信的这个问题进行展开,暂且不考虑跨节点网络通信的情况。
| Network Namespace
Namespace
提到容器就不得不提起容器的核心底层技术Namespace,Namespace为Linux内核当中提供的一种隔离机制,最初在2002年引入到Linux 2.4.19当中,且只有Mount Namespace用于文件系统隔离。截止目前,Linux总共提供了7种Namespace(since Linux 4.6),系统当中运行的每一个进程都与一个Namespace相关联,且该进程只能看到和使用该Namespace下的资源。可以简单将Namespace理解为操作系统对进程实现的一种“障眼法”,比如通过UTS Namespace可以实现让运行在同一台机器上的进程看到不同的Hostname。正是由于Namespace开创性地隔离方式才让容器的实现得以变为可能,才能让我们的软件真正地实现“build once, running everywhere”。

Network Namespace
Network Namespace是Linux 2.6.24才开始引入的,直到Linux 2.6.29才完成的特性。Network Namespace实际上实现的是对网络栈的虚拟化,且在创建出来时默认只有一个回环网络接口lo,每一个网络接口(不管是物理接口还是虚拟化接口)都只能存在于一个Network Namespace当中,但可以在不同的Network Namespace之间切换,每一个Network Namespace都有自己独立的IP地址、路由表、防火墙以及套接字列表等网络相关资源。当删除一个Network Namespace时,其内部的网络资源(网路接口等)也会同时被删掉,而物理接口则会被切换回之前的Network Namespace当中。
由此可以知道不同的两个Network Namespace在网络上是相互隔离的,即不能够直接进行通信,就好比两个相互隔离的局域网之间不能直接通信,那么通过Network Namespace隔离后的容器是如何实现与外部进行通信的呢?
容器与Pod
在Kubernetes的定义当中,Pod为一组不可分离的容器,且共享同一个Network Namespace,故不存在同一个Pod当中容器间网络通信的问题,对于同一个Pod当中的容器来讲,通过Localhost即可与其他的容器进行网络通信。
所以同一个节点上的两个Pod如何进行网络通信的问题可以转变为,同一个节点上的两个容器如何进行网络通信。
Namespace实操

在回答上面提出的Network Namespace网络通信的问题前,我们先来做一些简单的命令行操作,先对Namespace有一个感性地认识,实验环境如下:

通过命令lsns可以查看到宿主机上所有的Namespace(注意需要使用root用户执行,否则可能会出现有些Namespace看不到的情况):

lsns默认会输出所有可以看到的Namespace,简单解释一下lsns命令各个输出列的含义:

与Network Namespace相关性较强的还有另外一个命令 ip netns,主要用于持久化命名空间的管理,包括Network Namespace的创建、删除以和配置等。 ip netns命令在创建Network Namespace时默认会在/var/run/netns目录下创建一个bind mount的挂载点,从而达到持久化Network Namespace的目的,即允许在该命名空间当中没有进程的情况下依然保留该命名空间。Docker当中由于缺少了这一步,玩过Docker的同学就会发现通过Docker创建容器后并不能在宿主机上通过 ip netns查看到相关的Network Namespace(这个后面会讲怎么才能够看到,稍微小操作一下就行)。
与Network Namespace相关操作命令:
ip netns add < namespace name > # 添加network namespace
ip netns list # 查看Network Namespace
ip netns delete < namespace name > # 删除Network Namespace
ip netns exec < namespace name > <command> # 进入到Network Namespace当中执行命令创建名为netA的Network Namespace:

查看创建的Network Namespace:

可以看到Network Namespace netA当中仅有一个环回网络接口lo,且有独立的路由表(为空)。
宿主机(root network namespace)上有网络接口eth0(10.10.88.170)和eth1(172.16.130.164),此时可以直接ping通IP 172.16.130.164。

