Kafka介绍
简而言之,kafka是一种mq,现在有很多开源的mq,包括ActiveMq,RokectMq,
Rabbitmq和Kafka等等。还有些大型互联网公司内部不开源的MQ,比如阿里巴巴的MetaQ,京东的JMQ等等。
kafka是强依赖于zookeeper的,所以,如果想深入了解kafka,需要熟悉zookeeper。下面是kafka的架构图,网上找的,整体结构画的很清晰了。
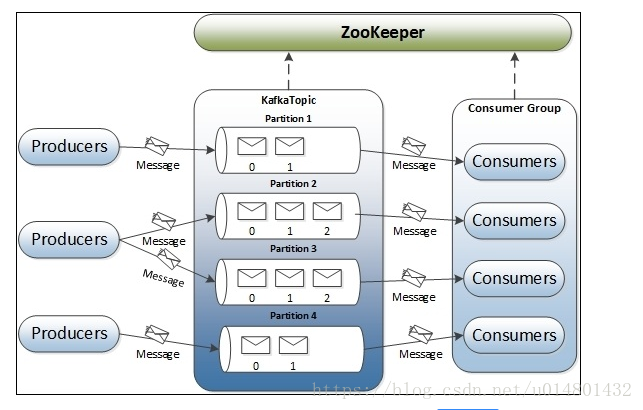
场景:网络爬虫爬取了很多网站,将爬取下来的信息,发到kafka,然后,业务系统会消费这些信息,然后处理,写入DB。
很简单的场景,但是要细细的分析起来,会发现,10篇博文都写不完。从上图中可以看到,左侧是生产者系统的集群,对应上面的场景就是爬虫系统。右侧是消费者集群,对应为业务系统。中间就是kafka集群,所有的处理都是围绕的kafka集群展开的,所以先说说kafka集群。
Kafka集群
kafka集群中有很机器,不管是物理的还是虚拟的,在kafka中每台机器都叫一个broker。然而在这些机器中,有一个是broker会成为controller,是通过zookeeper选举得出的,这个broker controller就是kafka集群中的leader,其他的为follwer。
Broker controller的选举
Kafka的Leader选举与Zookeeper集群leader选举不一样,Zookeeper集群,是通过Paxos算法,通过不同节点向其他节点发送信息来投票选举出leader,但是Kafka的leader的选举就没有这么复杂。
Kafka的Leader选举是通过在zookeeper上创建/controller临时节点来实现leader选举,并在该节点中写入当前broker的信息
利用Zookeeper的强一致性特性,一个节点只能被一个客户端创建成功,创建成功的broker即为leader,即先到先得原则,leader也就是集群中的controller,其他的机器会使用zk watch机制,watch这个controller临时节点。当leader宕机或者是网络故障导致session超时等原因与zookeeper失去链接,zookeeper会自动删除这个节点,其他的broker也就会收到通知,说明leader挂了,重新发起leader选举。
Topic & Broker & Partition & Replica
每一个topic在kafka集群中会被拆成很多的partition,打个比方一个Topic有10W条消息,可以拆成10个partition,每个接近1W,当然不会那么平均。partition数量可以配置,然而,每一个partition又可以有多个副本,对于副本我们叫replica。

上面这种图来自于https://www.cnblogs.com/fxjwind/p/4972244.html,我觉得画的挺好的,下面是摘自原文的一段话。
图中有4个 kafka brokers,并且Topic1有四个 partition(用蓝色表示)分布在4个 brokers 上,为 leader replica;
且每个 partition 都有两个 follower replicas(用橘色表示),分布在和 leader replica 不同的 brokers。
这个分配算法很简单,有兴趣的可以参考kafka的design。
然后又会引出另一个问题,partition leader怎么选举的,他并不是通过zk选出来的。
Partition Leader的选举
从上面Broker Controller的选举我们知道,
其他的broker follower会监听Controller是否还活着,相反Controller也会监听其他的Kafka Broker的所有信息。
如果controller宕机了,会重新选主。
Kafka会在Zookeeper上针对每个Topic维护一个称为ISR(in-sync replica,已同步的副本)的集合,
该集合中是一些分区的副本。只有当这些副本都跟Leader中的副本同步了之后,kafka才会认为消息已提交,
并反馈给消息的生产者。如果这个集合有增减,kafka会更新zookeeper上的记录如果其他broker宕机了, controller会读取该宕机broker上所有的partition在zookeeper上的状态,
并选取ISR列表中的一个replica作为partition leader,这个broker宕机的事情,controller也会通知zookeeper,zookeeper就会通知其他的kafka broker。
(如果ISR列表中的replica全挂,选一个幸存的replica作为leader; 如果该partition的所有的replica都宕机了,则将新的leader设置为-1,等待恢复,等待ISR中的任一个Replica“活”过来,并且选它作为Leader;或选择第一个“活”过来的Replica(不一定是ISR中的)作为Leader)