kafka原理
4.1.消息存储和查询机制
4.1.1.消息存储机制
#关于类别topic:
1.每条发布到kafka集群的消息都有一个类别,该类别就是topic
#关于分区partition: 1.partition是物理上的概念,每个topic包含一个或者多个partition 2.每个分区由一系列有序的不可变的消息组成,是一个有序队列 3.每个分区在物理上是一个文件夹,分区命名规则:${topicName}-${partitionId}。比如:itheima_topic-0 4.分区目录下,存储该分区的日志段。包含一个数据文件和两个索引文件 5.每条消息被追加到对应的分区中,是顺序写磁盘。这也是kafka高吞吐量的重要保证 6.kafka是局部有序,即只保证一个分区内的消息有序性,不保证全局有序
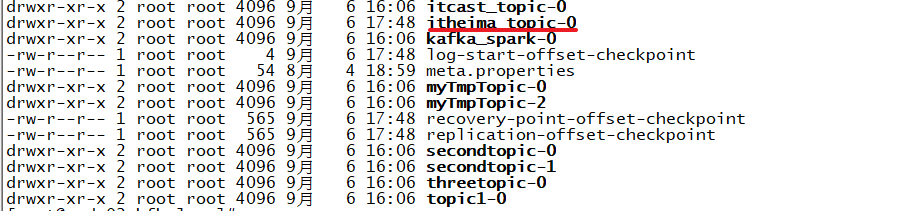
#关于日志段logSegment: 1.日志文件按照大小、或者时间滚动,切分成一个或者多个日志段(logSegment) 日志段大小默认1GB,配置参数:log.segment.bytes 时间长度配置参数:log.roll.ms、或者log.roll.hours 2.kafka的日志段: 由一个日志文件: 00000000000000000000.log 两个索引文件: 00000000000000000000.index 00000000000000000000.timeindex 3.数据文件: 数据文件以.log为后缀,保存实际消息数据 命名规则:数据文件的第一条消息偏移量(基准偏移量:BaseOffset),左补0构成20位数字字符组成 基准偏移量是上一个数据文件的LEO+1。LEO(Log End Offset) 4.偏移量索引文件: 文件名称与数据文件名称相同,以.index作为后缀。用于快速根据偏移量定位到消息所在的位置 5.时间戳索引文件: 文件名称与数据文件名称相同,以.timeindex作为后缀。用于根据时间戳快速定位到消息所在的位置
关于日志段文件:

关于偏移量:
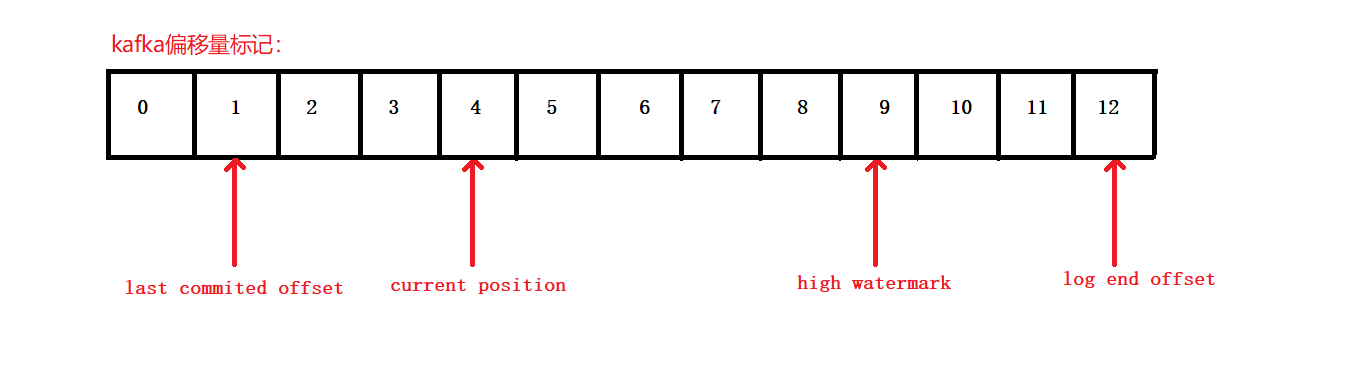
#读取offset=368776的消息,需要通过两个步骤完成:
查找segment file
通过segment file 查找message

#文件偏移量: 1. 最开始的文件:00000000000000000000.index,起始偏移量(offset)为 0 2.00000000000000368769.index,消息起始偏移量:368770 = 368769 + 1 3.00000000000000737337.index,消息起始偏移量:737338=737337 + 1 4.后续文件以此类推 #查找过程: 1.根据起始偏移量,文件有序。 2.通过二分查找,快速定位到当前offset对应的文件。比如: 当 offset=368776 ,定位到 00000000000000368769.index 和对应 log 文件
#偏移量在.index文件存储: kafka并不是每条消息都对应有索引(在.index进行存储)。而是采取了稀疏存储的方式,每个一定字节的数据建立一条索引。索引跨度通过参数配置:index.interval.bytes #查找过程: 1.根据当前目标偏移量,通过二分查找,查找值小于等于目标偏移量的最大偏移量 2.从查找到的最大偏移量开始,顺序扫描数据文件,直到在数据文件中找到偏移量,与目标偏移量相等的消息
4.2.生产者数据分发策略与发送数据方式
#关于生产者数据分发策略: 1.在kafka中一个topic下,有一个或者多个partition。那么当Producer向kafka写入数据的时候,如何决定数据该写入哪一个partition中呢? 2.分三种情况: 2.1.Producer将数据发送到指定分区: /** *创建消息对象 0 1 2 *参数说明: * topic:指定类别 * partition:指定分区 * key:数据的key * value:数据值value */ public ProducerRecord(String topic, Integer partition, K key, V value) { this(topic, partition, (Long)null, key, value, (Iterable)null); } 2.2.如果没有明确指定分区: 2.2.1.数据不是k/v对数据,采取轮询的策略。比如有三个分区:0,1,2。则将数据对应按照0,1,2,0,1,2......轮询方式写入分区 2.2.2.数据是k/v对数据,采取计算k的哈希值,将k哈希值%可用分区数=当前分区。决定将数据写入到对应的分区