尝试将root network namespace当中的eth0接口添加到network namespce netA当中:
ip link set dev eth0 netns netA
将宿主机上的网络接口eth0(10.10.88.170)加入到网络命名空间netA后:
1. 宿主机上看不到eth0网络接口了(同一时刻网络接口只能在一个Network Namespace)
2. netA network namespace里面无法ping通root namespace当中的eth1(网络隔离)
从上面的这些操作我们只是知道了Network Namespace的隔离性,但仍然无法达到我们想要的结果,即让两个容器或者说两个不同的Network Namespace进行网络通信。在真实的生活场景中,当我们要连接同一个集团两个相距千里的分公司的局域网时,我们有3种解决方案:第一种是对数据比较随意的,直接走公网连接,但存在网络安全的问题。第二种是不差钱的,直接拉一根专线将两个分公司的网络连接起来,这样虽然远隔千里,但仍然可以处于一个网络当中。另外一种是兼顾网络安全集和性价比的VPN连接,但存在性能问题。很显然,不管是哪一种方案都需要有一根“线”将两端连接起来,不管是虚拟的VPN还是物理的专线。
| vEth(Virtual Ethernet Device)
前面提到了容器通过Network Namespace进行网络隔离,但是又由于Network Namespace的隔离导致两个不同的Network Namespace无法进行通信,这个时候我们联想到了实际生活场景中连接一个集团的两个分公司局域网的处理方式。实际上Linux当中也存在类似像网线一样的虚拟设备vEth(此时是不是觉得Linux简直无所不能?),全称为Virtual Ethernet Device,是一种虚拟的类似于以太网络的设备。
vEth有以下几个特点:
-
vEth作为一种虚拟以太网络设备,可以连接两个不同的Network Namespace。
-
vEth总是成对创建,所以一般叫veth pair。(因为没有只有一头的网线)。
-
vEth当中一端收到数据包后另一端也会立马收到。
-
可以通过ethtool找到vEth的对端接口。(注意后面会用到)
理解了以上几点对于我们后面理解容器间的网络通信就容易多了。
vEth实操
创建vEth:
ip link add < veth name > type veth peer name < veth peer name >创建名为veth0A,且对端为veth0B的vEth设备。

可以看到root network namespace当中多出来了两个网络接口veth0A和veth0B,网络接口名称@后面的接的正是对端的接口名称。
创建Network Namespace netA和netB:
ip netns add netA
ip netns add netB
分别将接口veth0A加入到netA,将接口veth0B加入到netB:
ip link set veth0A netns netA
ip link set veth0B netns netB
这个时候通过IP a查看宿主机(root network namespace)网络接口时可以发现,已经看不到接口veth0A和veth0B了(同一时刻一个接口只能处于一个Network Namespace下面)。
再分别到netA和netB两个Network Namespace当中去查看,可以看到两个Network Namespace当中都多了一个网络接口。
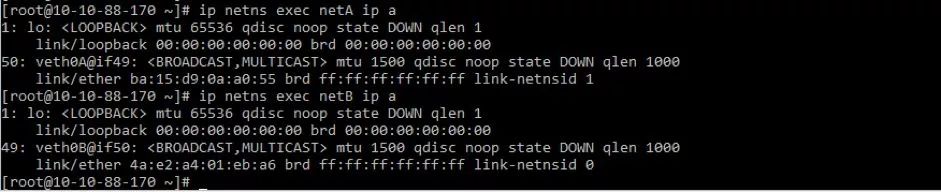
分别拉起两个网络接口并配上IP,这里将为veth0A配置IP 192.168.100.1,veth0B配置IP 192.168.100.2:
ip netns exec netA ip link set veth0A up
ip netns exec netA ip addr add 192.168.100.1/24 dev veth0A
ip netns exec netB ip addr add 192.168.100.2/24 dev veth0B
测试通过veth pair连接的两个Network Namespace netA和netB之间的网络连接。
在netA(192.168.100.1)当中ping netB(192.168.100.2):

在netB(192.168.100.2)当中ping netA(192.168.100.1):

