说到pandas大家并不陌生,他是numpy的一个工具,起初是为了金融数据分析工具而开发出来,09年开源出来后,类库越来越强大,使用者也逐日增加,小斌哥我就是“潘大师”的新粉丝,特意来学习一下使用并将使用方法详细记录下来,方便大家查阅~

简单介绍
Pandas是python的一个数据分析包,最初由AQR Capital Management于2008年4月开发,并于2009年底开源出来,目前由专注于Python数据包开发的PyData开发team继续开发和维护,属于PyData项目的一部分。Pandas最初被作为金融数据分析工具而开发出来,因此,pandas为时间序列分析提供了很好的支持。 Pandas的名称来自于面板数据(panel data)和python数据分析(data analysis)。panel data是经济学中关于多维数据集的一个术语,在Pandas中也提供了panel的数据类型。
数据结构
Series:一维数组,与Numpy中的一维array类似。二者与Python基本的数据结构List也很相近。Series如今能保存不同种数据类型,字符串、boolean值、数字等都能保存在Series中。
Time- Series:以时间为索引的Series。
DataFrame:二维的表格型数据结构。很多功能与R中的data.frame类似。可以将DataFrame理解为Series的容器。
Panel :三维的数组,可以理解为DataFrame的容器。
Panel4D:是像Panel一样的4维数据容器。
PanelND:拥有factory集合,可以创建像Panel4D一样N维命名容器的模块。
以上内容来自百度百科
开始学习
看过他的数据结构感觉其实也并没有很难学的样子,那我们就赶快开始吧~既然他是用来处理数据的工具,第一件事肯定是要读取\保存文件咯!
先导入包
import pandas as pd
pandas很重要的一个类叫做DataFrame,这个类相当于Excel的一个sheet,我们创建和执行什么操作,都是靠这个类实现的,
创建DataFram对象
df = pd.DataFrame({'ID:': [1, 2, 3], 'NAME:': ['JosephBean', 'Nick', 'Joshua']})
里面是一个字典,KEY对应的是你的每一列的第一个值,VALUE对应的是你每列的属性
保存文件
df.to_excel(r'E:\people.xlsx')
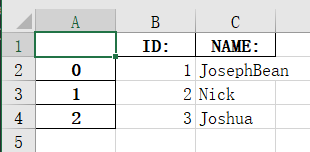
可以看出来这个ExcelA列是多余的索引,我们想把他去掉,就需要设置索引:
df = df.set_index('ID:')
想把我自定义的’ID:'设置为索引,我们再看一下结果:
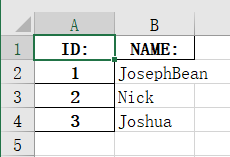
怎么样?还是很Easy的吧!

完整代码:
import pandas as pd
df = pd.DataFrame({'ID:': [1, 2, 3], 'NAME:': ['JosephBean', 'Nick', 'Joshua']})
df = df.set_index('ID:')
df.to_excel(r'E:\people.xlsx')
读取文件
说了写文件,我们开始读文件
excel = pd.read_excel(r'E:\people.xlsx', header=0)
我们就读刚才写进去的那个文件,怎么预览文件的内容呢?莫非要双击文件打开?no! 那样太傻了
直接
print(excel)
这样虽然可以正确打印出来,但是如果文件一旦有几万条数据,这样一条一条打印太占内存了,想看有几行几列使用
print(excel.shape)
想看列的名字:
print(excel.columns)
打印结果:
Index(['ID:', 'NAME:'], dtype='object')
想看文件内前五个(默认是看五个):
print(excel.head())
当然可以自定义多少行,比如想看十行,就是
print(excel.head(10))
想从底部开始就是:
print(excel.tail())
假如我们的文件第一行有奇怪的东西呢?
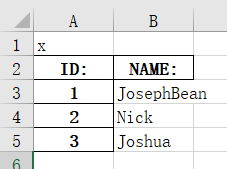
再执行一下excel.columns,结果就成了:Index(['x', 'Unnamed: 1'], dtype='object'),不是ID:和NAME:了,想要解决,就更换头的行号,默认第0行是header,但是我们可以手动设置为1:
excel = pd.read_excel(r'E:\people.xlsx', header=1)
这样就又正常了,需要注意的是,如果第一行没有值:
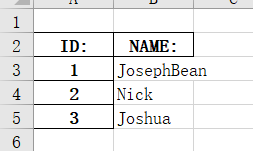
pandas会自动将header设置为1的,还是很智能的
如果我们想给数据添加标题呢?
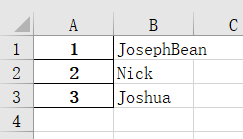
只需:
excel = pd.read_excel(r'E:\people.xlsx', header=None)
excel.columns = ['ID', 'NAME']
excel = excel.set_index('ID')
excel.to_excel(r'E:\people.xlsx')
- 第一行是读取
- 第二行是设置列的值
- 第三行是设置索引为ID,否则会在第一列多出一列索引
- 第四行是保存
执行结果:
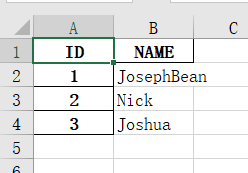
需要注意的是,此时再执行:print(excel.columns),就只有NAME一个值了,pandas把索引和列值是分开的,打印结果:Index(['NAME'], dtype='object')
但是此时我们如果再打印一下:print(excel.head()),会发现
ID NAME
0 1 JosephBean
1 2 Nick
2 3 Joshua
烦人的索引又出来了!!如果把保存那一行代码再执行一次,第一列就又多出来索引的那些数字了,想去掉只需在读取的时候设置索引index_col为你想要的值就好了:
excel = pd.read_excel(r'E:\people.xlsx', index_col='ID')
知根知底Series
前面我们已经说了pandas的数据结构,他是一个一维数组:
import pandas
series = pd.Series(['JosephBean', 'Nick', 'Marry'], index=['Handsome guy', 'Brother', 'girl'])
print(series)
第一个参数:data
第二个参数:index
打印结果:
Handsome guy JosephBean
Brother Nick
girl Marry
dtype: object
可以看出来这几乎等于python中的字典,存在映射关系
既然Series可以看做是一个字典,怎么能让他变成之前的Excel那样的形式呢?

