文章目录
一、概述
1.1 Kylin定义
Apache Kylin是一个开源的分布式分析引擎,提供Hadoop/Spark之上的SQL查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由eBay开发并贡献至开源社区。它能在亚秒内查询巨大的Hive表。
1.2 Kylin术语
①Data Warehouse(数据仓库)
数据仓库是一个各种数据(包括历史数据和当前数据)的中心存储系统,是BI( business intelligence 商业智能)的核心部件。
这里所谈的数据包括来自企业业务系统的订单、库存、交易账目、客户和供应商等来自企业所处行业和竞争对手的数据以及来自企业所处的其他外部环境中的各种数据。
②Business Intelligence(商业智能)
商业智能通常被理解为将企业中现有的数据转化为知识,帮助企业做出明智的业务经营决策的工具。
为了将数据转化为知识,需要利用数据仓库、联机分析处理(OLAP)工具和数据挖掘等技术。
③OLAP(online analytical processing)
OLAP是一种软件技术,它使分析人员能够迅速、一致、交互地从各个方面观察信息,以达到深入理解数据的目的。从各方面观察信息,也就是从不同的维度分析数据,因此OLAP也成为多维分析。
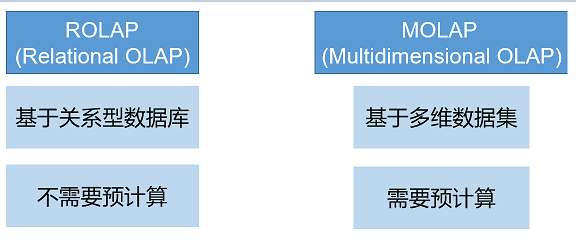
两种OLAP类型:
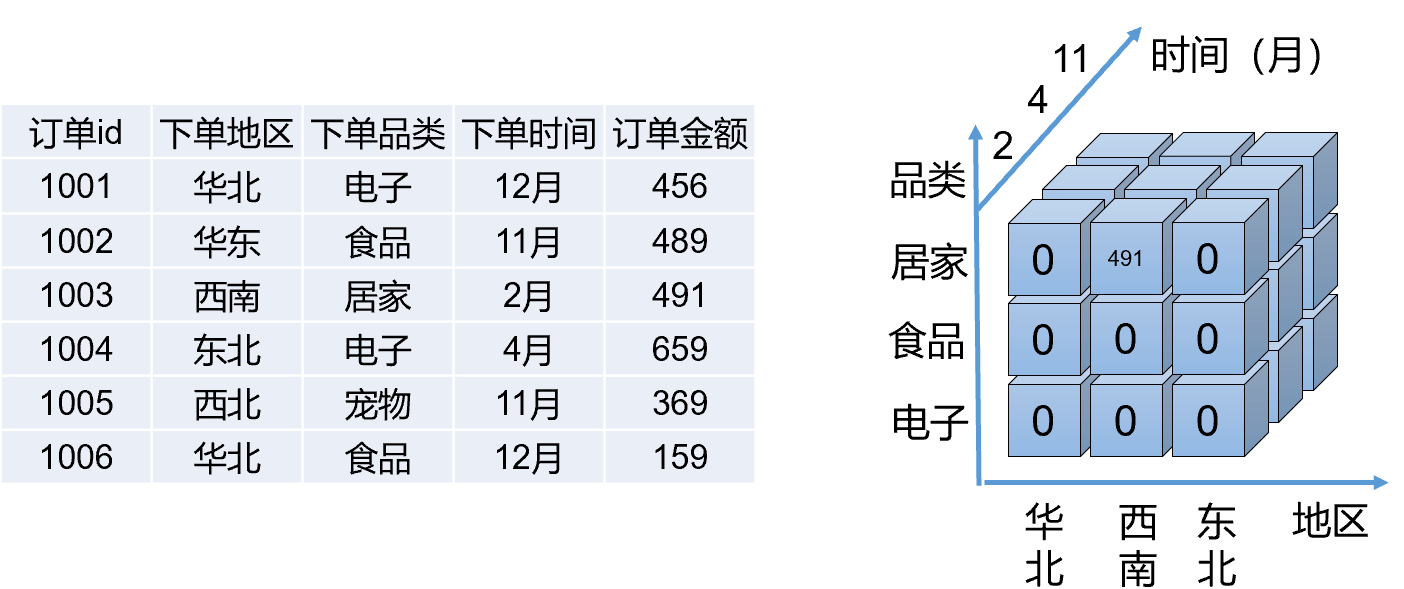
④OLAP Cube
MOLAP基于多维数据集,一个多维数据集称为一个OLAP Cube。
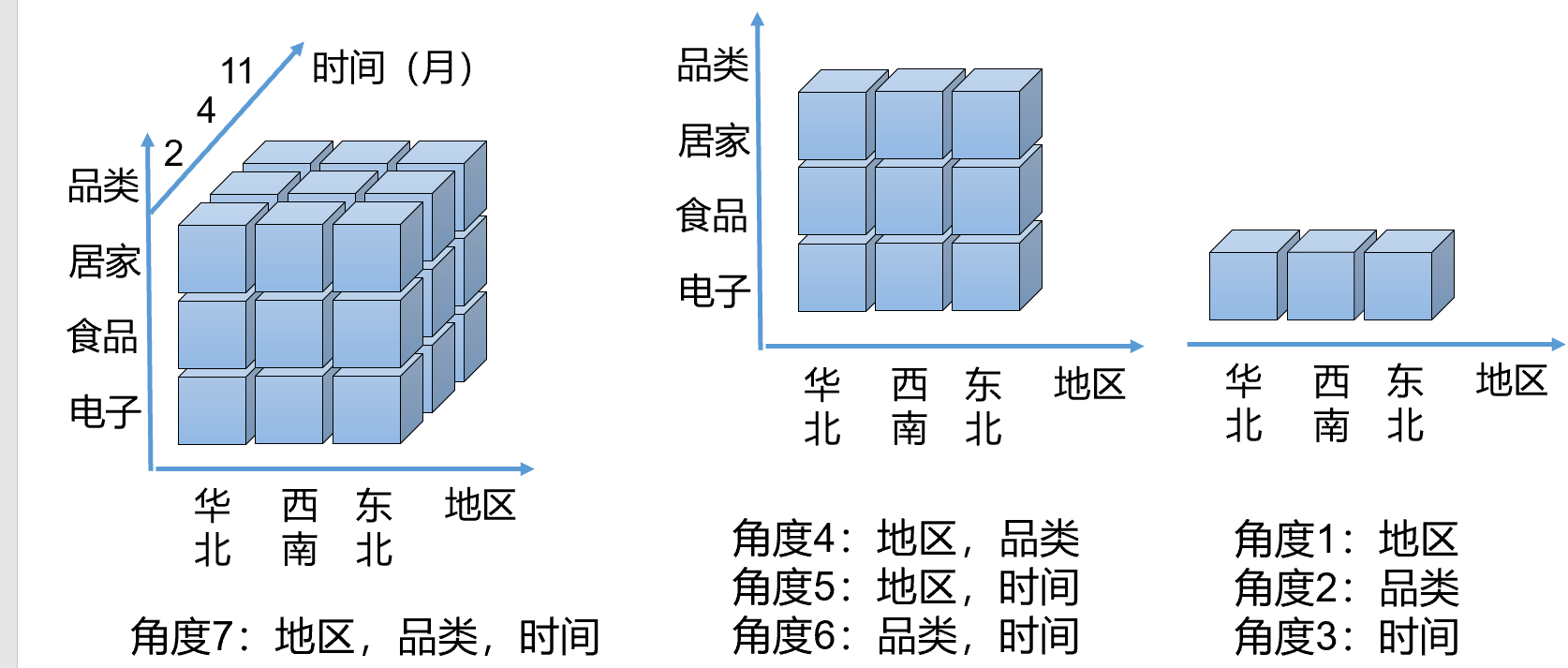
⑤Star Schema(星型模型)
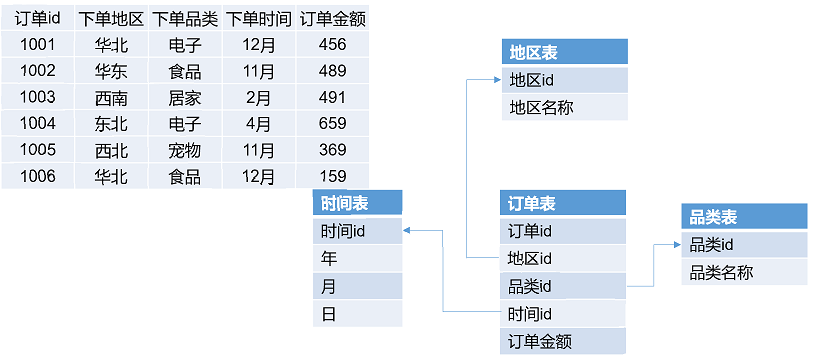
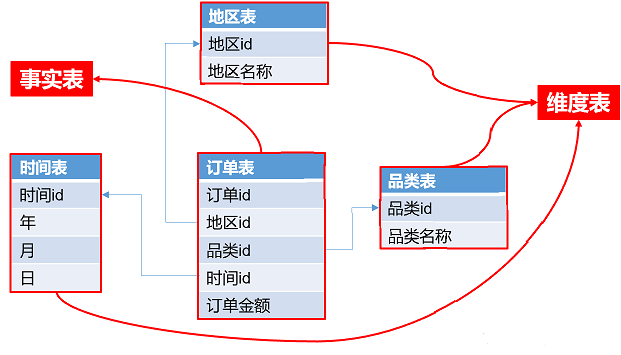
⑥Fact Table(事实表)& Dimension Table(维度表)
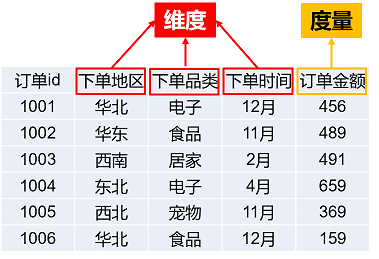
⑦Dimension(维度)& Measure(度量)
维度:分析数据的数据的角度
度量:被分析的指标
1.3 Kylin架构
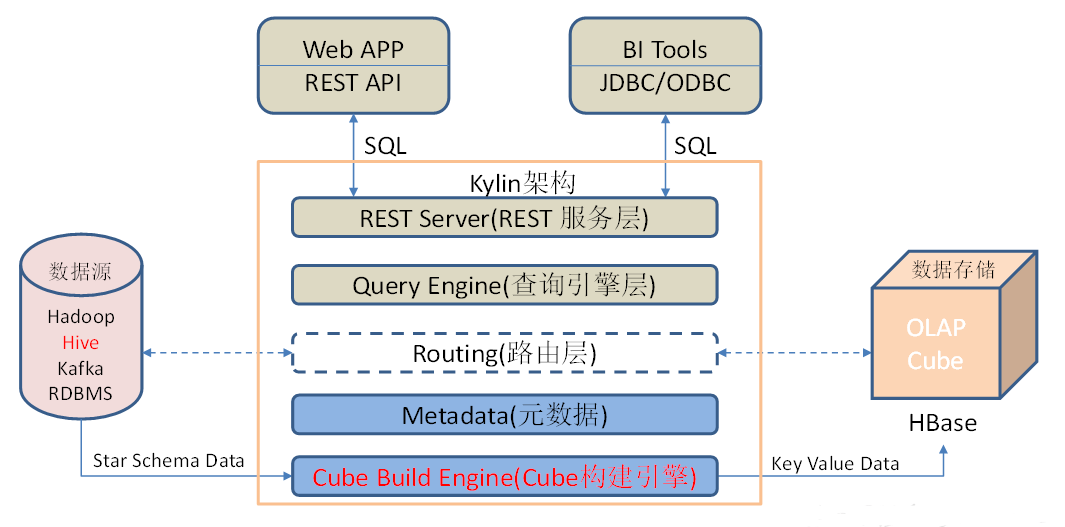
①REST Server