可以发现netA跟netB这两个Network Namespace在通过veth pair连接后已经可以进行正常的网络通信了。
解决了容器Network Namespace隔离的问题,这个时候有云计算经验或者熟悉OpenStack和ZStack的同学就会发现,现在的场景跟虚拟机之间的网络互联是不是简直一模一样了?
vEth作为一个二层网络设备,当需要跟别的网络设备相连时该怎么处理呢?在现实生活场景当中我们会拿一个交换机将不同的网线连接起来。实际上在虚拟化场景下也是如此,Linux Bridge和Open vSwith(OVS)是当下比较常用的两种连接二层网络的解决方案,而Docker当中采用的是Linux Bridge。
| Docker与Kubernetes
Kubernetes作为一个容器编排平台,在容器引擎方面既可以选择Docker也可以选择rkt,这里直接分别通过Docker和Kubernetes创建容器来进行简单比对。 Kubernetes在创建Pod时首先会创建一个pause容器,它的唯一作用就是保留和占据一个被Pod当中所有容器所共享的网络命名空间(Network Namespace),就这样,一个Pod IP并不会随着Pod当中的一个容器的起停而改变。
Docker下的容器网络
我们先来看一下在没有Kubernetes的情况下是什么样子的。在Docker启动的时候默认会创建一个名为docker0的网桥,且默认配置下采用的网络段为172.17.0.0/16,每一个在该节点上创建的容器都会被分配一个在该网段下的IP。容器通过连接到docker0上进行相互通信。
手动创建两个容器:
docker run -it --name testA busybox sh
docker run -it --name testB busybox sh查看网络接口状况。
容器testA:

容器testB:

查看网桥状态:

可以发现docker0上面已经连接了两个虚拟网络接口(vEth)。
在docker0上通过tcpdump抓包:
tcpdump -n -i docker0
可以发现容器testA和容器testB正是通过docker0网桥进行网络包转发的。
加入Kubernetes后的容器网络
其实加入Kubernetes后本质上容器网络通信模式并没有发生变更,但Kubernetes出于网络地址规划的考虑,重新创建了一个网桥cni0用于取代docker0,来负责本节点上网络地址的分配,而实际的网络段管理由Flannel处理。
下面还是以创建2个运行BusyBox镜像的Pod作为例子进行说明。
先给Kubernetes集群当中的两个work node打上label以方便将Pod调度到相同的节点上面进行测试:
[root@10-10-88-192 network]# kubectl get node --show-labels
NAME STATUS ROLES AGE VERSION LABELS
10-10-88-170 Ready <none> 47d v1.10.5-28+187e1312d40a02 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/hostname=10-10-88-170
10-10-88-192 Ready master 47d v1.10.5-28+187e1312d40a02 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/hostname=10-10-88-192,node-role.kubernetes.io/master=
10-10-88-195 Ready <none> 47d v1.10.5-28+187e1312d40a02 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/hostname=10-10-88-195
[root@10-10-88-192 network]#
[root@10-10-88-192 network]# kubectl label --overwrite node 10-10-88-170 host=node1node "10-10-88-170" labeled
[root@10-10-88-192 network]#
[root@10-10-88-192 network]# kubectl label --overwrite node 10-10-88-195 host=node2node "10-10-88-195" labeled
[root@10-10-88-192 network]#
[root@10-10-88-192 network]# kubectl get node --show-labels
NAME STATUS ROLES AGE VERSION LABELS
10-10-88-170 Ready <none> 47d v1.10.5-28+187e1312d40a02 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,host=node1,kubernetes.io/hostname=10-10-88-170
10-10-88-192 Ready master 47d v1.10.5-28+187e1312d40a02 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/hostname=10-10-88-192,node-role.kubernetes.io/master=
10-10-88-195 Ready <none> 47d v1.10.5-28+187e1312d40a02 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,host=node2,kubernetes.io/hostname=10-10-88-195
[root@10-10-88-192 network]#创建两个Pod并通过添加nodeSelector使其调度到同一个节点(host1)。
编辑Pod的yaml配置文件:

基于yaml文件创建Pod:

