期待每天与你不期而遇~
也献给每个正在努力的我们
加油~
一、Hadoop HA 角色分配
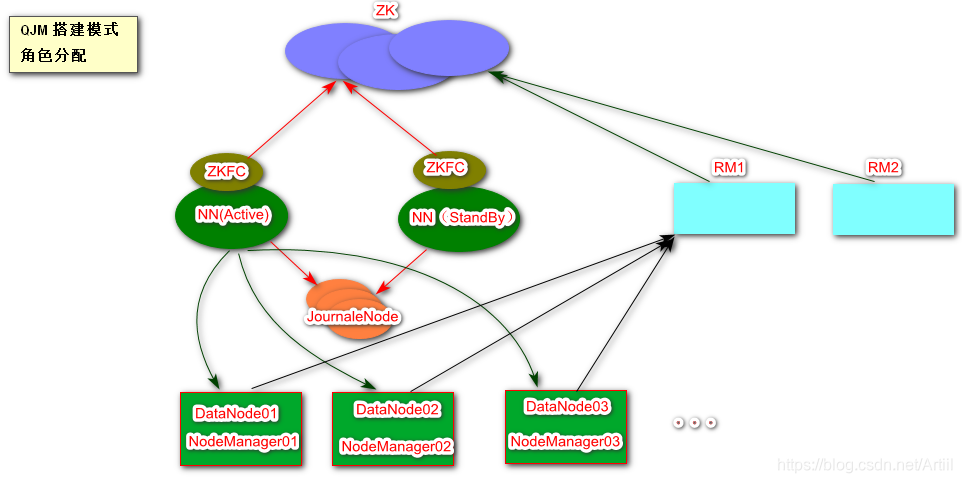
| HadoopNode01 | HadoopNode02 | HadoopNode03 |
|---|---|---|
| Zookeeper | Zookeeper | Zookeeper |
| NameNode(Active) | NameNode( Standby) | |
| ZKFC | ZKFC | |
| JournalNode | JournalNode | JournalNode |
| DataNode | DataNode | DataNode |
| ResourceManager | ResourceManager | |
| NodeManger | NodeManger | NodeManger |
ZKFC 作为一个ZK集群 的客户端 ,用来监控NN的状态信息,每个NN节点必须运行一个ZKFC
Journal Node 日志节点是HDFS 中一种高可用的解决方案,两个NN进行数据同步,会通过JN进行互相独立的通信。当active状态的NameNode的命名空间有任何修改,会告知大部分JN进程,standby状态的NameNode会读取JNS中变更信息,并一致监控edits log的变化,把变化应用与自己的命名空间,这样在active状态NameNode出现错误的时候,standby状态的NameNode能够立马替代其功能。
二、Hadoop HDFS 高可用
(1)配置主机名和IP的映射关系
[root@HadoopNodeX ~]# vi /etc/hosts
192.168.126.11 HadoopNode01
192.168.126.12 HadoopNode02
192.168.126.13 HadoopNode03
(2)关闭防火墙
[root@HadoopNode00 ~]# service iptables stop
[root@HadoopNode00 ~]# chkconfig iptables off
(3)同步时钟
[root@HadoopNode01 zookeeper-3.4.6]# date -s '2019-11-01 16:37'
(4)配置SSH免密登陆
[root@HadoopNodeX zookeeper-3.4.6]# ssh-keygen -t rsa # 先在每一台节点上生成公私玥
#下面命令 需要在每台节点上分别执行一遍
[root@HadoopNodeX zookeeper-3.4.6]# ssh-copy-id HadoopNode01
[root@HadoopNodeX zookeeper-3.4.6]# ssh-copy-id HadoopNode02
[root@HadoopNodeX zookeeper-3.4.6]# ssh-copy-id HadoopNode03
(5)Java 环境变量
[root@HadoopNode00 ~]# vi .bashrc
export JAVA_HOME=/home/java/jdk1.8.0_181
export PATH=$PATH:$JAVA_HOME/bin
(6)安装启动ZK
参考上章
(7)解压配置Hadoop
解压
配置环境(需要指定bin和sbin)
(8)配置 core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop-2.6.0/hadoop-${user.name}</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>60</value>
</property>
<!-- 设置机架脚本文件-->
<property>
<name>net.topology.script.file.name</name>
<value>/home/hadoop/hadoop-2.6.0/etc/hadoop/rack.sh</value>
</property>
(9 )创建机架脚本
/home/hadoop/hadoop-2.6.0/etc/hadoop/rack.sh
while [ $# -gt 0 ] ; do
nodeArg=$1
exec</home/hadoop/hadoop-2.6.0/etc/hadoop/topology.data
result=""
while read line ; do
ar=( $line )
if [ "${ar[0]}" = "$nodeArg" ] ; then
result="${ar[1]}"
fi
done
shift
if [ -z "$result" ] ; then
echo -n "/default-rack"
else
echo -n "$result "
fi
done
务必在启动之前给rack.sh 添加执行权限 chmod u+x /home/hadoop/hadoop-2.6.0/etc/hadoop/rack.sh
(10)创建机架文件
配置节点所在的机架位置
192.168.126.11 /rack1
192.168.126.12 /rack1
192.168.126.13 /rack2
(11)配置hdfs-site.xml
<configuration>
<!-- 设置副本因子数为3-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 自动故障转移-->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- zk配置-->
<property>
<name>ha.zookeeper.quorum</name>
<value>HadoopNode01:2181,HadoopNode02:2181,HadoopNode03:2181</value>
</property>
<!-- 命名服务为mycluster-->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!-- 命名服务为mycluster 下有nn1,nn2-->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<!-- 指定nn1 的host和port-->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>HadoopNode01:9000</value>
