

日记的管理方式发生了改变——单个namenode的模式,日记文件是直接写到namenode里面就可以了。现在要实现的是高可用的模式,高可用就需要两台namenode,而且管理模式是一样的,引入了两台那么日记文件就必须要实现共享与同步,既然要实现共享,一个是namenode之间点对点的连接,但是namenode的是高并发的模式,本身任务就很多,不可能随意的增加功能,则就才有第二个方法:需要新增加一层,以供两个namenode去获取日记,这层和zookeeper的功能模式差不多,都能解决单点故障的问题出现,加入journalnode(文件管理机制)这层第三方存储系统,管理文件日记。文件服务器的架构和zookeeper的架构是一样的,选举模式,奇数台。选举老大。
数据的同步问题,namenode的日记同样改变了回滚策略,回滚的文件直接同步到journalnode,一台是active(可读写),一台是standby(只能读取),seocendery就不需要了,操作日记记录的是块上传的操作,一个文件一百个块,就记录一百次操作,但在fsimager里面记录的是元数据,目录数,日记比镜像大,所以采用快照方式,之所以合并,是为了避免挂了后再重启,加载的时间不长,checkpoint就得有standby这台namenode进行负责。
状态的切换——每一台namenode都会启动一个zkfc组件(两个是一起的),zkfc状态都会和zookeeper去协调,当active这台的namenode后挂了,则此台zkfc就会通知zookeeper将子节点删除,
此台namenode的子节点被删除了,另一台standby状态的namenode的zkfc就知道了,就要做准备工作,完成一系列的功能(namenode要管理元数据,元数据在内存里,在切换前,要加载镜像和
操作日记得出元数据过来)。但是要预防脑裂的情况(预防脑裂的方式有两种:1、当出现问题的时候,另一台zkfc会执行一个kill当前这台active这台namenode的命令,2、用户自定义的脚
本直接杀掉挂的这台namenode)

高可用安装、配置
vi hdfs-site.xml
<configuration>
<!--配置副本数-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--是否开启hdfs文件系统的权限-->
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<!--元数据存放目录-->
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/hadoopdata/dfs/name</value>
</property>
<!--数据内容存放目录-->
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/hadoopdata/dfs/data</value>
</property>
<!--是否启用webhdfs (rest api)-->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<!--配置虚拟服务名-->
<property>
<name>dfs.nameservices</name>
<value>gp1923</value>
</property>
<!--为虚拟服务名指定namenode别名-->
<property>
<name>dfs.ha.namenodes.gp1923</name>
<value>aa1,aa2</value>
</property>
<!--为namenode别名指定通信地址-->
<property>
<name>dfs.namenode.rpc-address.gp1923.aa1</name>
<value>hadoop0001:9000</value>
</property>
<property>
<name>dfs.namenode.rpc-address.gp1923.aa2</name>
<value>hadoop0002:9000</value>
</property>
<!--配置aa1、aa2的web ui监控地址-->
<property>
<name>dfs.namenode.http-address.gp1923.aa1</name>
<value>hadoop0001:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.gp1923.aa2</name>
<value>hadoop0002:50070</value>
</property>
<!--配置journalnode通信地址-->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop0001:8485;hadoop0002:8485;hadoop0003:8485/gp1923</value>
</property>
<!--配置失败转移的java类-->
<property>
<name>dfs.client.failover.proxy.provider.gp1923</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!--防止脑裂-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!--设置ssh fencing操作超时时间-->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
<!--存储journalnode本地路径-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/usr/local/hadoopdata/journalnode/data</value>
</property>
<!--是否开启自动失败转移-->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
</configuration>vi core-site.xml
<configuration>
<!--虚拟服务名-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://gp1923</value>
</property>
<!--指定zk集群地址-->
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop0001:2181,hadoop0002:2181,hadoop0003:2181</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
</configuration>vi yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--是否启动yarn的rm的HA功能-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!--是否开启失败自动转移-->
<property>
<name>yarn.resourcemanager.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!--yarn的rm的HA的服务ID-->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>gp1923yarn</value>
</property>
<!--yarn的rm的HA的服务ids的逻辑rmid的列表-->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!--为逻辑rm1配置所启动的主机-->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadoop0001</value>
</property>
<!--为逻辑rm2配置所启动的主机-->
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hadoop0002</value>
</property>
<!--为逻辑rm1配置web ui监控端口-->
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>hadoop0001:8088</value>
</property>
<!--为逻辑rm2配置web ui监控端口-->
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>hadoop0002:8088</value>
</property>
<!--配置zk集群所在主机-->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hadoop0001:2181,hadoop0002:2181,hadoop0003:2181</value>
</property>
</configuration>


![]()
![]()
![]()

启动
![]()
![]()


停止



ssh是不会加载配置文件的


第一步启动完


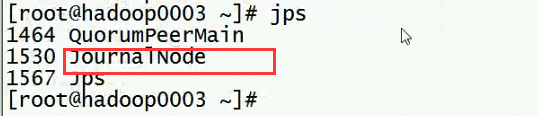
第二步完成了

然后就是先启动hadoop0001的namenode


将初始元数据共享给hadoop0002,有两种方法:
方法一:直接拷贝
![]()
方法二:通过hdfs命令,把它启动到standby里面,就是初始化standby

最后一步







现重新启动zookeeper,然后在用全启动


严格按照步骤操作:
1、启动zookeeper
2、启动journalnode
3、格式化hdfs
hdfs namenode -format
先启动hadoop0001上的namenode
共享数据
1、拷贝
scp -r /home/hdfsdata/ root@hadoop0002:/home/
2、通过hdfs命令
bin/hdfs namenode -bootstrapStandby
4、格式化zkfc
hdfs zkfc -formatZK
5、启动
hdfs dfs
dfsadmin
namenode
zkfc
haadmin -
