所谓狗急跳墙. …我呸,所谓富贵险中求,正是因为毕设很难,所以才有机会学习新的知识,这篇总结更是充满了芝士,连我自己学完都有些欲罢不能了~~

函数填充
用过Excel的小伙伴们肯定知道Excel的填充功能是强大的一X,那么对于pandas来说,如何实现相似的功能呢?我们先举个栗子~


我们想计算一下总分,如果是Excel,想必大家都很会操作:
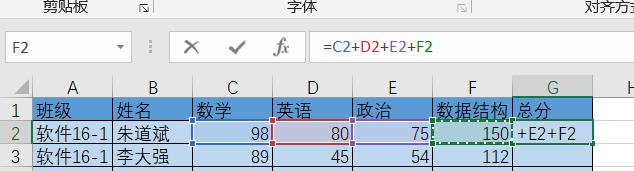
点击一下总分,然后等号后面写四个单元格的位置相加就可以了,想把函数扩充,只需要往下拉,超级方便:

好了,还是这个数据,我们如何用pandas来操作嘞?

怎么操作
import pandas as pd
score = pd.read_excel('E:/functionSpread.xlsx')
score['总分'] = score['数学'] + score['英语'] + score['政治'] + score['数据结构']
print(score)

我们可以看出来操作非常简单,只需要一行代码,这里每个加号加的是整列而不是一个单元格而已, 非常的方便,但是如果你想操作的是其中的一部分,不是整列,那就需要用第一篇用到的for循环的形式了:
import pandas as pd
score = pd.read_excel('E:/functionSpread.xlsx')
for i in range(5, 18):
score['总分'].at[i] = score['数学'].at[i] + score['英语'].at[i] + score['政治'].at[i] + score['数据结构'].at[i]
print(score)
通过at里面有索引,是一个单元格一个单元格进行赋值操作的
班级 姓名 数学 英语 政治 数据结构 总分
0 软件16-1 朱道斌 98 80 75 150 NaN
1 软件16-1 李大强 89 45 54 112 NaN
2 软件16-1 张晓梅 63 21 54 64 NaN
3 软件16-1 朱莉 86 51 54 39 NaN
4 软件16-2 梅梅 88 56 54 11 NaN
5 软件16-1 赵美丽 23 15 55 96 189.0
6 软件16-1 韩大海 34 81 12 84 211.0
7 软件16-2 强子 14 56 64 54 188.0
8 软件16-1 二狗子 14 55 65 94 228.0
9 软件16-1 小美眉 23 34 44 16 117.0
10 软件16-1 刘备 35 51 22 54 162.0
11 软件16-1 郭老师 123 15 88 84 310.0
12 软件16-2 迷糊桃 23 15 26 55 119.0
13 软件16-1 老八 88 97 51 6 242.0
14 软件16-1 小汉堡 54 68 51 464 637.0
15 软件16-1 刘波 15 51 21 46 133.0
16 软件16-1 李鹏展 66 52 44 46 208.0
17 软件16-2 词穷了 77 98 97 94 366.0
18 软件16-1 随便 15 21 88 494 NaN
19 软件16-1 貂蝉 51 8 13 4 NaN
20 软件16-2 阿森纳 26 3 68 8 NaN
21 软件16-1 约瑟夫 83 32 23 56 NaN
比如我们现在想根据数学成绩进行排序,怎么实现呢?
排序的实现
score.sort_values(by='数学', inplace=True)
只需要这一句话,就可以轻易实现:
班级 姓名 数学 英语 政治 数据结构 总分
7 软件16-2 强子 14 56 64 54 NaN
8 软件16-1 二狗子 14 55 65 94 NaN
18 软件16-1 随便 15 21 88 494 NaN
15 软件16-1 刘波 15 51 21 46 NaN
5 软件16-1 赵美丽 23 15 55 96 NaN
9 软件16-1 小美眉 23 34 44 16 NaN
12 软件16-2 迷糊桃 23 15 26 55 NaN
20 软件16-2 阿森纳 26 3 68 8 NaN
6 软件16-1 韩大海 34 81 12 84 NaN
10 软件16-1 刘备 35 51 22 54 NaN
19 软件16-1 貂蝉 51 8 13 4 NaN
14 软件16-1 小汉堡 54 68 51 464 NaN
2 软件16-1 张晓梅 63 21 54 64 NaN
16 软件16-1 李鹏展 66 52 44 46 NaN
17 软件16-2 词穷了 77 98 97 94 NaN
21 软件16-1 约瑟夫 83 32 23 56 NaN
3 软件16-1 朱莉 86 51 54 39 NaN
4 软件16-2 梅梅 88 56 54 11 NaN
13 软件16-1 老八 88 97 51 6 NaN
1 软件16-1 李大强 89 45 54 112 NaN
0 软件16-1 朱道斌 98 80 75 150 NaN
11 软件16-1 郭老师 123 15 88 84 NaN
但是成绩是从低到高,很不好看,我们需要加一个参数ascending,这个参数玩儿过数据库的小伙伴都知道是升序的意思,默认这个参数是True,我们只需要把它设置为False就可以降序排列了
此时如果我们想根据两列数据进行排序呢?数学从高到底,英语从低到高,也很简单,只需要:
score.sort_values(by=['数学', '英语'], inplace=True, ascending=[False, True])
之前by后面只有一个参数,我们把它变成一个元组,就可以根据多个参数进行排序了
如何过滤
我们想筛选出高于某个分数而低于某个分数的学生,应该怎么做呢?
score = score.loc[score.数学.apply(lambda a: 80 < a < 150)] \
.loc[score.英语.apply(lambda a: 60 < a < 100)]
想过滤通过loc方法,就是locate,意思是定位,然后选择那一列应用函数,我想让score这个对象的数学这一列应用一个函数,所以是score.loc[score.数学.apply(函数名)],应用什么函数呢?这里用了lambda表达式,他拆开来就是:
def name(a):
return 60 < a < 100
如果不会lambda表达式也可以拆开写,然后在apply里面调用这个函数名,注意不要带括号:
score = score.loc[score.数学.apply(name)]
只把函数的名字调用了就可以,不要写成name()
新增一个过滤条件,就继续调用loc,为了不要一行太满,所以通过 \ 换行
过滤还是很容易的,有帮助的话记得帮忙点个赞,谢谢~