大家好,我是不温卜火,是一名计算机学院大数据专业大二的学生,昵称来源于成语—
不温不火,本意是希望自己性情温和。作为一名互联网行业的小白,博主写博客一方面是为了记录自己的学习过程,另一方面是总结自己所犯的错误希望能够帮助到很多和自己一样处于起步阶段的萌新。但由于水平有限,博客中难免会有一些错误出现,有纰漏之处恳请各位大佬不吝赐教!暂时只有csdn这一个平台,博客主页:https://buwenbuhuo.blog.csdn.net/
此篇为大家带来的是Cube构建原理。

一. Cube构建流程
- 1. 第一步:创建中间表
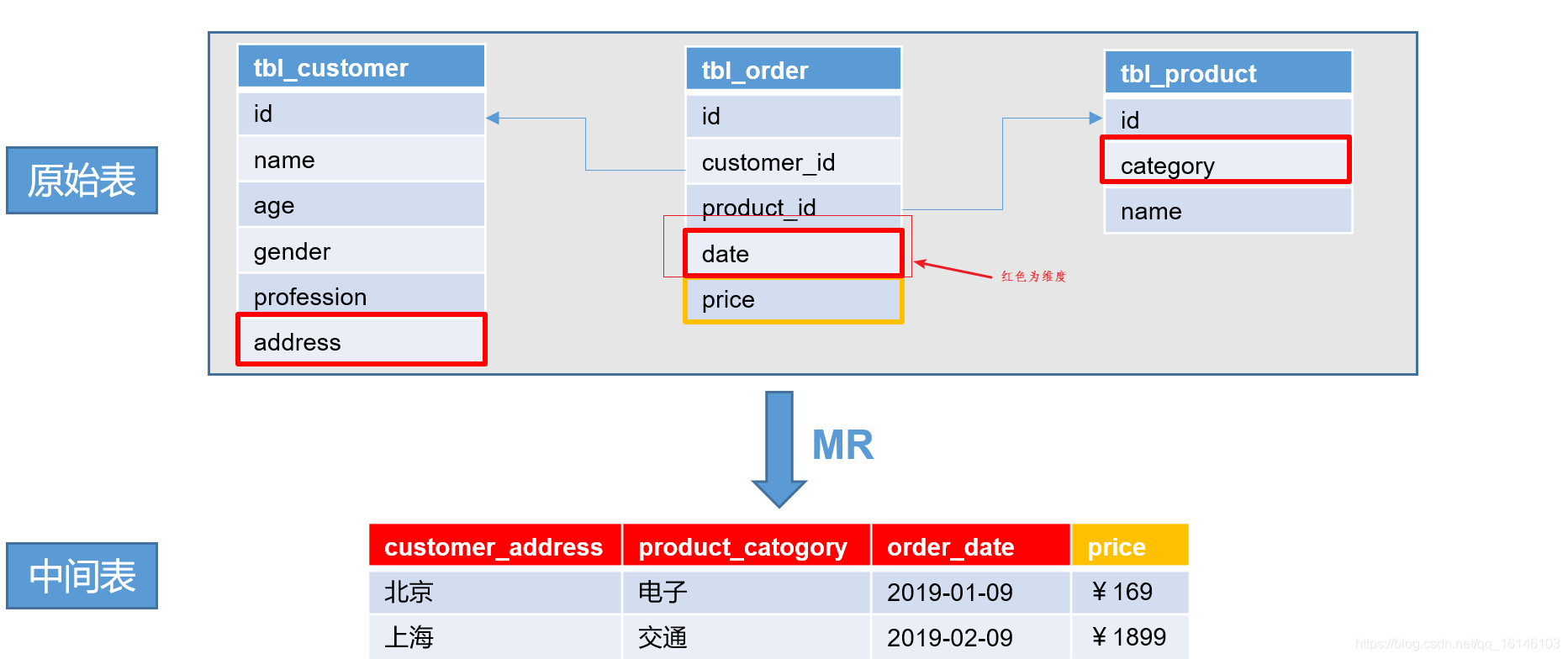
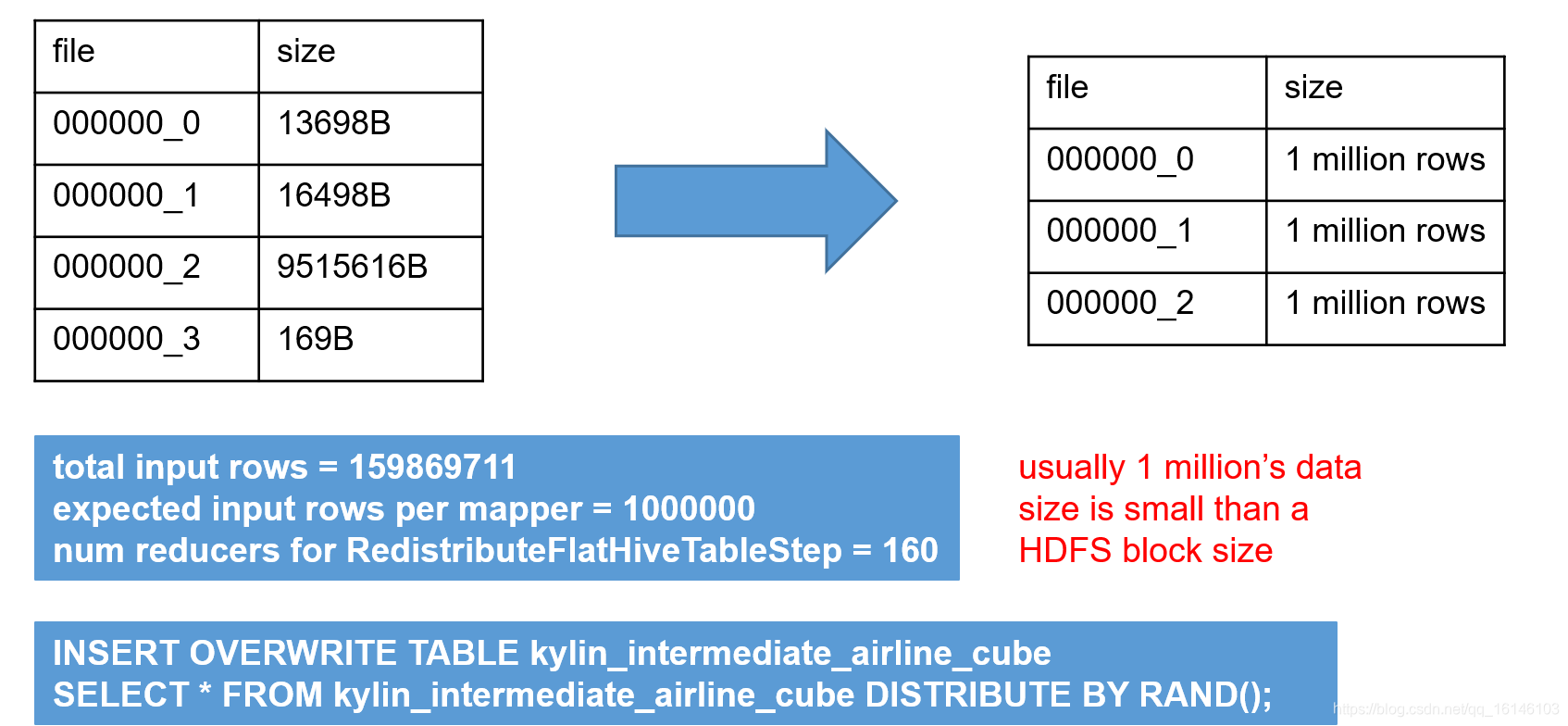
- 2.将中间表的数据均匀分配到不同的文件
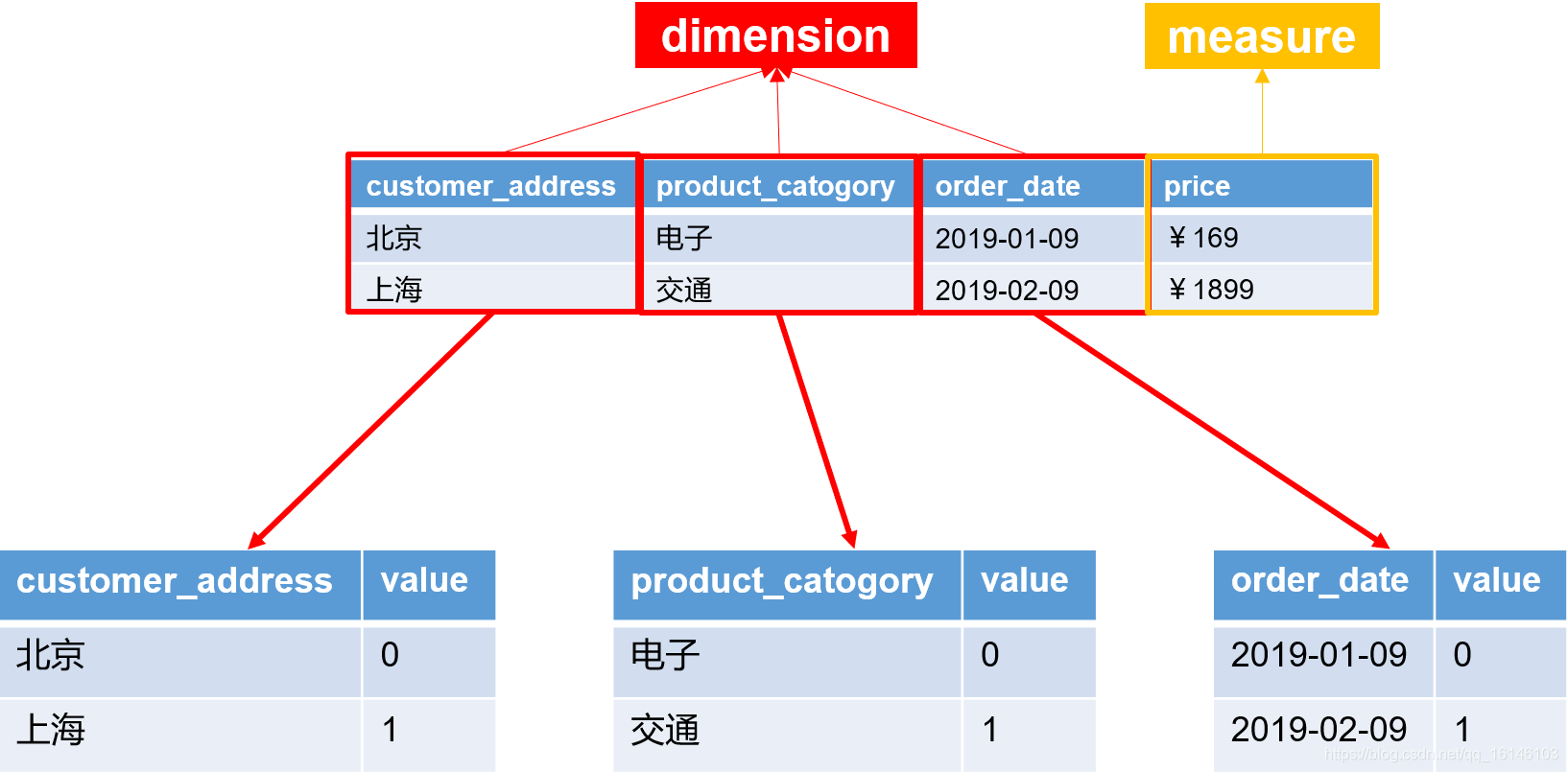
- 3.创建维度字典表
- 4. 构建cube
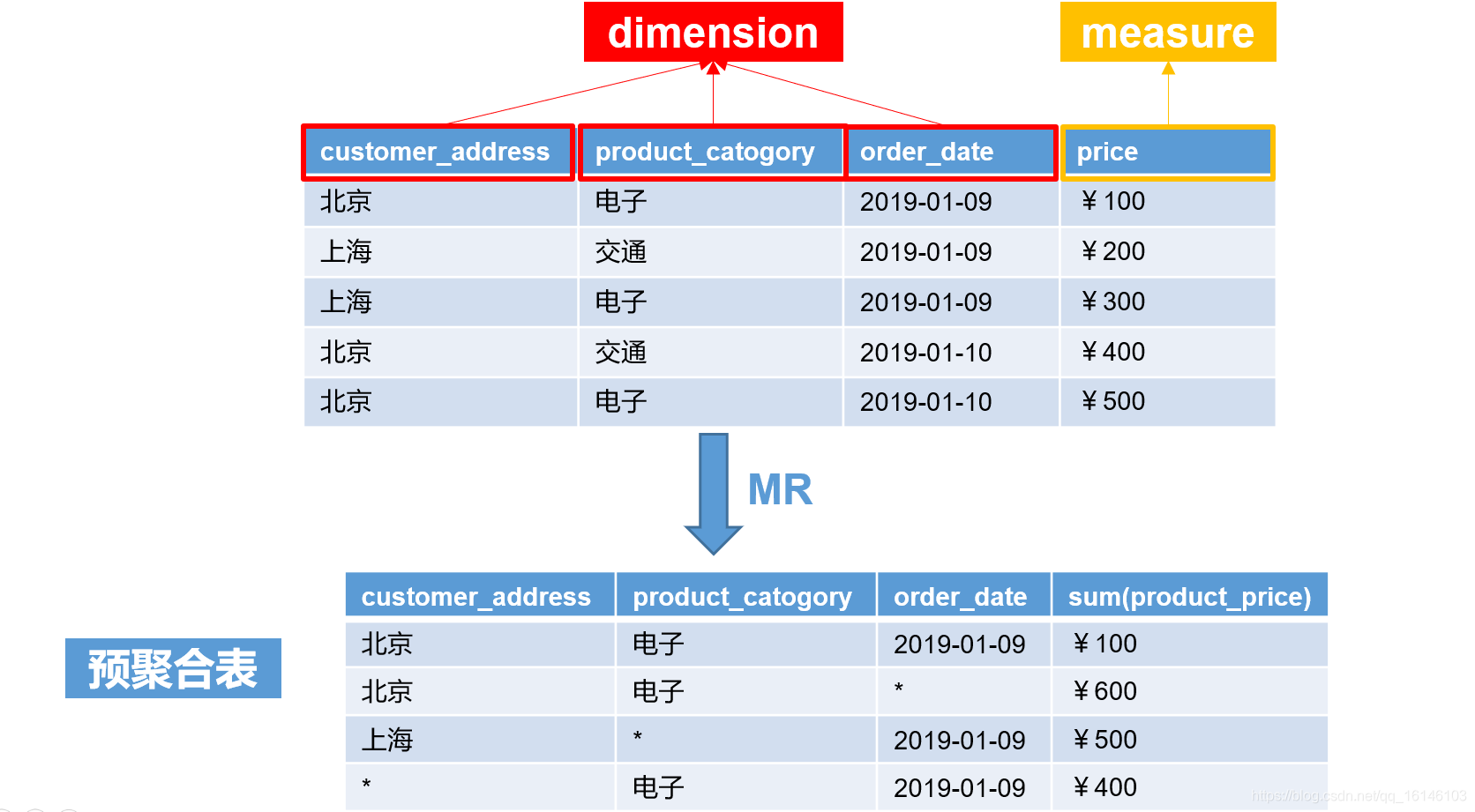
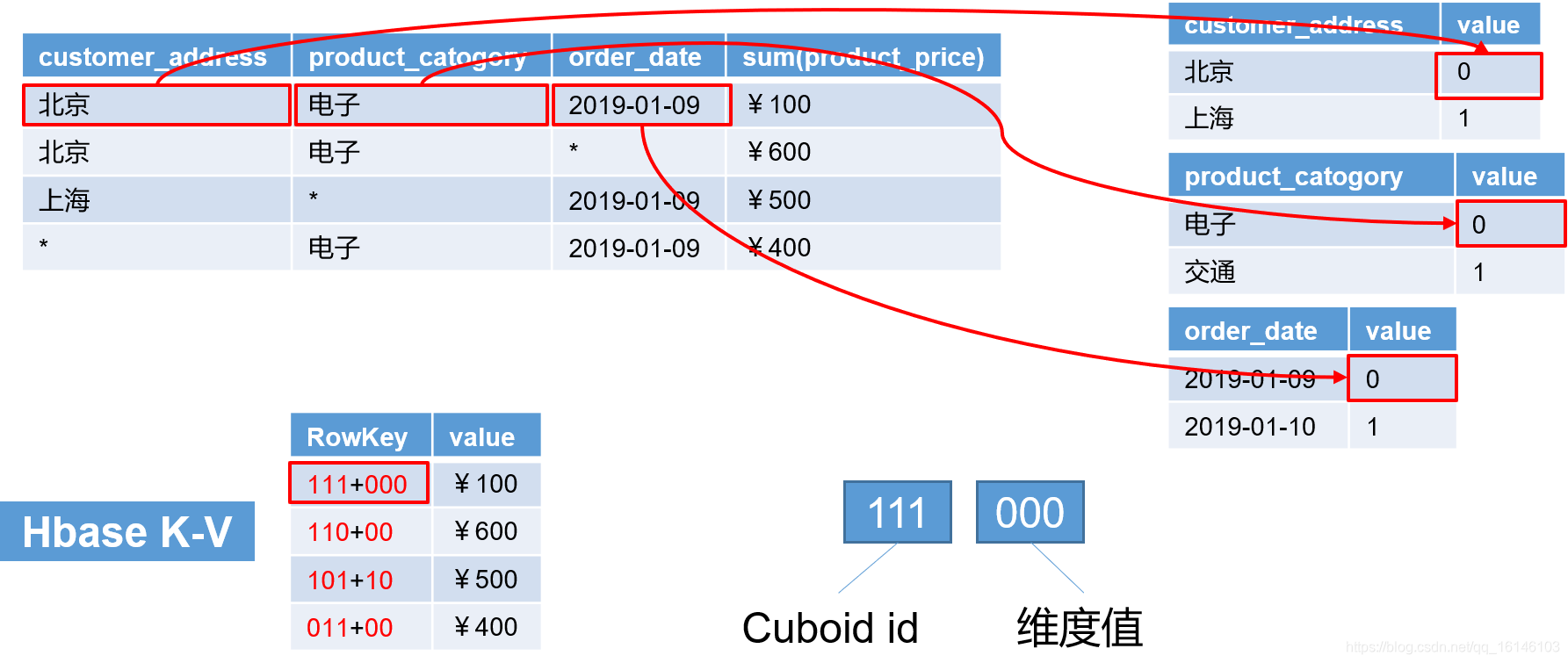
- 5.HBase K-V