</property>
<!-- 指定nn2 的host和port-->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>HadoopNode02:9000</value>
</property>
<!-- 指定qjournal的host和port-->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://HadoopNode01:8485;HadoopNode02:8485;HadoopNode03:8485/mycluster</value>
</property>
<!-- 设置故障转移的策略-->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- ssh主动防御-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!--设置私钥的路径 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
</configuration>
(12)编辑slaves
/home/hadoop/hadoop-2.6.0/etc/hadoop/slaves
HadoopNode01
HadoopNode02
HadoopNode03
(13)启动
在启动之前请将之前的单节点的数据清空
rm -rf /home/hadoop/hadoop-2.6.0/hadoop-root/*
如果坏了(因为没有正常关闭 等原因):清空(1)停掉所有进程(2)删除zk datadir目录下除myid以外的所有文件(清空ZK)
扫描二维码关注公众号,回复: 11435792 查看本文章
(3)删除/hadoop-root目录文件夹(4)先启动ZK,在按照下面的指令执行一遍
[root@HadoopNodeX hadoop]# hadoop-daemon.sh start journalnode # 启动日志节点
[root@HadoopNode01 hadoop]# hdfs namenode -format # 在节点1上格式化namenode
[root@HadoopNode01 hadoop]# hadoop-daemon.sh start namenode # 在节点1上启动namendoe
[root@HadoopNode02 zookeeper-3.4.6]# hdfs namenode -bootstrapStandby # 在节点2上格式化namenode(Stabdby)
[root@HadoopNode02 zookeeper-3.4.6]# hadoop-daemon.sh start namenode # 在节点2上启动namendoe
[root@HadoopNode01 hadoop]# hdfs zkfc -formatZK # 格式化zkfc (此操作只进行一次即可,在nn所在节点上)
[root@HadoopNode01 zookeeper-3.4.6]# hadoop-daemon.sh start zkfc # 在节点1上启动zkfc
[root@HadoopNode02 zookeeper-3.4.6]# hadoop-daemon.sh start zkfc # 在节点2上启动zkfc
[root@HadoopNodeX zookeeper-3.4.6]# hadoop-daemon.sh start datanode #每台节点上启动dn
(14)日常维护
[root@HadoopNode01 hadoop]# start-dfs.sh
[root@HadoopNode01 hadoop]# stop-dfs.sh
三、Hadoop YARN 高可用
(1)配置yarn-site
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--Resource Manager-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>HadoopNode01:2181,HadoopNode02:2181,HadoopNode03:2181</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>rmcluster01</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>HadoopNode02</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>HadoopNode03</value>
</property>
</configuration>
(2)配置mared-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
(3)启动YRAN
[root@HadoopNode02 zookeeper-3.4.6]# yarn-daemon.sh start|stop resourcemanager # 在2节点上启动resourcemanager
[root@HadoopNode03 zookeeper-3.4.6]# yarn-daemon.sh start|stop resourcemanager # 在3节点上启动resourcemanager
[root@HadoopNodeX hadoop]# yarn-daemon.sh start|stop nodemanager # 每个节点上启动nodemanager
(3)启动YRAN
[root@HadoopNode02 zookeeper-3.4.6]# yarn-daemon.sh start|stop resourcemanager # 在2节点上启动resourcemanager
[root@HadoopNode03 zookeeper-3.4.6]# yarn-daemon.sh start|stop resourcemanager # 在3节点上启动resourcemanager
[root@HadoopNodeX hadoop]# yarn-daemon.sh start|stop nodemanager # 每个节点上启动nodemanager
