图论/树算法总参考:
https://www.bilibili.com/video/BV1BJ411e79i?from=search&seid=736566991405891381&rt=V%2FymTlOu4ow%2Fy4xxNWPUZ9JZcKWNbG1VEA96%2B1r70Cc%3D



顶点类型即 图存储的是什么类型的数据
邻接矩阵 的类型 即 权重


概念递增关系: 无向图(边edge)-- 有向图(Arc弧,出度入度Degree)–网network(权weight)
顶点vertex
顶点到顶点: path

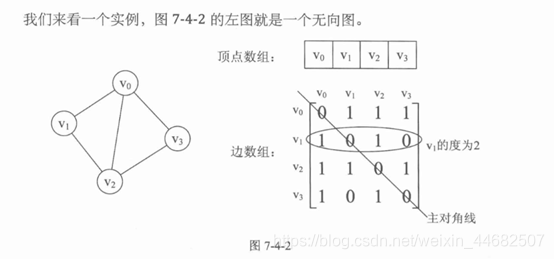
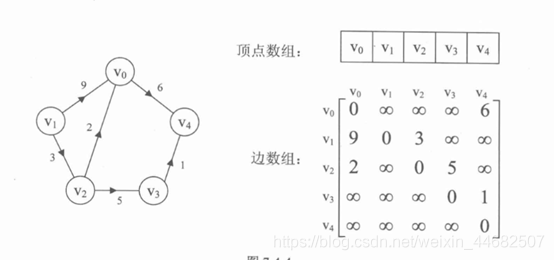
正无穷表示有边,但没有权值, 因为有些权值可以是 负值或0
正数表示 权值 且 两顶点间有边
零表示两顶点间 没有边



图的两个核心就是: 顶点 , 弧(边)
1.一维矩阵存储顶点值,邻接矩阵表示弧(有没有,方向,权值) 方向:横着看
2.邻接表即 数组 + 链表。
数组存储自定义的一个结构体: 顶点值+指向边表的指针
链表存储一个顶点的所有邻接点的下标(有没有弧,方向,权值)
方向:以顶点为弧尾来建立邻接表

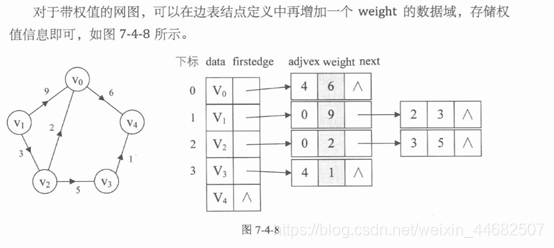
方向: 一般将顶点作为弧尾来明确方向,容易得到某个顶点的出度(outdegree)。 如果想知道某表的入度(indegree),就将顶点作为弧头来明确方向,建立逆邻接表。
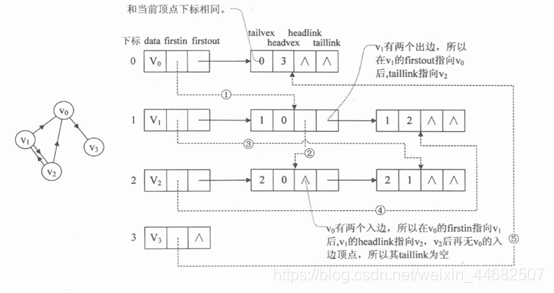
邻接表与逆邻接表结合, 就是十字链表。 可以同时表示出度和入度
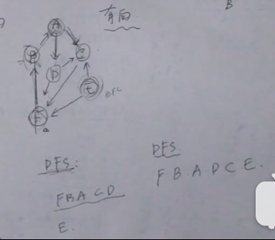
深度优先搜索的步骤分为 1.固定一个方向递进下去 2.回溯上来。
顾名思义,深度优先,则是以深度为准则,先一条路走到底,直到达到目标。这里称之为递归下去。
否则既没有达到目标又无路可走了,那么则退回到上一步的状态,走其他路。这便是回溯上来。(右手原则) 右手原则指的是自己代入迷宫的 第一视角,面对岔路口只走最右手
引入一套机制:

引入一个栈,来记录走过的节点,从而实现回溯
引入 wihte, grey ,black 三种颜色表示 顶点的状态。
white: 没有走过的点, grey: 走过的点,但这个点还有白色临接点(即可回溯的点),
black: 走过且邻接点都走过, 即路的尽头
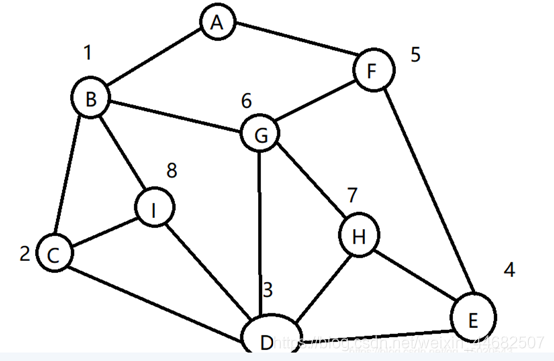

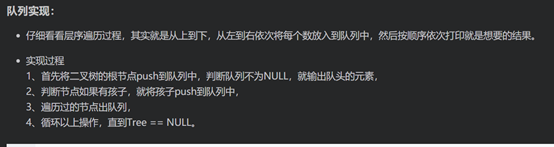
广度优先遍历:
一层层的向外延伸, 一次只延伸一层节点。
引入队列机制: 记录即将访问的节点
1 创建一个队列,遍历的起始点放入队列
2 从队列中取出一个元素,打印它,并将其未访问过的子结点放到队列中
3 重复2,直至队列空
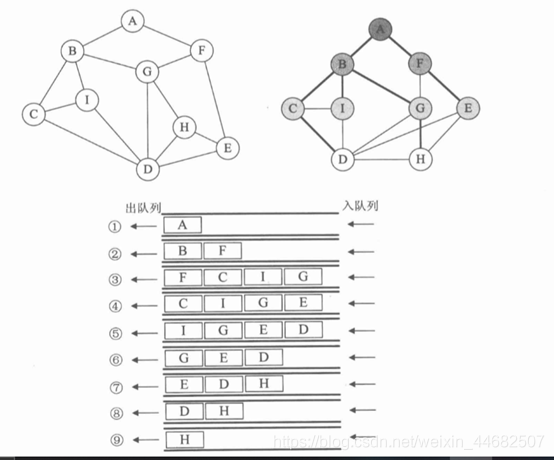
然后用一个数组来接收出栈的节点, 从而记录每个节点完成遍历

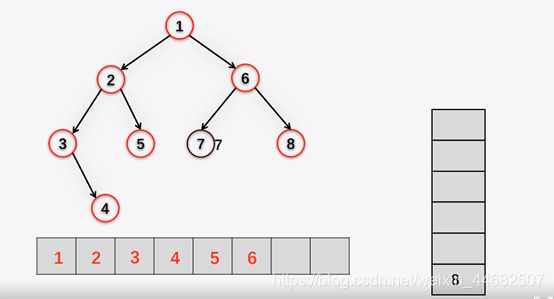
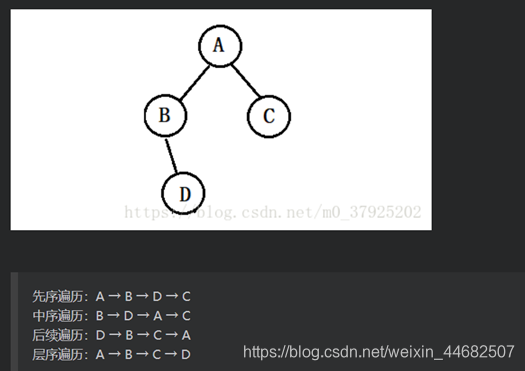
树的遍历就是递归的进行 根左右,左根右,左右根的访问
所谓遍历就是:大树化小树,小树化元素。 左根右 指的是 左子树,根,右子树