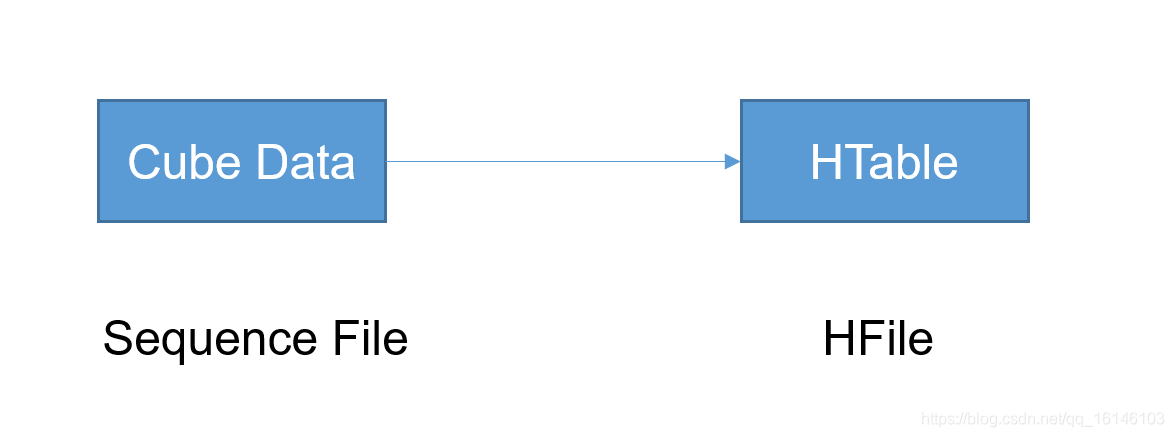
- 6.将cube data 转成GFile格式并导入HBase
二. Cube构建算法
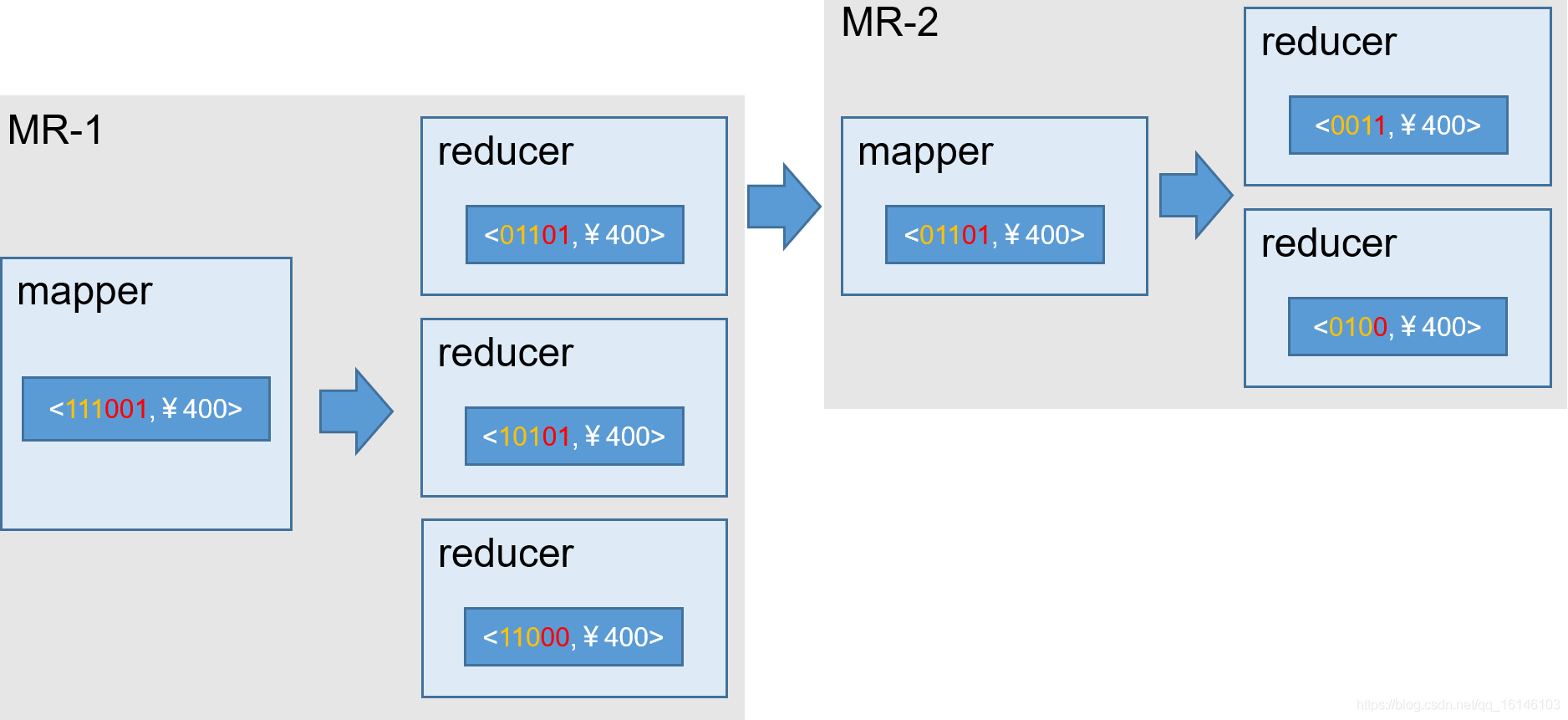
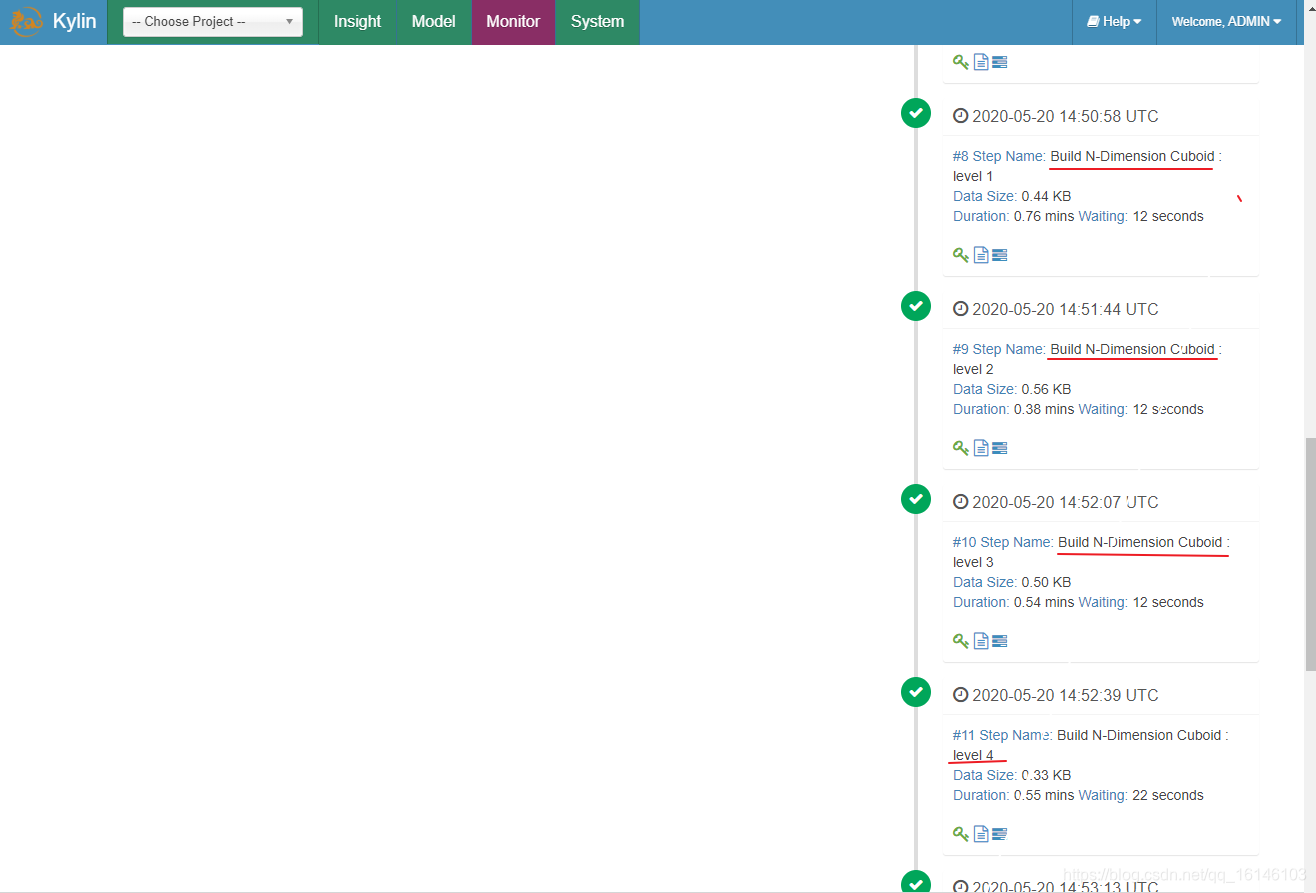
1. 逐层构建算法(layer)[默认]

我们知道,一个N维的Cube,是由1个N维子立方体、N个(N-1)维子立方体、N*(N-1)/2个(N-2)维子立方体、…、N个1维子立方体和1个0维子立