可以看到两个Pod都按照预期调度到了10-10-88-170这个节点上面。
通过IP a命令可以看到在Pod的宿主机上多出来了2个vethXXX样式的网络接口:
[root@10-10-88-170 ~]# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether fa:35:b6:5e:ac:00 brd ff:ff:ff:ff:ff:ff
inet 10.10.88.170/24 brd 10.10.88.255 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::f835:b6ff:fe5e:ac00/64 scope link
valid_lft forever preferred_lft forever
3: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether fa:88:2a:44:2b:01 brd ff:ff:ff:ff:ff:ff
inet 172.16.130.164/24 brd 172.16.130.255 scope global eth1
valid_lft forever preferred_lft forever
inet6 fe80::f888:2aff:fe44:2b01/64 scope link
valid_lft forever preferred_lft forever
4: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN
link/ether 02:42:43:a1:fc:ad brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/16 scope global docker0
valid_lft forever preferred_lft forever
5: flannel.1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UNKNOWN
link/ether 0e:c4:2c:84:a5:ea brd ff:ff:ff:ff:ff:ff
inet 10.244.2.0/32 scope global flannel.1
valid_lft forever preferred_lft forever
inet6 fe80::cc4:2cff:fe84:a5ea/64 scope link
valid_lft forever preferred_lft forever
6: cni0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UP qlen 1000
link/ether 0a:58:0a:f4:02:01 brd ff:ff:ff:ff:ff:ff
inet 10.244.2.1/24 scope global cni0
valid_lft forever preferred_lft forever
inet6 fe80::f0a0:7dff:feec:3ffd/64 scope link
valid_lft forever preferred_lft forever
9: veth2a69de99@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue master cni0 state UP
link/ether 86:70:76:4f:de:2b brd ff:ff:ff:ff:ff:ff link-netnsid 2
inet6 fe80::8470:76ff:fe4f:de2b/64 scope link
valid_lft forever preferred_lft forever
10: vethc8ca82e9@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue master cni0 state UP
link/ether 76:ad:89:ae:21:68 brd ff:ff:ff:ff:ff:ff link-netnsid 3
inet6 fe80::74ad:89ff:feae:2168/64 scope link
valid_lft forever preferred_lft forever
39: veth686e1634@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue master cni0 state UP
link/ether 66:99:fe:30:d2:e1 brd ff:ff:ff:ff:ff:ff link-netnsid 4
inet6 fe80::6499:feff:fe30:d2e1/64 scope link
valid_lft forever preferred_lft forever
40: vethef16d6b0@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue master cni0 state UP
link/ether c2:7f:73:93:85:fc brd ff:ff:ff:ff:ff:ff link-netnsid 5
inet6 fe80::c07f:73ff:fe93:85fc/64 scope link
valid_lft forever preferred_lft forever
[root@10-10-88-170 ~]#
[root@10-10-88-170 ~]# brctl show
bridge name bridge id STP enabled interfaces
cni0 8000.0a580af40201 no veth2a69de99
veth686e1634
vethc8ca82e9
vethef16d6b0
docker0 8000.024243a1fcad no
[root@10-10-88-170 ~]#此时两个Pod的网络连接如图所示:

网络包从Container A发送到Container B的过程如下:
1. 网络包从busybox1的eth0发出,并通过vethef16d6b0进入到root netns(网络包从vEth的一端发送后另一端会立马收到)。
2. 网络包被传到网桥cni0,网桥通过发送“who has this IP?”的ARP请求来发现网络包需要转发到的目的地(10.244.2.208)。
3. busybox2回答到它有这个IP,所以网桥知道应该把网络包转发到veth686e1634(busybox2)。
4. 网络包到达veth686e1634接口,并通过vEth进入到busybox2的netns,从而完成网络包从一个容器busybox1到另一个容器busybox2的过程。
对于以上流程有疑问的同学也可以自己动手验证一下结论,最好的方式就是通过tcpdump命令在各个网络接口上进行抓包验证,看网络包是如何经过网桥再由veth pair流转到另一个容器网络当中的。
| 结语
容器网络在很大程度上依托于虚拟网络的发展,这也正是技术发展的趋势所在,正所谓站在巨人的肩膀上。
| 作者简介
叶龙宇·沃趣科技研发工程师
主要负责公司基于Kubernetes的RDS平台QFusion的研发, 熟悉云计算及Kubernetes技术体系。