REST Server是一套面向应用程序开发的入口点,旨在实现针对Kylin平台的应用开发工作。 此类应用程序可以提供查询、获取结果、触发cube构建任务、获取元数据以及获取用户权限等等。另外可以通过Restful接口实现SQL查询。
②查询引擎(Query Engine)
当cube准备就绪后,查询引擎就能够获取并解析用户查询。它随后会与系统中的其它组件进行交互,从而向用户返回对应的结果。
③路由器(Routing)
在最初设计时曾考虑过将Kylin不能执行的查询引导去Hive中继续执行,但在实践后发现Hive与Kylin的速度差异过大,导致用户无法对查询的速度有一致的期望,很可能大多数查询几秒内就返回结果了,而有些查询则要等几分钟到几十分钟,因此体验非常糟糕。最后这个路由功能在发行版中默认关闭。
④元数据管理工具(Metadata)
Kylin是一款元数据驱动型应用程序。元数据管理工具是一大关键性组件,用于对保存在Kylin当中的所有元数据进行管理,其中包括最为重要的cube元数据。其它全部组件的正常运作都需以元数据管理工具为基础。 Kylin的元数据存储在HBase中。
⑤任务引擎(Cube Build Engine)
这套引擎的设计目的在于处理所有离线任务,其中包括Shell脚本、Java API以及MapReduce任务等等。任务引擎对Kylin当中的全部任务加以管理与协调,从而确保每一项任务都能得到切实执行并解决其间出现的故障。
二、Kylin安装
①解压apache-kylin-2.5.1-bin-hbase1x.tar.gz到/opt/module
[root@hadoop100 sorfware]# tar -zxvf apache-kylin-2.5.1-bin-hbase1x.tar.gz \
-C /opt/module/
②环境准备
环境变量(缺一不可):
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_144
export PATH=$PATH:$JAVA_HOME/bin
#Hadoop
export HADOOP_HOME=/opt/module/hadoop-2.7.2
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
#Kafka
export KAFKA_HOME=/opt/module/kafka-0.11.0.2
export PATH=$PATH:$KAFKA_HOME/bin
#HBase