方体构成,总共有2^N个子立方体组成,在逐层算法中,按维度数逐层减少来计算,每个层级的计算(除了第一层,它是从原始数据聚合而来),是基于它上一层级的结果来计算的。比如,[Group by A, B]的结果,可以基于[Group by A, B, C]的结果,通过去掉C后聚合得来的;这样可以减少重复计算;当 0维度Cuboid计算出来的时候,整个Cube的计算也就完成了。
每一轮的计算都是一个MapReduce任务,且串行执行;一个N维的Cube,至少需要N次MapReduce Job。
过程如下:
算法优点:
- 1.此算法充分利用了MapReduce的优点,处理了中间复杂的排序和shuffle工作,故而算法代码清晰简单,易于维护;
- 2.受益于Hadoop的日趋成熟,此算法非常稳定,即便是集群资源紧张时,也能保证最终能够完成。
算法缺点:
- 1.当Cube有比较多维度的时候,所需要的MapReduce任务也相应增加;由于Hadoop的任务调度需要耗费额外资源,特别是集群较庞大的时候,反复递交任务造成的额外开销会相当可观;
- 2.由于Mapper逻辑中并未进行聚合操作,所以每轮MR的shuffle工作量都很大,导致效率低下。
- 3.对HDFS的读写操作较多:由于每一层计算的输出会用做下一层计算的输入,这些Key-Value需要写到HDFS上;当所有计算都完成后,Kylin还需要额外的一轮任务将这些文件转成HBase的HFile格式,以导入到HBase中去;
总体而言,该算法的效率较低,尤其是当Cube维度数较大的时候。
2. 快速构建算法(inmem)[基于内存]

也被称作“逐段”(By Segment) 或“逐块”(By Split) 算法,从1.5.x开始引入该算法,该算法的主要思想是,每个Mapper将其所分配到的数据块,计算成一个完整的小Cube 段(包含所有Cuboid)。