源码参考:
// 默认分区类: public class DefaultPartitioner implements Partitioner { // 获取目标分区 public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) { // 获取当前topic所有的分区 List<PartitionInfo> partitions = cluster.partitionsForTopic(topic); // 获取到总的分区数量 int numPartitions = partitions.size(); // 判断当前消息是否有key,如果没有key的话,采取的是轮训策略 if (keyBytes == null) { int nextValue = this.nextValue(topic); List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic); if (availablePartitions.size() > 0) { int part = Utils.toPositive(nextValue) % availablePartitions.size(); return ((PartitionInfo)availablePartitions.get(part)).partition(); } else { return Utils.toPositive(nextValue) % numPartitions; } } else { // 如果当前的消息是有key的,把当前的key求hash值,再跟总的分区数量求余,决定把数据写入哪一个分区 return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions; } } // 轮询策略,获取下一个分区 private int nextValue(String topic) { AtomicInteger counter = (AtomicInteger)this.topicCounterMap.get(topic); if (null == counter) { counter = new AtomicInteger(ThreadLocalRandom.current().nextInt()); AtomicInteger currentCounter = (AtomicInteger)this.topicCounterMap.putIfAbsent(topic, counter); if (currentCounter != null) { counter = currentCounter; } } return counter.getAndIncrement(); } }
#关于数据发送方式:
1.同步阻塞发送:
适用场景:
业务不需要高吞吐量、更关心消息发送的顺序、不允许消息发送失败
参考代码:
图一
2.异步发送(发送并忘记):
适用场景:
业务只关心吞吐量、不关心消息发送的顺序、可以允许消息发送失败
参考代码:
图二
3.异步发送(回调函数):
适用场景:
业务需要知道消息发送成功、不关心消息发送的顺序
参考代码:
图三
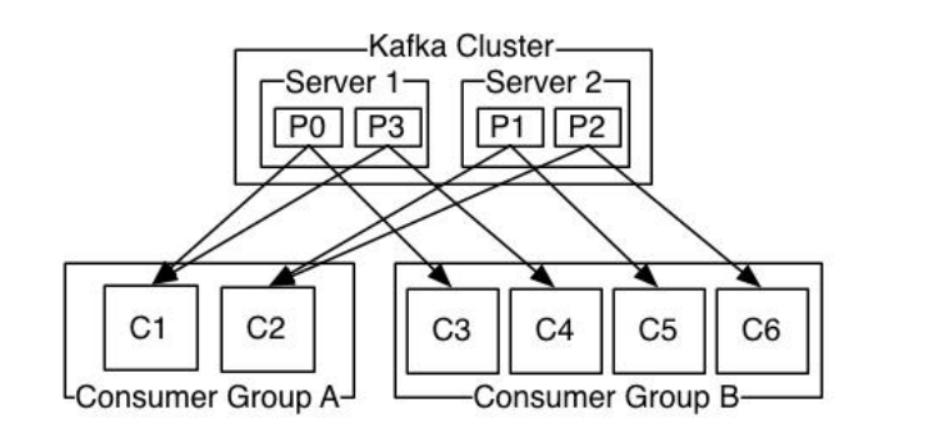
#关于消费者平衡过程: 1.消费者平衡(Consumer rebalance)指消费者重新加入消费组,并重新分配分区给消费者的过程 2.会引起消费者平衡的情况: 2.1.新的消费者加入消费组 2.2.某个消费者从消费组退出(不管是异常退出,还是正常关闭) 2.3.增加订阅主题的分区(kafka的分区数,可以动态增加,但不能减少) 2.4.某台broker宕机,新的协调器当选 2.5.某个消费者在心跳会话时间内没有发送心跳请求(配置参数:session.timeout.ms),组协调器认为消费者已经退出 #关于消费者与partition对应关系: 1.如果有三个partition:p0/p1/p2,同一个消费组有三个消费者:c0/c1/c2。则为一一对应关系 2.如果有三个partition:p0/p1/p2,同一个消费组有两个消费者:c0/c1。则其中一个消费者消费两个分区的数据;另外一个消费者消费一个分区的数据 3.如果有两个partition:p0/p1,同一个消费组有三个消费者:c0/c1/c2。则有一个消费者为空闲,另外两个消费者分别各自消费一个分区的数据 --总的来说,同一个分区的数据,只能被一个消费组中的一个消费者消费