export HBASE_HOME=/opt/module/hbase-1.3.1
export PATH=$PATH:$HBASE_HOME/bin
#Hive
export HIVE_HOME=/opt/module/hive-1.2.1
export PATH=$PATH:$HIVE_HOME/bin
export HIVE_CONF=/opt/module/hive-1.2.1/conf
export PATH=$PATH:$HIVE_CONF
export HCAT_HOME=/opt/module/hive-1.2.1/hcatalog
export PATH=$PATH:$HCAT_HOME
export HIVE_LIB=/opt/module/hive-1.2.1/lib
export PATH=$PATH:$HIVE_LIB
#Kylin
export KYLIN_HOME=/opt/module/kylin-2.5.1
export PATH=$PATH:$KYLIN_HOME/bin
若启动报错java.io.IOException: java.net.UnknownHostException: hadoop100:2181,删掉HBase配置文件hbase-site.xml下配置ZooKeeper的端口号

注意:启动Kylin之前要保证HDFS,YARN,ZK,HBASE相关进程是正常运行的。
③启动Kylin
[root@hadoop100 kylin-2.5.1]# bin/kylin.sh start
④访问http://hadoop100:7070/kylin查看Web页面
默认用户名:admin,密码:KYLIN
三、快速入门
3.1 创建项目
创建工程:
选择数据源:
输入作为数据源的表:

3.2 创建Model
点击New按钮后点击New Model:
填写Model名称及描述后Next:
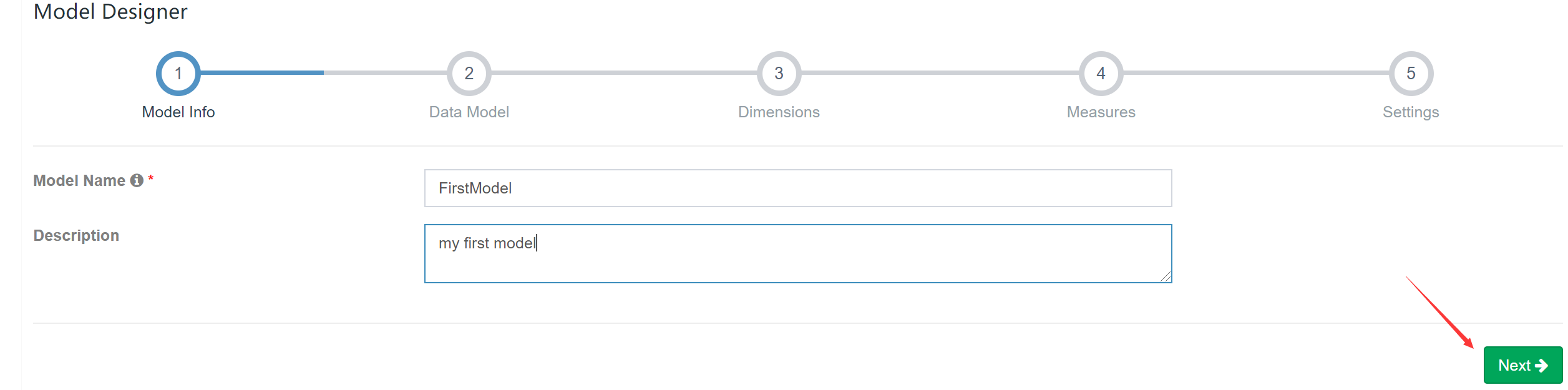
选择事实表:
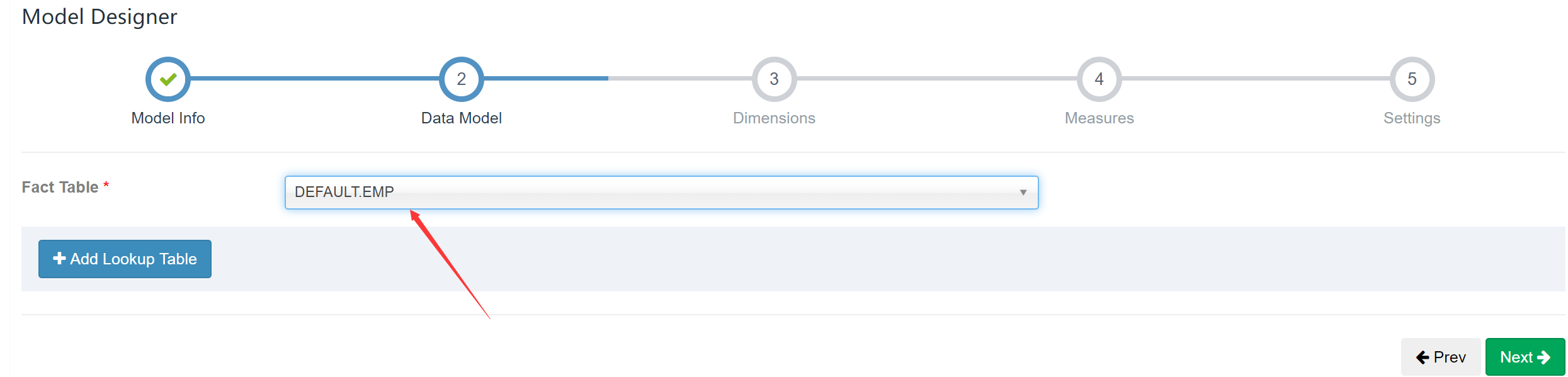
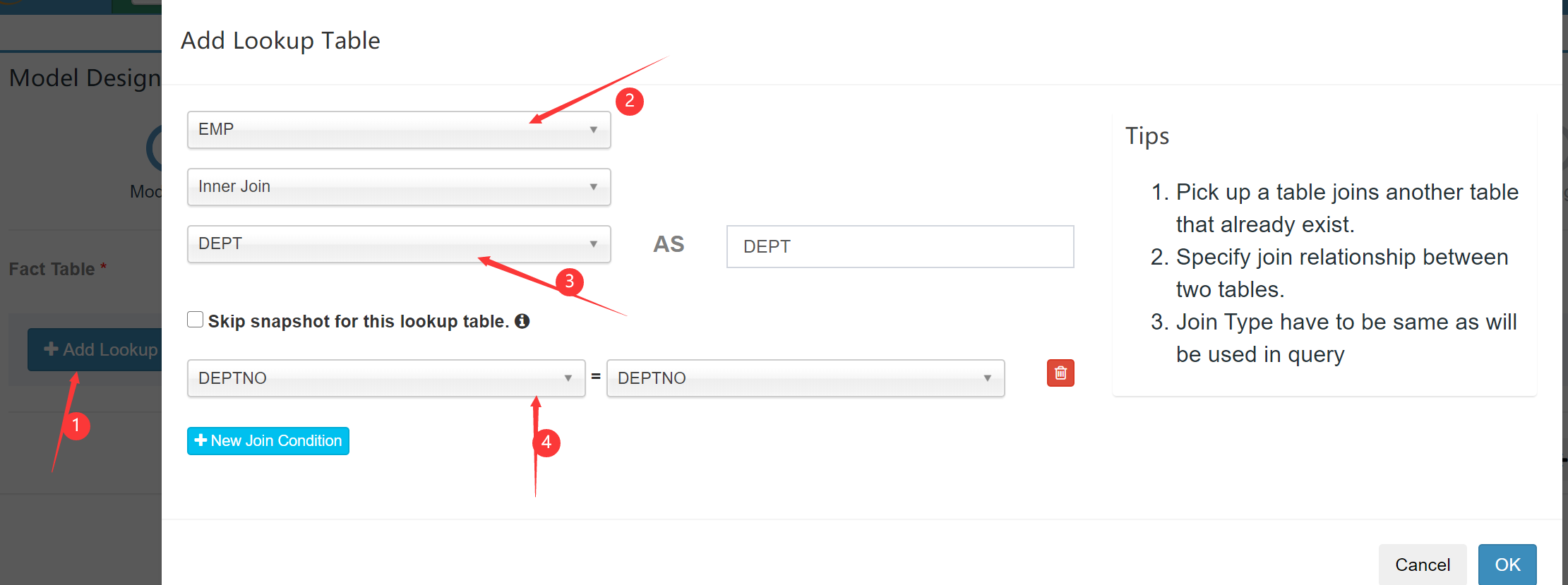
添加维度表及join字段:
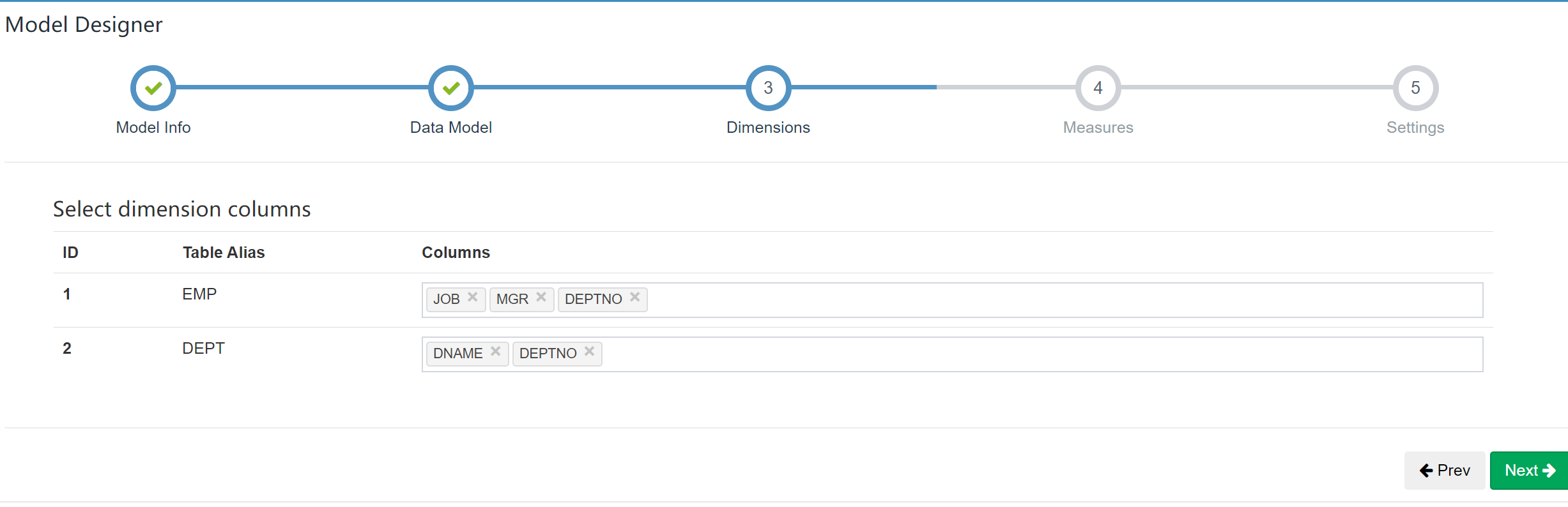
选择维度信息:
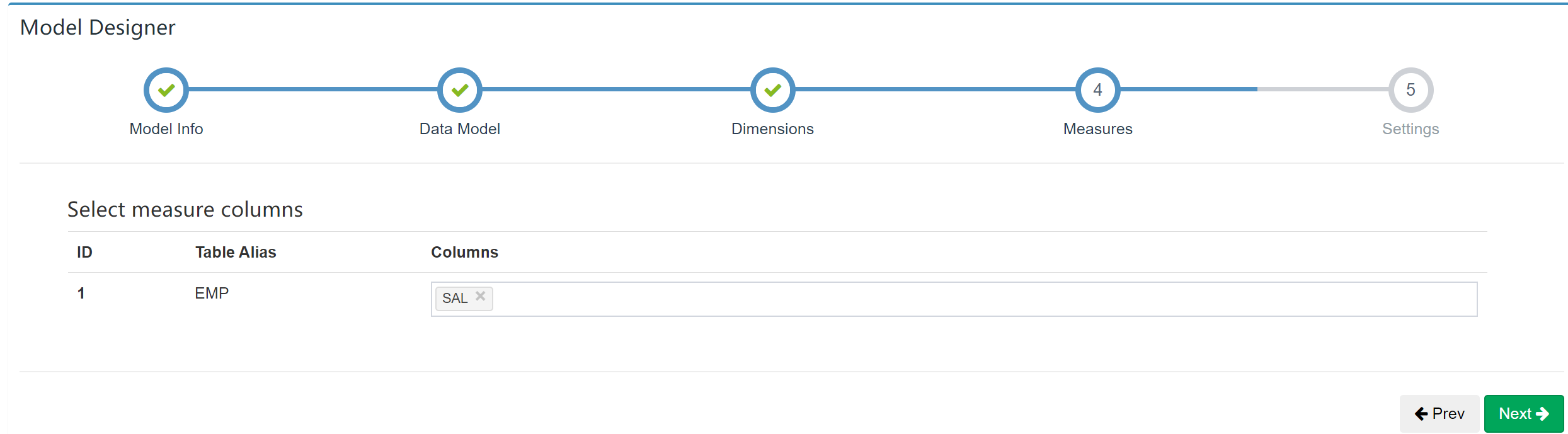
选择度量信息:
添加分区信息及过滤条件之后保存: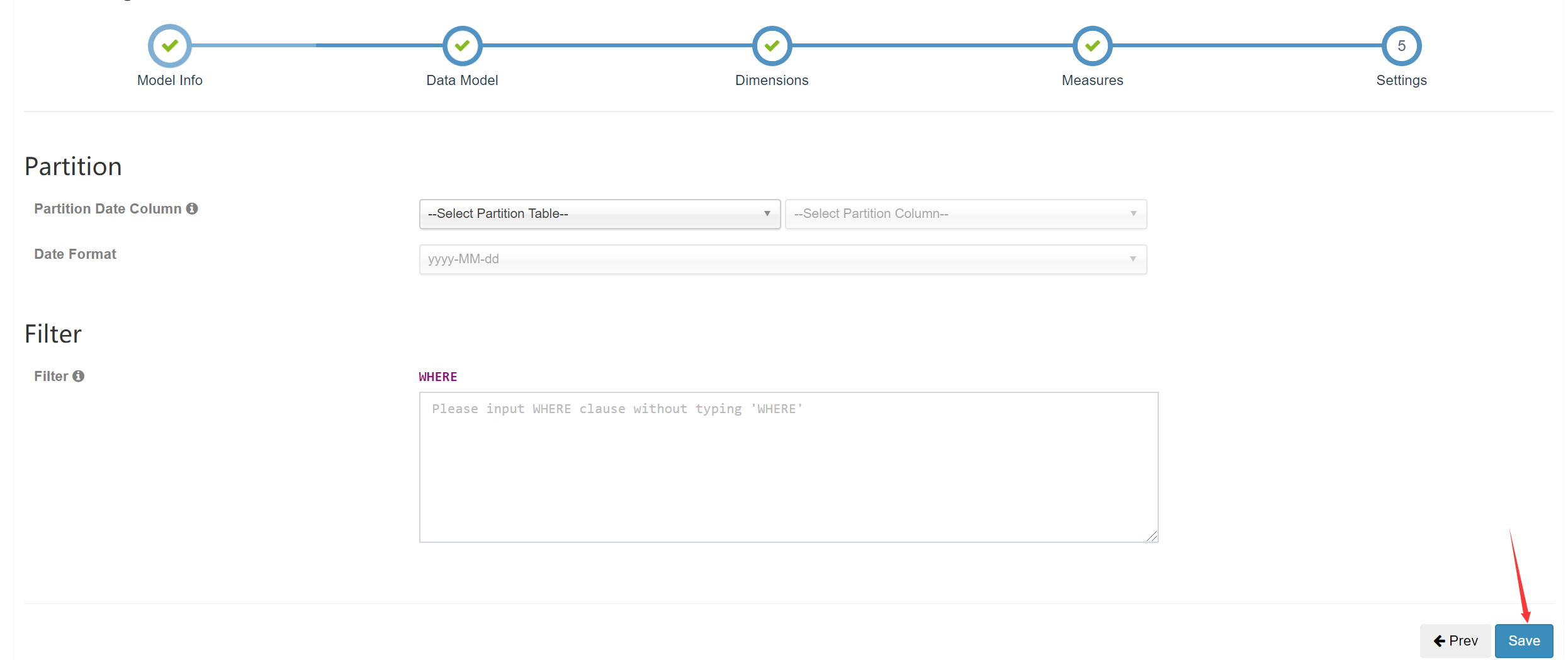
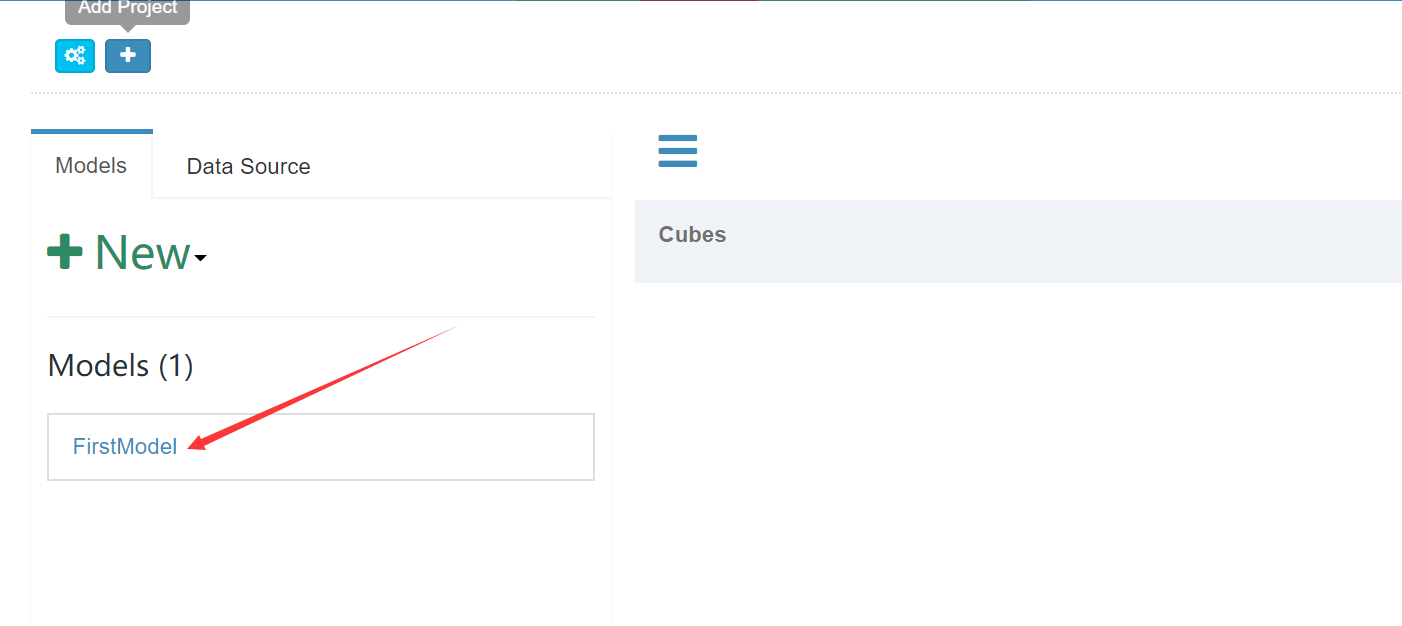
Model创建成功:
3.3创建Cube
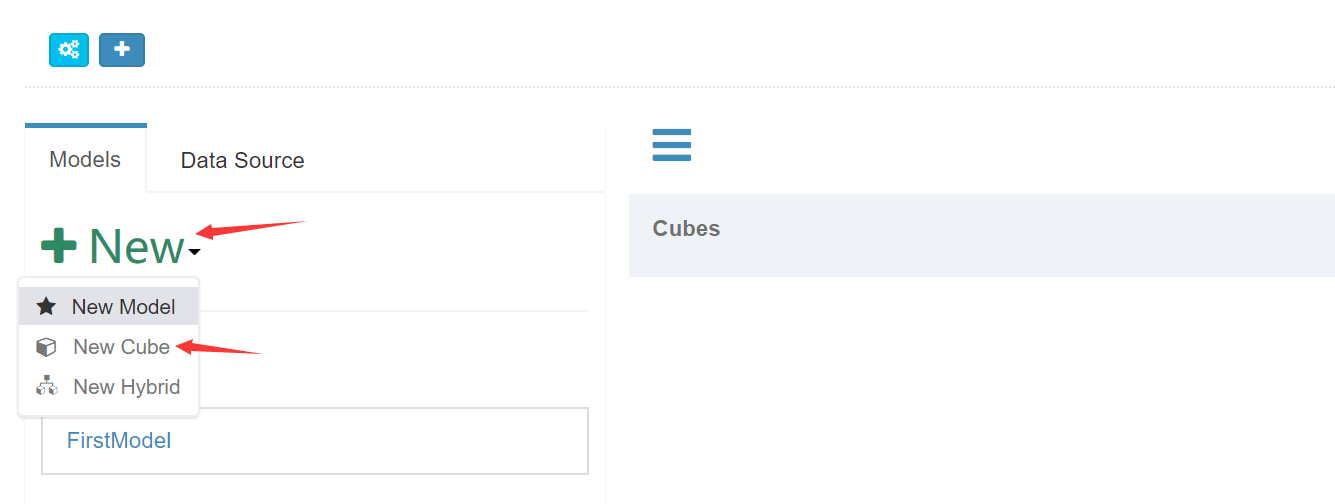
点击New按钮然后选择New Cube:
选择Model及填写Cube Name:
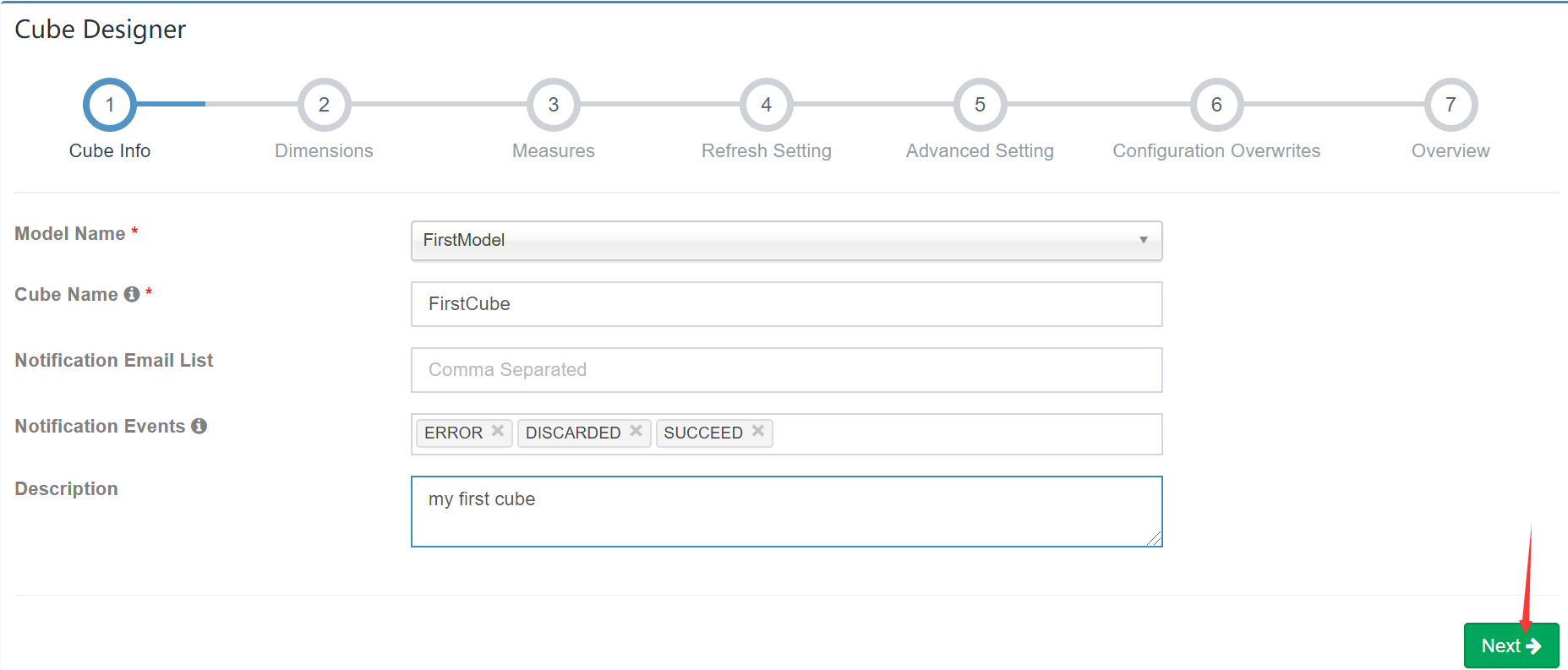
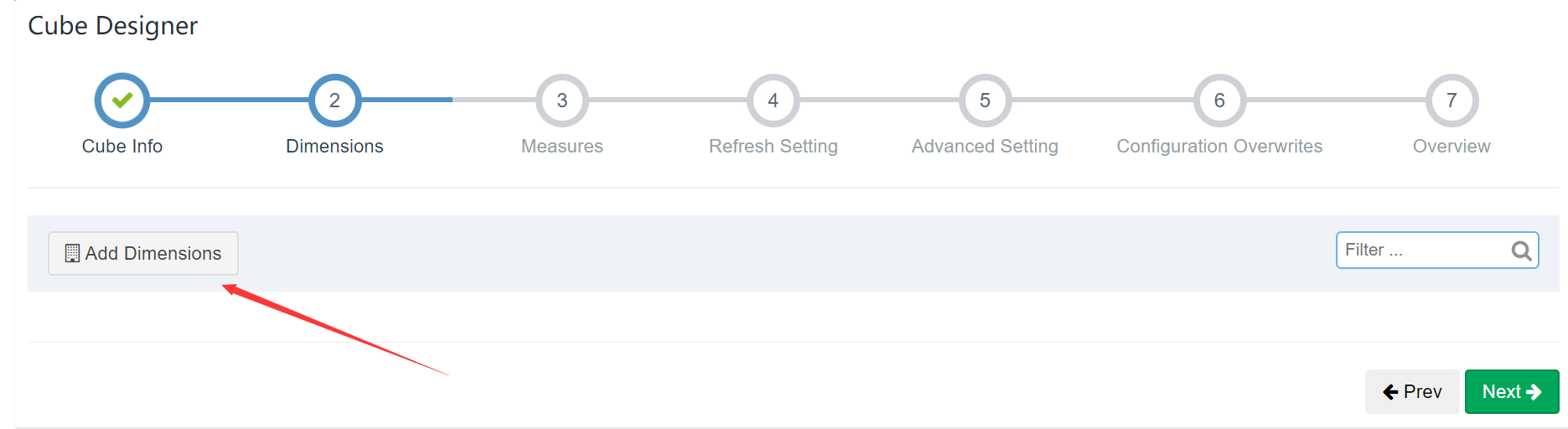
添加维度:
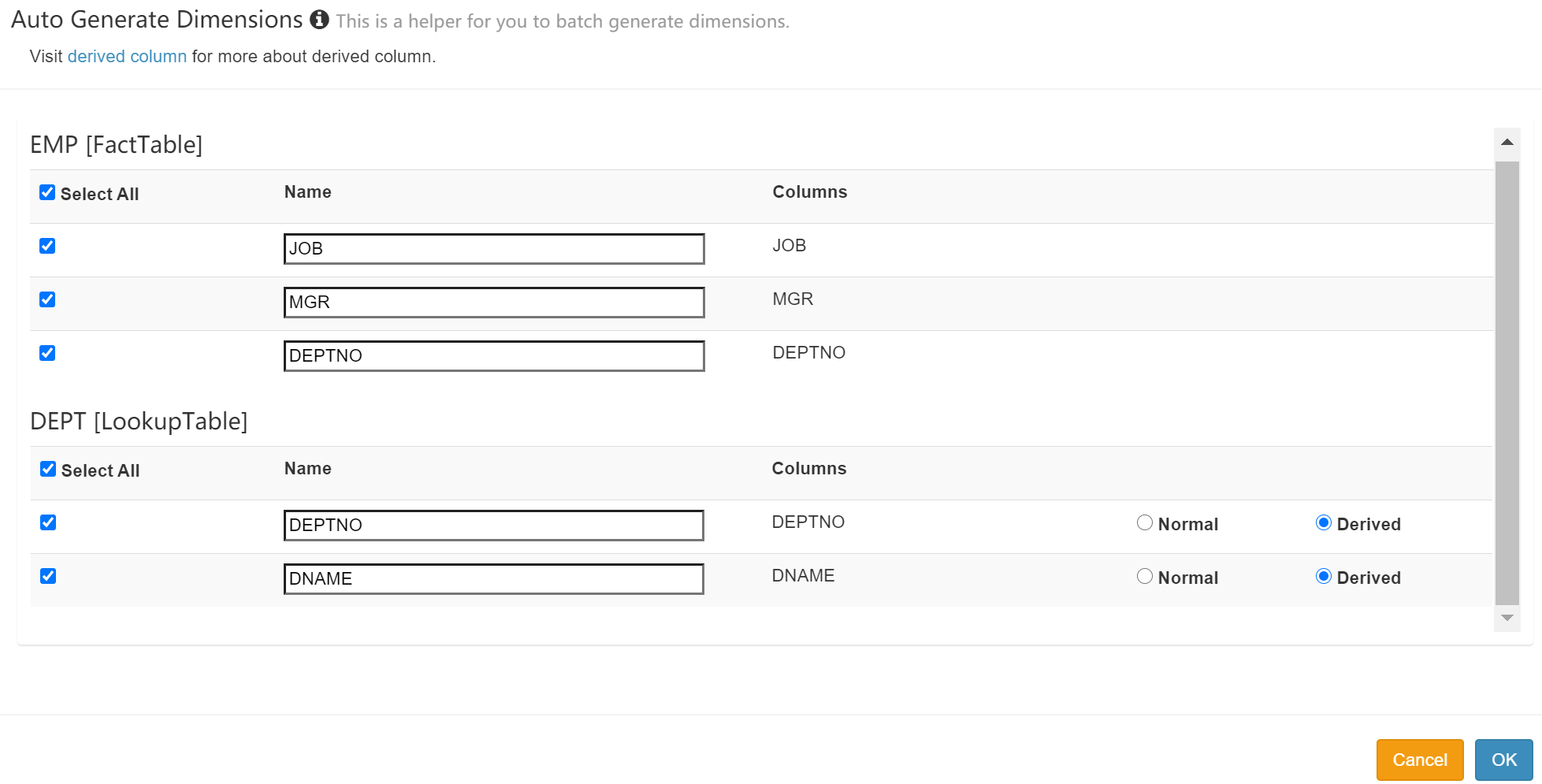
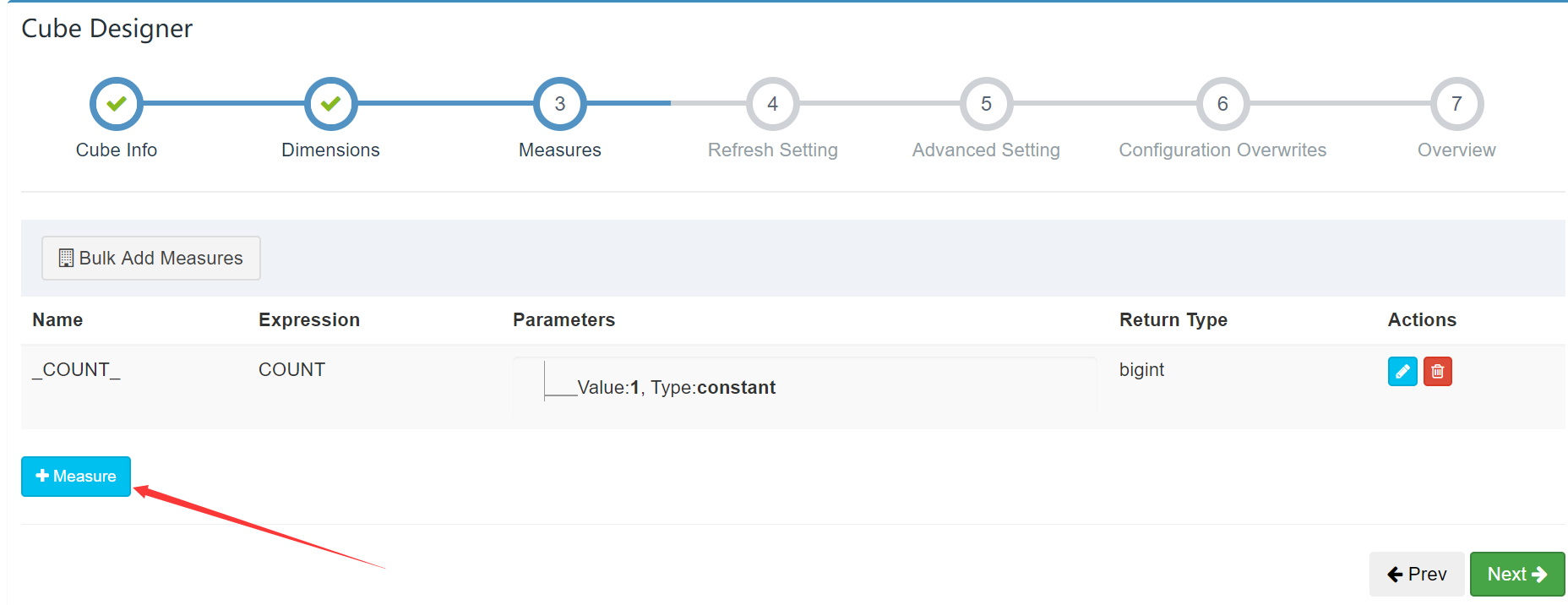
添加需要做预计算的内容:
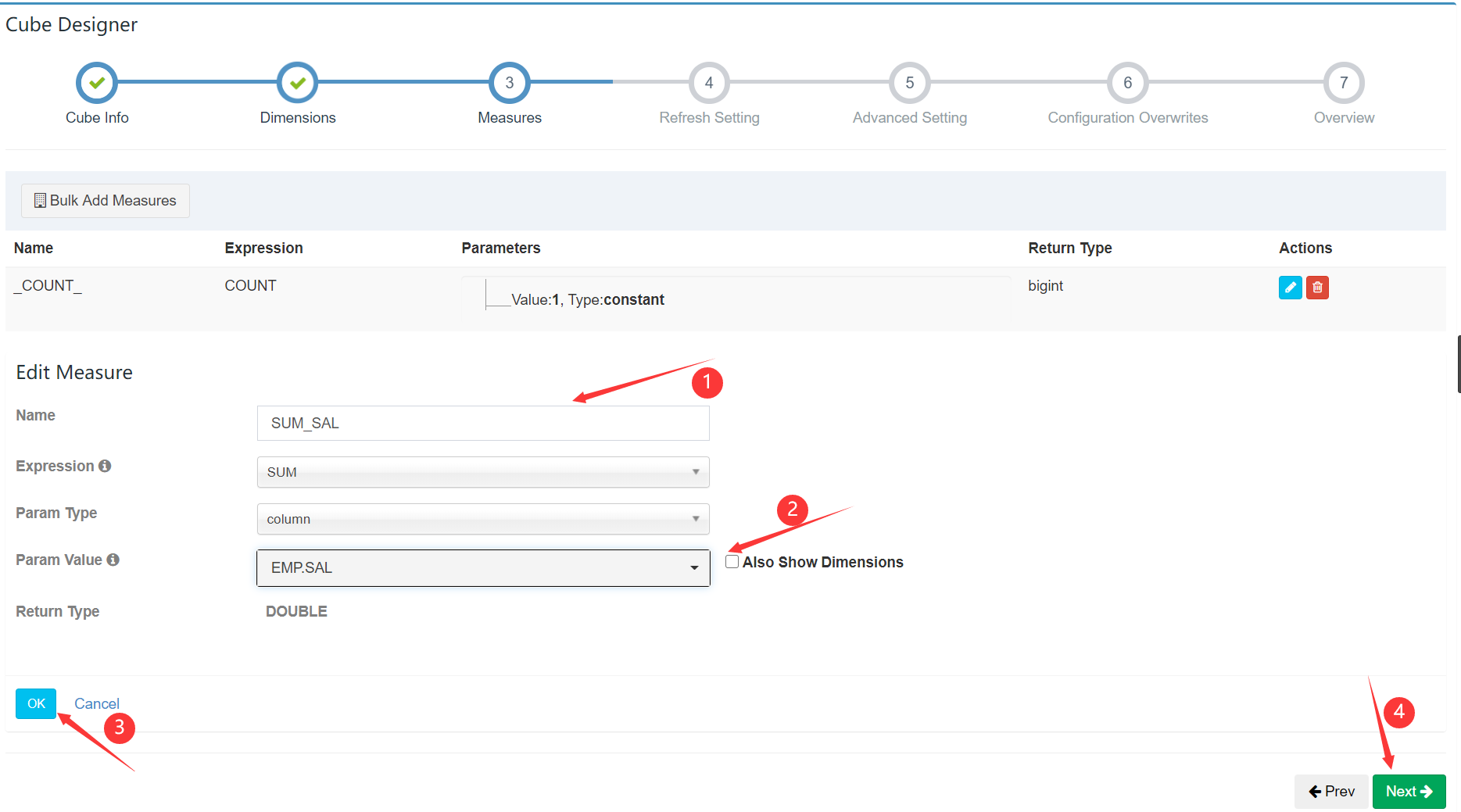
动态更新相关(默认):
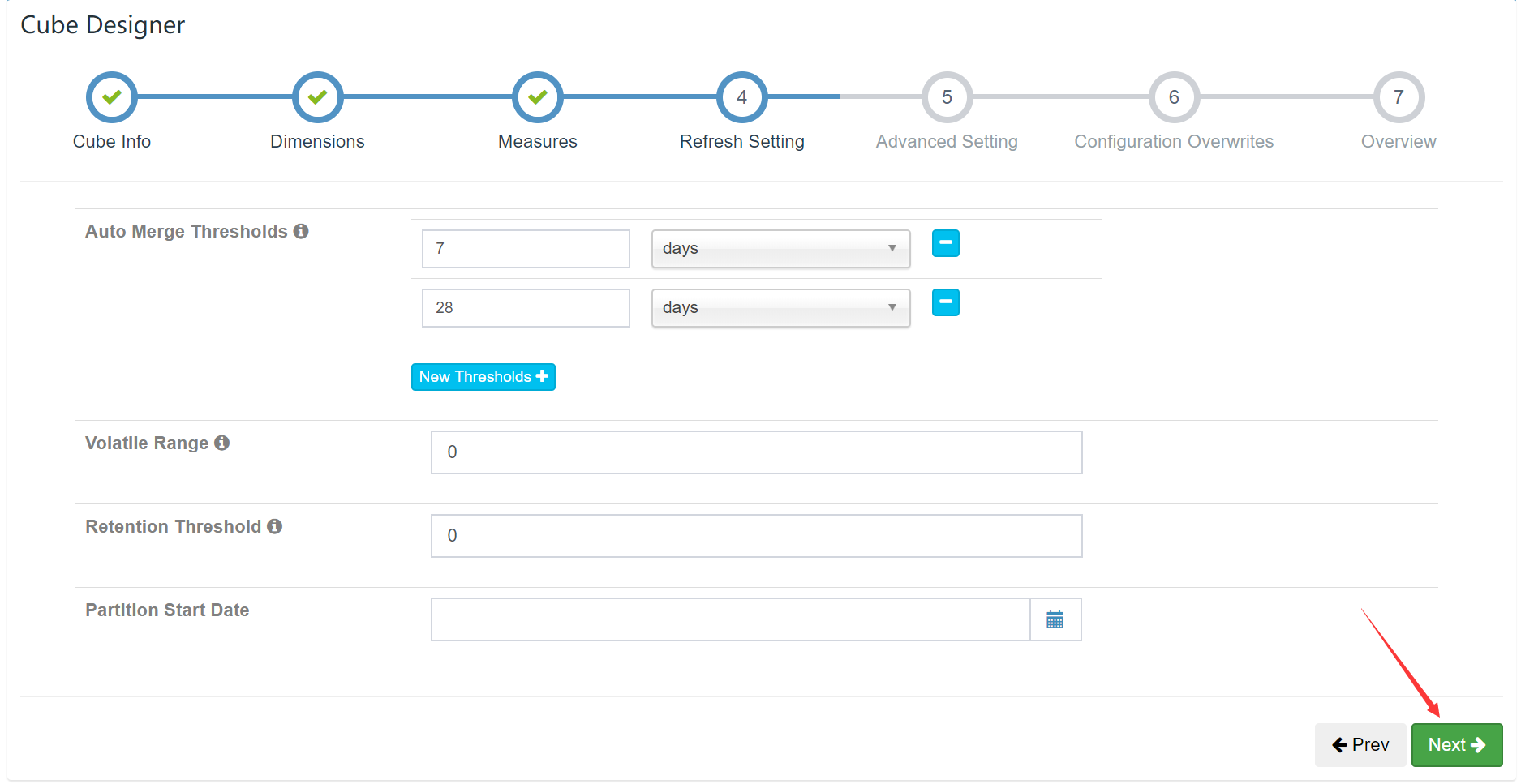
高阶模块(默认)
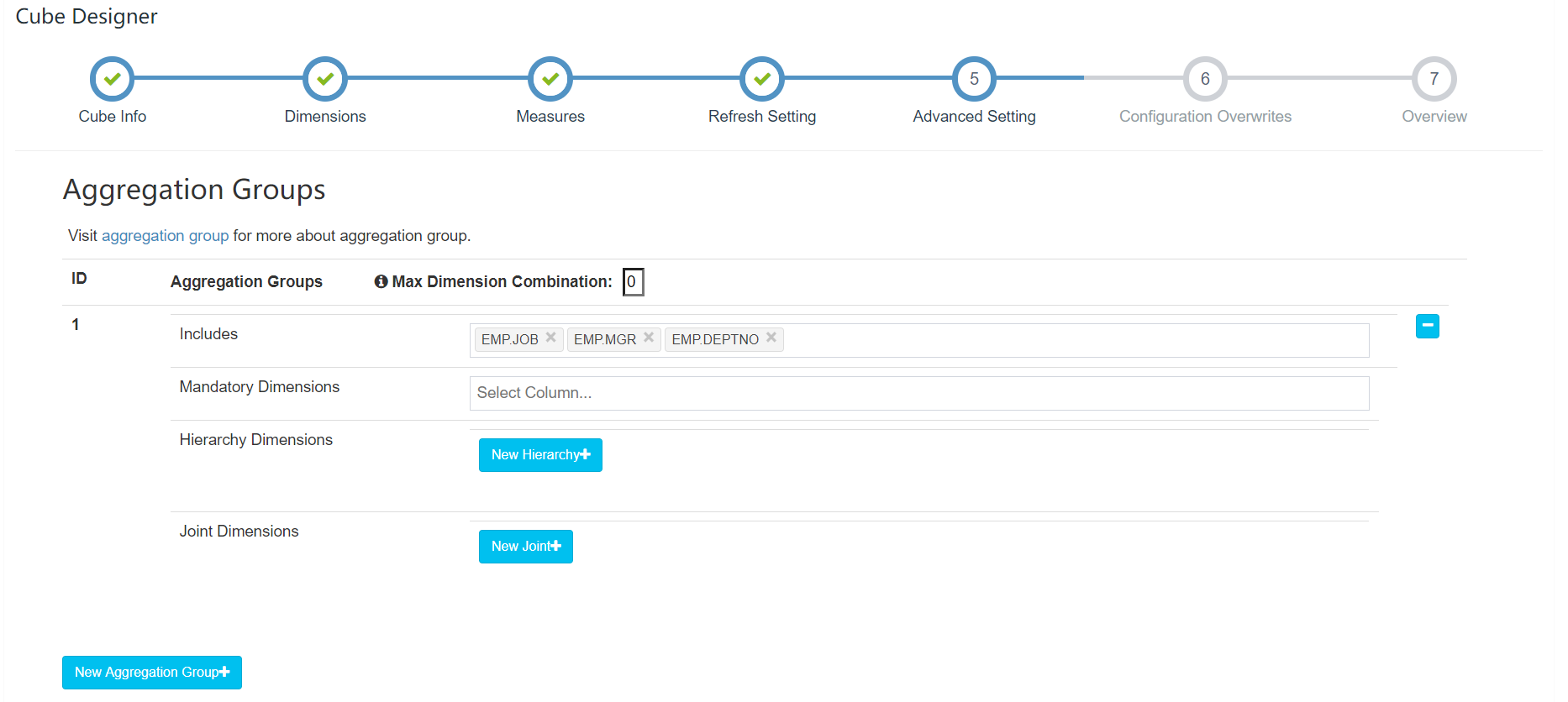
Cube配置完成:
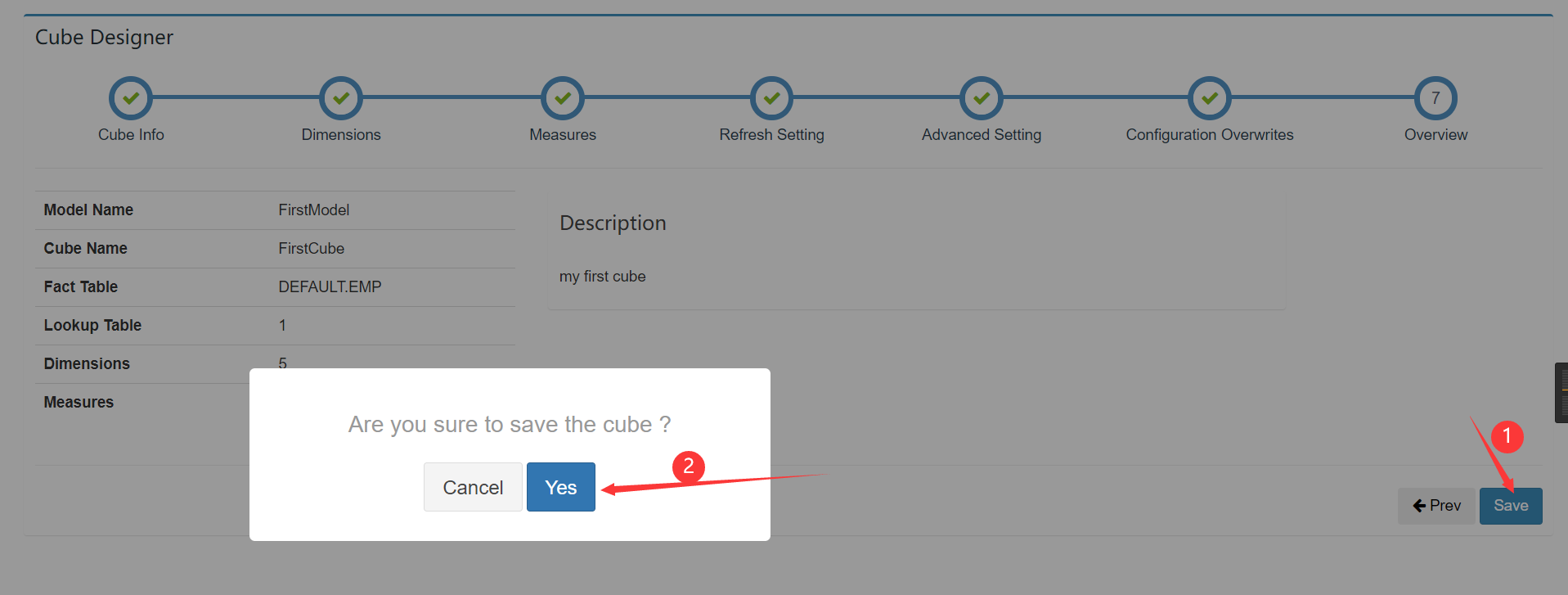
