Scrapy 和 scrapy-redis的区别
scrapy是一个Python爬虫框架,爬取效率极高,具有高度定制性,但是不支持分布式。而scrapy-redis一套基于redis数据库、运行在scrapy框架之上的组件,可以让scrapy支持分布式策略,Slaver端共享Master端redis数据库里的item队列、请求队列和请求指纹集合。而为什么选择redis数据库,是因为redis支持主从同步,而且数据都是缓存在内存中的,所以基于redis的分布式爬虫,对请求和数据的高频读取效率非常高。
pip install scrapy-redis
Scrapy-redis提供了下面四种组件(components):
Scheduler
Duplication Filter
Item Pipeline
Base Spider
Scheduler:
Scrapy改造了python本来的collection.deque(双向队列)形成了自己的Scrapy queue,但是Scrapy多个spider不能共享待爬取队列Scrapy queue, 即Scrapy本身不支持爬虫分布式,scrapy-redis 的解决是把这个Scrapy queue换成redis数据库(也是指redis队列),从同一个redis-server存放要爬取的request,便能让多个spider去同一个数据库里读取。
Scrapy中跟“待爬队列”直接相关的就是调度器Scheduler,它负责对新的request进行入列操作(加入Scrapy queue),取出下一个要爬取的request(从Scrapy queue中取出)等操作。它把待爬队列按照优先级建立了一个字典结构,然后根据request中的优先级,来决定该入哪个队列,出列时则按优先级较小的优先出列。为了管理这个比较高级的队列字典,Scheduler需要提供一系列的方法。但是原来的Scheduler已经无法使用,所以使用Scrapy-redis的scheduler组件。
Duplication Filter:
Scrapy中用集合实现这个request去重功能,Scrapy中把已经发送的request指纹放入到一个集合中,把下一个request的指纹拿到集合中比对,如果该指纹存在于集合中,说明这个request发送过了,如果没有则继续操作。
def request_seen(self, request):
# self.request_figerprints就是一个指纹集合
fp = self.request_fingerprint(request)
# 这就是判重的核心操作
if fp in self.fingerprints:
return True
self.fingerprints.add(fp)
if self.file:
self.file.write(fp + os.linesep)
在scrapy-redis中去重是由Duplication Filter组件来实现的,它通过redis的set 不重复的特性,巧妙的实现了Duplication Filter去重。scrapy-redis调度器从引擎接受request,将request的指纹存⼊redis的set检查是否重复,并将不重复的request push写⼊redis的 request queue。
引擎请求request(Spider发出的)时,调度器从redis的request queue队列⾥里根据优先级pop 出⼀个request 返回给引擎,引擎将此request发给spider处理。
Item Pipeline:
引擎将(Spider返回的)爬取到的Item给Item Pipeline,scrapy-redis 的Item Pipeline将爬取到的 Item 存⼊redis的 items queue。

修改过Item Pipeline可以很方便的根据 key 从 items queue 提取item,从⽽实现items processes集群。
Base Spider:
不在使用scrapy原有的Spider类,重写的RedisSpider继承了Spider和RedisMixin这两个类,RedisMixin是用来从redis读取url的类。
当我们生成一个Spider继承RedisSpider时,调用setup_redis函数,这个函数会去连接redis数据库,然后会设置signals(信号):
一个是当spider空闲时候的signal,会调用spider_idle函数,这个函数调用schedule_next_request函数,保证spider是一直活着的状态,并且抛出DontCloseSpider异常。
一个是当抓到一个item时的signal,会调用item_scraped函数,这个函数会调用schedule_next_request函数,获取下一个request。
scrapy_reedis架构
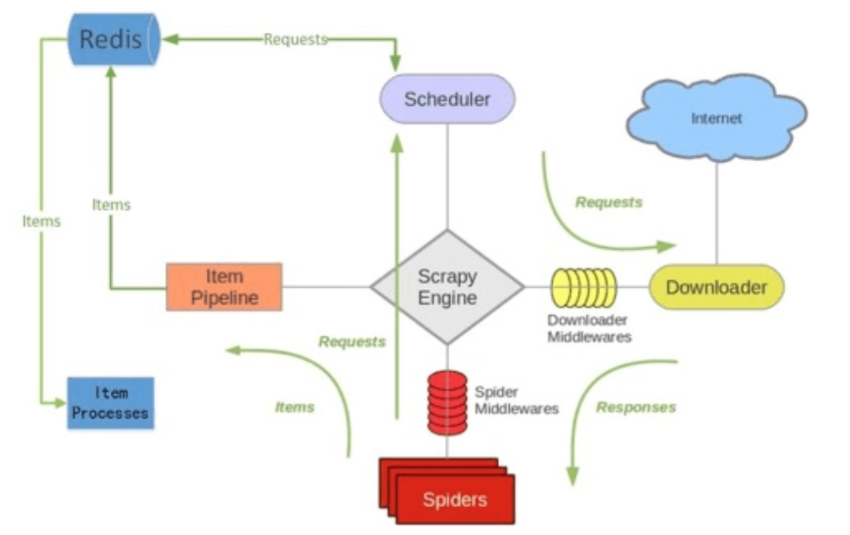
Scrapy-Redis分布式策略:
假设有四台服务器:任意一台电脑都可以作为 Master端 或 Slaver端,比如:
--Master端(核心服务器) :使用 一台服务器当做Master,搭建一个Redis数据库,不负责爬取,只负责url指纹判重、Request的分配,以及数据的存储
--Slaver端(爬虫程序执行端) :使用 三台服务器作为Slaver,负责执行爬虫程序,运行过程中提交新的Request给Master

首先Slaver端从Master端拿任务(Request、url)进行数据抓取,Slaver抓取数据的同时,产生新任务的Request便提交给 Master 处理;
Master端只有一个Redis数据库,负责将未处理的Request去重和任务分配,将处理后的Request加入待爬队列,并且存储爬取的数据。
1、修改settings.py文件,最简单的方式是使用redis替换机器内存,你只需要在 settings.py 最会面加上以下代码,就能让你的爬虫变为分布式。
# REDIS配置
# 去重类--指定那个去重方法给 request 对象去重
# DUPEFILTER_CLASS = 'scrapy_redis.dupefilter.RFPDupeFilter'
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# 队列--指定scheduler队列,调度器内存的是待爬取连接和已爬取对象指纹
SCHEDULER = 'scrapy_redis.scheduler.Scheduler'
# 队列内容是否持久化保存--为False的时候,关闭redis的时候清空redis
SCHEDULER_PERSIST = True
REDIS_URL = 'redis://192.168.160.100:6379'
自定义爬虫类继承RedisSpider
class JDSpider(RedisSpider):
name = "jdSpider"
redis_key = "JDUrlsSpider"
def parse(self, response):
print(response.url)
# 编写爬虫
pass
pass
可以写一个单独的爬虫文件,用来获取爬取路由,如:
import redis
# 1.生成指定的路由,写入到redis中
conn = redis.Redis(host="192.168.160.100", port=6379)
url = ''
conn.lpush("JDUrlsSpider", url)
- scrapy_redis运行命令:
写入到一个py文件执行这个py文件就可以启动爬虫
from scrapy import cmdline
if __name__ == '__main__':
cmdline.execute("scrapy crawl jdSpider".split())
pass