完全可以设计成形如上图这样的格式,一个Series的key是索引Index,value是Series中对应的数据,我们只需要给Series加个名字Name就可以了
s1 = pd.Series([1, 2, 3], index=[0, 1, 2], name='A')
s2 = pd.Series([4, 5, 6], index=[0, 1, 2], name='B')
s3 = pd.Series([7, 8, 9], index=[0, 1, 2], name='C')
frame = pd.DataFrame({s1.name: s1, s2.name: s2, s3.name: s3})
print(frame)
我们可以看到每一个Series多了一个参数name,现在变成了三个参数了
第一个参数: 相当于一个list,里面存储着数据
第二个参数: 索引,与Series中的数据(data)一一进行匹配,s1的index是0,1,2,s2的index也是0,1,2,所以他们相同索引值下对应的Series数据应该是同一位置下的:
输出结果:
A B C
0 1 4 7
1 2 5 8
2 3 6 9
可以看出来索引为0对应s1的Series是1,对应s2的是4,对应s3的是7,所以索引为0对应的这一行数据为1,4,7,而s1的name为‘A’,所以A这列对应的数据是1,2,3
第三个参数: Name是Series中data的名字
数据填充怎么玩儿
众所周知Excel有数据填充功能,非常的方便,我们通过pandas来还原一下这个功能,原始数据是这样的:

A列如何变成递增序列,C列怎么变成YES和NO的交替,D怎么变成递增一天的日期格式呢?
首先我们先调整一下格式,因为这个例子没有从第1行开始,看一下pycharm中的打印结果:

他是从第0行开始的,并没有从我们想要的第5行开始,所以我们需要用到read_excel方法的另一个参数:skiprows,我们跳过四行,就会来到第5行了,再看一下结果:

是从第五行开始,但是并没有从第三列开始,所以需要另外一个参数:usecols,这个是你使用多少列,我使用的是C-F列
所以usecols的值为C:F,或者C,D,E,F,再看一下打印结果:

这下就对了,接下来我们正式开始填充了:
import pandas as pd
from datetime import date, timedelta
test = pd.read_excel('E:/tianchong.xlsx', skiprows=4, usecols='C:F', dtype={'A': str, 'B': str, 'C': str, 'D': str})
start = date(2020, 2, 27)
for i in test.index:
test['A'].at[i] = i + 1
test['C'].at[i] = 'YES' if i % 2 == 0 else 'NO'
test['D'].at[i] = start + timedelta(days=i)
print(test)
为了格式统一,我们把dtype每一列都设置为str属性,否则默认的NaN执行完for循环后会变成浮点数,日期会变成yyyy-MM-dd HH:mm:SS这样的形式
我们执行一次for循环,把name为A的这一列,每一列都多加一个1,name为C的这一列进行一次判断,如果i为基数就是YES,为偶数就是NO,第三个是日期,麻烦一点,我们想递增天数,就直接start + timedelta(days=i),如果想递增年,就需要test['D'].at[i] = date(start.year + i, start.month, start.day),也很简单,最麻烦的就是递增月份,因为月份超过12月就得重新从1月份开始,否则就会报错,我们需要使用一个小方法:
def add_month(pre_dates, ad_month):
year = ad_month // 12 # 加了ad_month之后有几年
month = pre_dates.month + ad_month % 12 # 月份不能超过12,但是pre_dates.month之和可能依然超过12,所以还需要第二次取余
if month != 12:
year += month // 12
month = month % 12
return date(pre_dates.year + year, month, pre_dates.day)
这样我们新增保存操作再执行:
test = pd.read_excel('E:/tianchong.xlsx', skiprows=4, usecols='C:F', dtype={'A': str})
start = date(2020, 2, 27)
for i in test.index:
test['A'].at[i] = i + 1
test['C'].at[i] = 'YES' if i % 2 == 0 else 'NO'
# test['D'].at[i] = start + timedelta(days=i)
# test['D'].at[i] = date(start.year + i, start.month, start.day)
test['D'].at[i] = add_month(start, i)
print(test)
就正常了:

篇幅太多了,我们这一次就结束了,本文的学习资料是大佬Timothy老师的Python数据分析-pandas玩转Excel
有问题欢迎评论区指正,觉得有用的拜托点个赞再走呗~这个对我真的很重要,谢谢!