触发预计算:
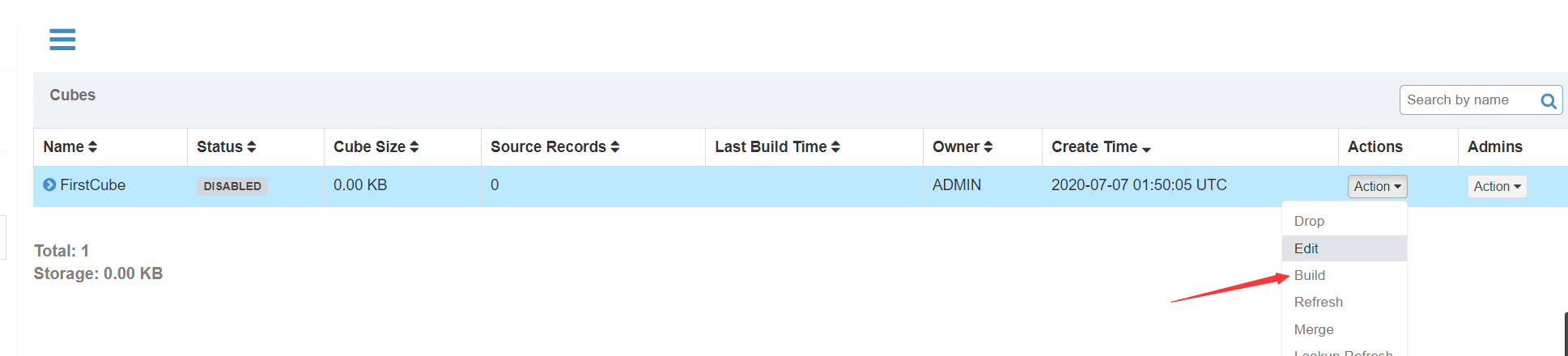
查看Build进度:
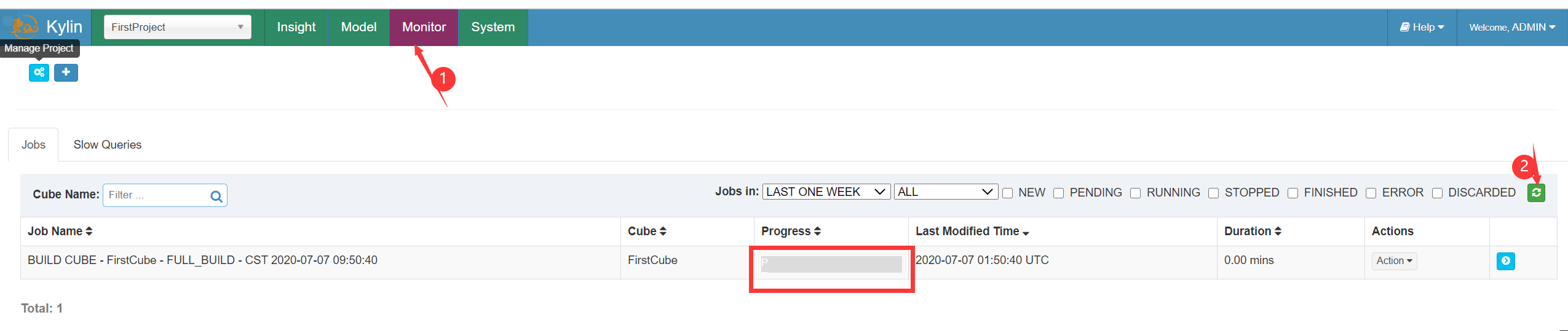
构建Cube完成

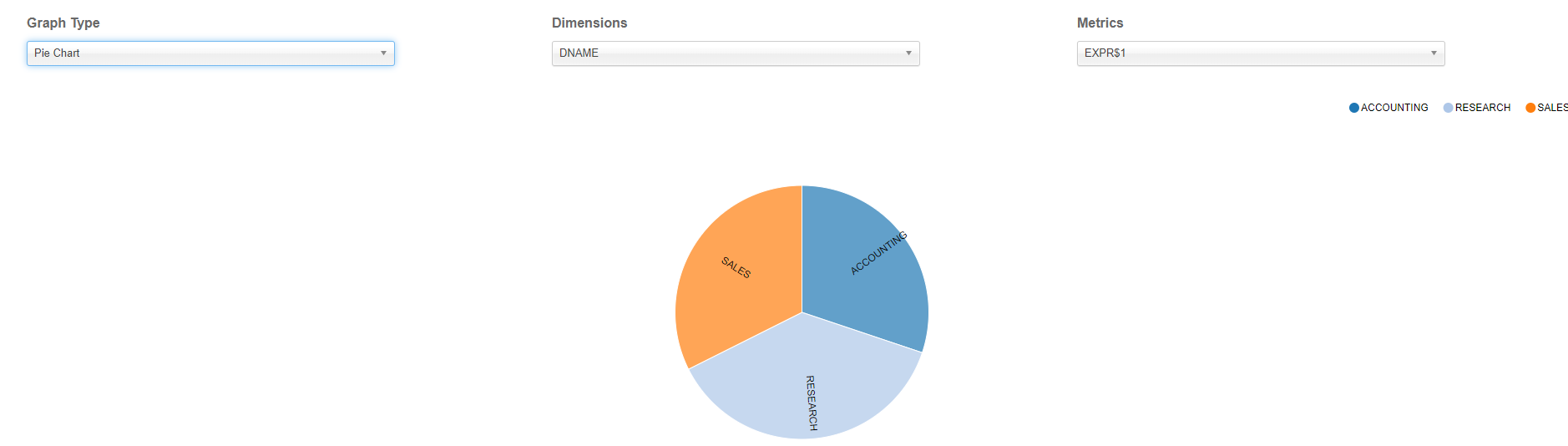
3.4 Hive和Kylin性能对比
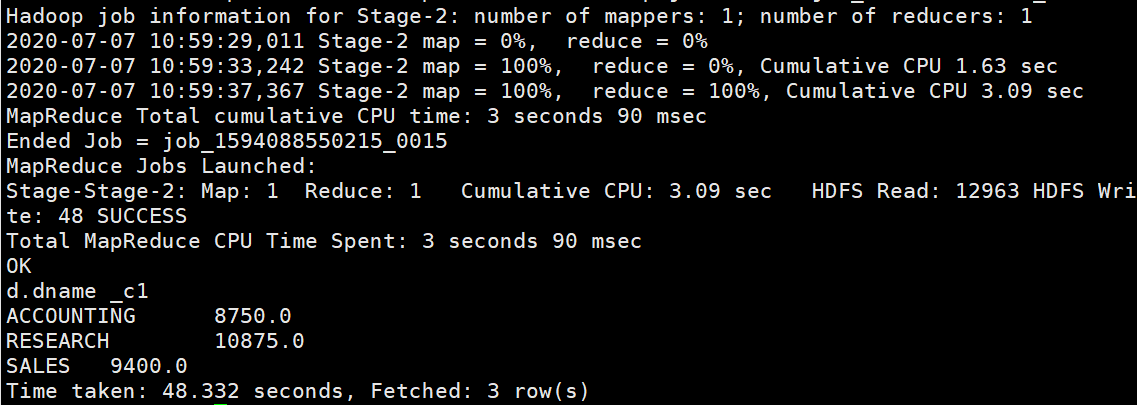
Hive查询:
hive (default)> select d.dname,sum(e.sal) from emp e join dept d \
on e.deptno = d.deptno group by d.dname;
Kylin查询:
① 进入Insight页面,在New Query中输入查询语句并Submit
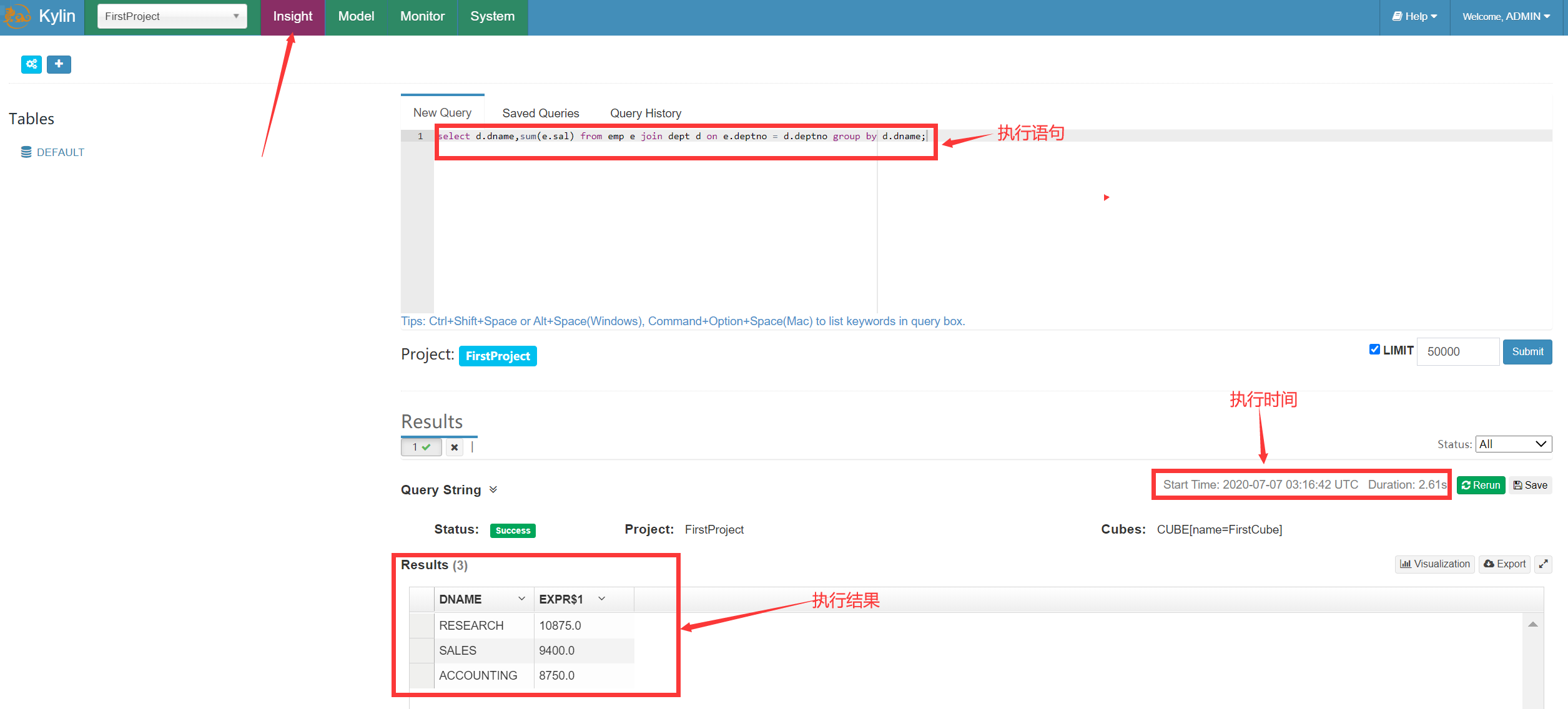
② 数据图表展示及导出
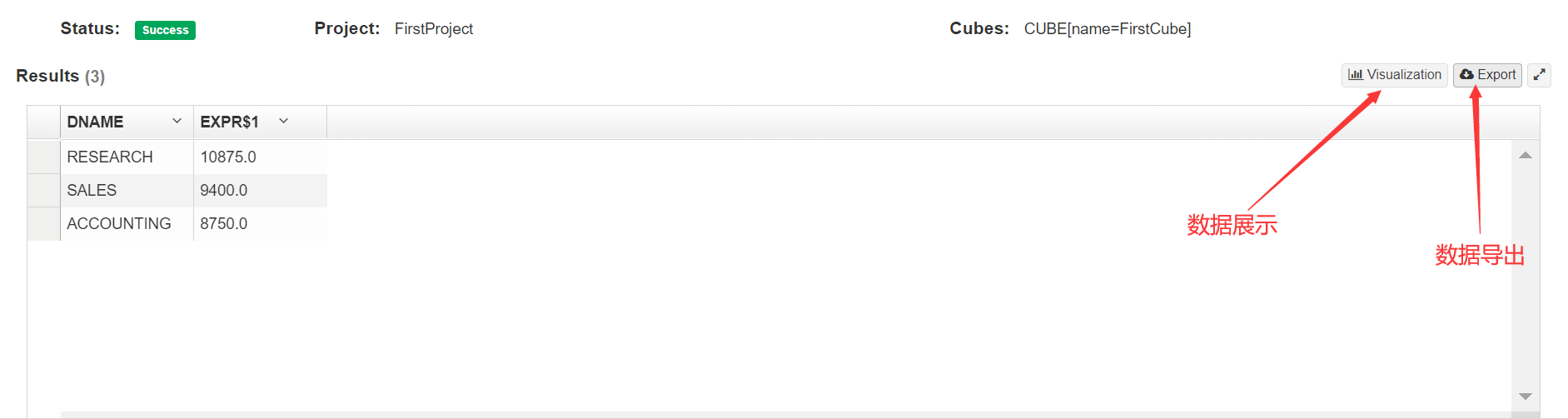
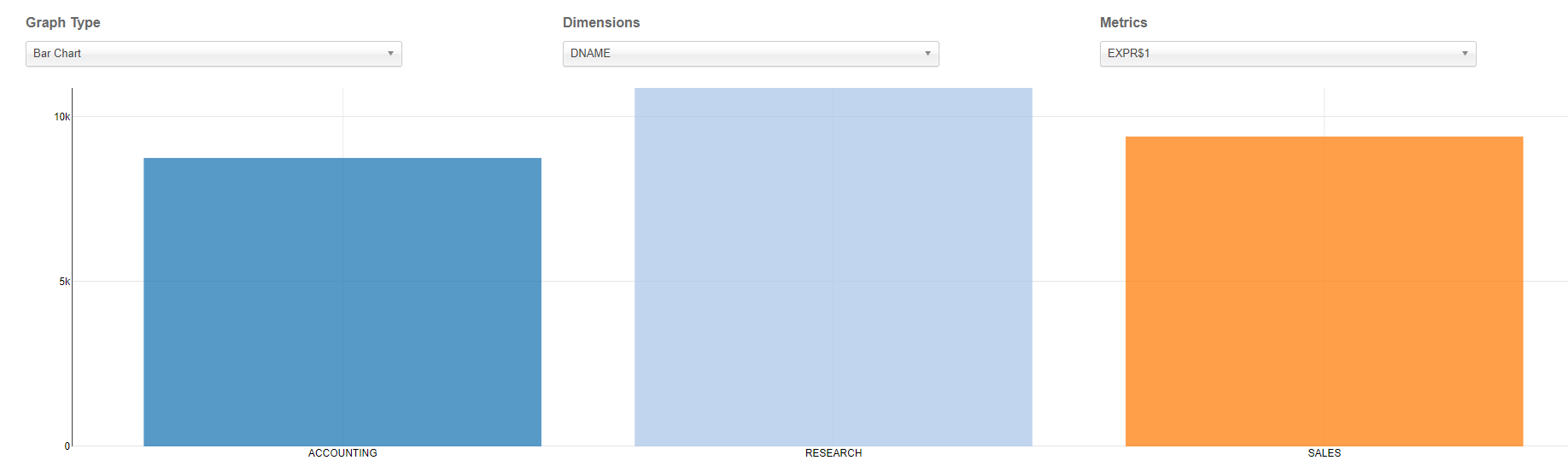
③ 数据展示之柱状图
④ 数据展示之饼状图