每个Mapper将计算完的Cube段输出给Reducer做合并,生成大Cube,也就是最终结果。如图所示解释了此流程。
过程如下:

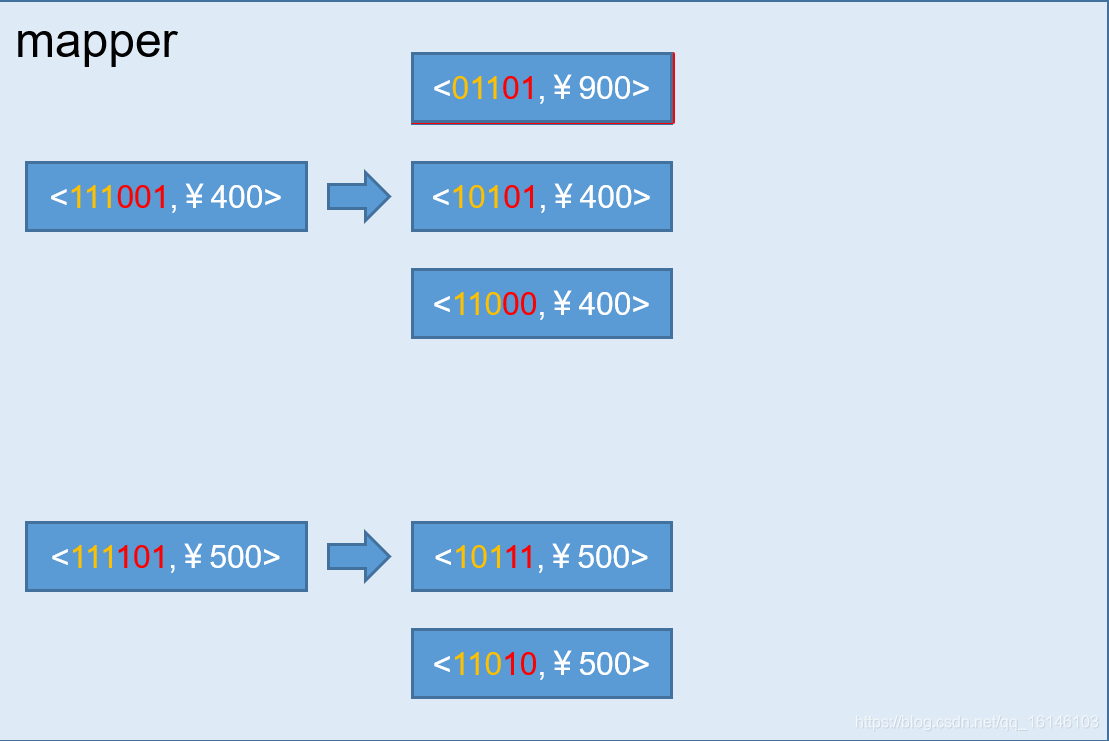
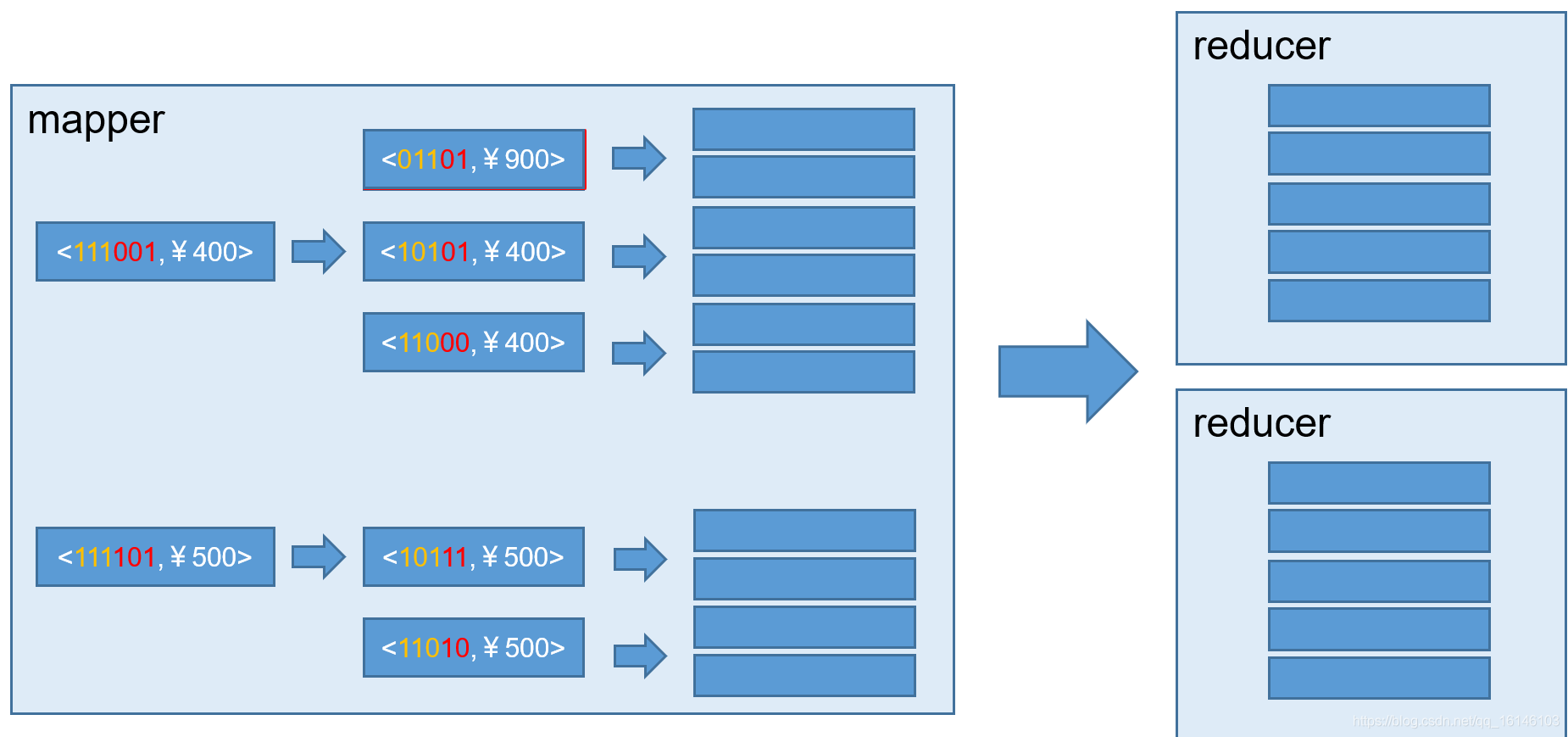
与旧算法相比,快速算法主要有两点不同:
- 1.Mapper会利用内存做预聚合,算出所有组合;Mapper输出的每个Key都是不同的,这样会减少输出到Hadoop MapReduce的数据量,Combiner也不再需要;
- 2.一轮MapReduce便会完成所有层次的计算,减少Hadoop任务的调配。
本次的分享就到这里了,

好书不厌读百回,熟读课思子自知。而我想要成为全场最靓的仔,就必须坚持通过学习来获取更多知识,用知识改变命运,用博客见证成长,用行动证明我在努力。
如果我的博客对你有帮助、如果你喜欢我的博客内容,请“点赞” “评论”“收藏”一键三连哦!听说点赞的人运气不会太差,每一天都会元气满满呦!如果实在要白嫖的话,那祝你开心每一天,欢迎常来我博客看看。
码字不易,大家的支持就是我坚持下去的动力。点赞后不要忘了关注我哦!