前序遍历就是右手原则的深度优先遍历 右手走到底, 没路了再回来走左手

经典题: 给前中后序遍历顺序, 请重构树
1.必须给中序,否则无法重构。 所以只有 前中, 后中 两种情况
2. 前序的意义就是有第一个节点, 中序的意义就是划分左右子树
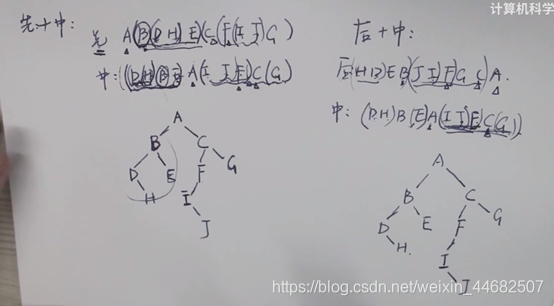
即通过前,后序遍历来找 子树的根节点, 然后带入中序判断
在有向图中,可能需要执行多次DFS才能遍历整个图(一个起始点走没了,再换个起始点)
最小生成树: 解决权值和最小问题
连通图: 图中从一个顶点可以到达任意一顶点(至少有一条路) n个顶点时,至少有n-1个边
完全图: 图中的任何两个点都可以直接连通 , n个顶点时,有n(n − 1) / 2条边
生成树:能连通所有顶点而又不产生回路的任何子图都是图的生成树
树一般来说是基于图而生的,而树是一种特殊的图:无环连通图。
解决问题: 路段建设的费用不同(权值),市长连通所有村要花费的最小费用
https://www.bilibili.com/video/BV1EJ411S7A2
1.Kruscal算法:在不构成环的前提下,一直取图中的最小边(以边为导向)
2.Prim算法:在不构成环的前提下,一直找离最小生成树最近的点并接入最小生成树(以点为导向),每次只能取一个点和一个边
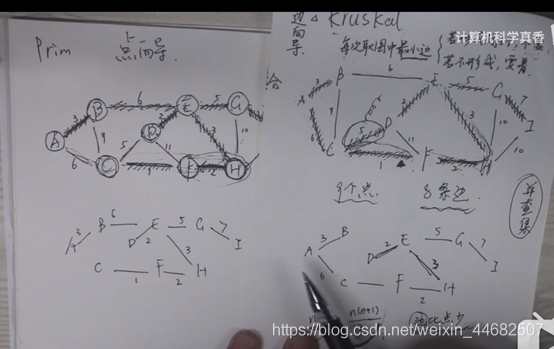
两者比较: 最终的结果肯定是相同的
Prim算法是直接查找,多次寻找邻边的权重最小值,而Kruskal是需要先对权重排序后查找的
Kruskal在算法效率上是比Prim快的,因为Kruskal只需一次对权重的排序就能找到最小生成树,而Prim算法需要多次对邻边排序才能找到
边比较少时(边比点少),用Kruscal算法
点少时,用prim算法
最短路径算法:
Dijkstra(迪杰斯特拉),是贪心算法的一个应用
https://www.youtube.com/watch?v=pVfj6mxhdMw
求从一个顶点出发,到任意一个点的最短路径
1.选择一个出发点,引入两个序列: unvisited node{A,B,C,D} 记录还没有访问过的点
distance{A:5 B: ∞ C:∞ D:∞} 记录点到出发点的距离
2.通过广度优先算法层层访问顶点, 访问后移出unvisit表,并将距离更新到distance表中
访问已知距离中最近的点


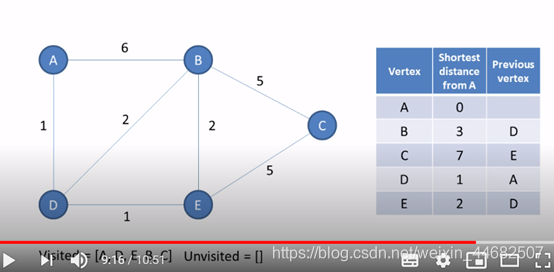

选择一个出发点,引入一个序列:unvisited node{A,B,C,D}
引入一个表,两个属性:起始点到各点的最短距离,最短路径(A->D->E->C)
1.访问距离起始点最近的点B
2.计算B点所有邻接点到起始点A的距离(即起始点到B点的距离+B到邻接点的距离)
3.与表中路径比较, 如果比已知最短路径更短, 更新路径和距离
4.完成对B点的访问,将B点移出unvisit序列
重复上述步骤
核心思想是基于已知的最短路径,逐步比较出其他最短路径。然后比较出了到每个点的最短路径

想求A到H(明确的起点和终点)的最短路径, 还是得把全图走完比较完,才能确保A到H的最短路径。过程同上
串就是存储 char的 数组(或动态数组)。极其简单

