以下是用transfer learning即迁移学习做分类任务的实验报告,实验中简单的使用pytorch的resnet18预训练模型重新训练了一个二分类的模型,提供pytorch源码
1.Overview
In this experiment, I will complete a classification task by using transfer learning. Transfer learning is using pretrained model which has been trained in the huge data to train our own dataset. Through doing this, we can achieve the better performance in our dataset in a short period of time.(在这个实验中,我将使用转移学习完成一个分类任务。迁移学习是利用在海量数据中训练过的预训练模型来训练我们自己的数据集。通过这样做,我们可以在短时间内获得更好的数据集性能。)
2. Dataset
The experiment dataset is from the Internet, which include two classes: ants, bees. Some samples selected from the dataset are shown in Figure 1.(实验数据来自互联网,包括三个类别:蚂蚁、蜜蜂。从数据集中选择的一些示例如图1所示。)


(a) ants (b) bees
The dataset is manually divided into two parts, which respectively are trainset and valset. Among them, trainset includes 300 images and every class has 100 images. Correspondingly, valset includes 150 images and every class has 50 images. Model can be trained in the trainset and evaluated in the valset. In my experiment, the ratio of trainset to valset is 2:1.(该数据集被手动分为两部分,分别是训练集和验证集。其中,训练集包含300幅图像,每个类包含100幅图像。相应地,valset包含150个图像,每个类有50个图像。模型可以在训练集中进行训练并在valset中进行评估。在我的实验中,训练集和验证集的比率是2:1。)
3. Model and Result
In this experiment, resnet18 is used to train my own dataset by loading the pretrained model in the ImageNet. The whole training process adopt 25 epoches which spends about 1 minute in the 2080ti GPU. The model is evaluated in the valset after every epoch.(在这个实验中,resnet18通过在ImageNet中加载预训练模型来训练我自己的数据集。整个训练过程采用25个epoches,在2080ti gpu上花费约1分钟。该模型在每个epoch后的valset中进行评价。)
Some experiment settings: initial learning rate:0.01; loss function: CrossEntropyLoss; gradient decent algorithm: SGD.
The loss and accuracy of trainset and valset tendency are shown below. From it, we can safely get a conclusion that the loss has converged and accuracy has become high and stable. The best valset accuracy can achieve: 96% which proves that the transfer learning is very effective.(训练集和验证集的损失和准确性如下所示。 从中我们可以安全地得出结论,损失已经收敛,并且精度已经变得很高且稳定。 最佳的valset精度可以达到:96%,这证明了转移学习非常有效。)

Figure 2 visualize loss and accuracy tendency
Some classified result selected from valset are visualized below. The red word labled in these pictures are predicted result by the trained model. There is no doubt that model has a good performance.(从valset中选择的一些分类结果如下所示。 这些图片中标记的红色单词是经过训练的模型的预测结果。 毫无疑问,该模型具有良好的性能。)


Figure 3 predicted result samples
4. Conclusion
By using transfer learning, the resnet18 which loads the pretrained model in the ImageNet can get a good performance on my own dataset in a shorter time.(通过使用转移学习,将预训练的模型加载到ImageNet中的resnet18可以在较短的时间内在我自己的数据集上获得良好的性能)
源码和数据集参考:https://pytorch.org/tutorials/beginner/transfer_learning_tutorial.html
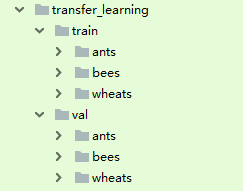
数据集格式
import torch
import torch.nn as nn
import torch.optim as optim
from torch.optim import lr_scheduler
import numpy as np
import torchvision
from torchvision import datasets, models, transforms
import matplotlib.pyplot as plt
import time
import os
import copy
import cv2
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
#prepare train and val transforms
train_transforms = transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
val_transforms = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
#prepare dataloader
data_dir = './data/transfer_learning'
train_image_datasets = datasets.ImageFolder(os.path.join(data_dir, 'train'), train_transforms)
train_dataloaders = torch.utils.data.DataLoader(
train_image_datasets,
batch_size=16,
shuffle=True,
num_workers=4)
val_image_datasets = datasets.ImageFolder(os.path.join(data_dir, 'val'), val_transforms)
val_dataloaders = torch.utils.data.DataLoader(
datasets.ImageFolder(os.path.join(data_dir, 'val'), val_transforms),
batch_size=8,
shuffle=True,
num_workers=4)
#prepare model resnet18
class_names = train_image_datasets.classes
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = models.resnet18(pretrained=True) #load pretrained model
num_cls = model.fc.in_features
model.fc = nn.Linear(num_cls, 3) #three categorys
model = model.to(device)
#loss function and optimizer
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
exp_lr_scheduler = lr_scheduler.MultiStepLR(optimizer, milestones=[20, 24], gamma=0.1)
#prepare plot train val loss and acc
train_loss = []
train_acc = []
val_acc = []
def train_model(model, criterion, optimizer, scheduler, num_epochs=25):
since = time.time()
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.0
for epoch in range(num_epochs):
model.train()
running_loss = 0.0
running_corrects = 0
for inputs, labels in train_dataloaders:
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
scheduler.step()
epoch_loss = running_loss / len(train_image_datasets)
epoch_acc = running_corrects.double() / len(train_image_datasets)
print('Epoch [{}]/[{}]'.format(epoch, num_epochs - 1))
print('-' * 10)
print('Train Loss: {:.4f} Acc: {:.4f}'.format(epoch_loss, epoch_acc))
train_loss.append(epoch_loss)
train_acc.append(epoch_acc.item())
#evaluation the model
model.eval()
with torch.set_grad_enabled(False):
running_corrects = 0
for inputs, labels in val_dataloaders:
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
running_corrects += torch.sum(preds == labels.data)
epoch_acc = running_corrects.double() / len(val_image_datasets)
val_acc.append(epoch_acc.item())
if epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
print()
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(
time_elapsed // 60, time_elapsed % 60))
print('Best val Acc: {:4f}'.format(best_acc))
# load best model weights
model.load_state_dict(best_model_wts)
return model
model = train_model(model, criterion, optimizer, exp_lr_scheduler,num_epochs=25)
def visualize_model(model):
model.eval()
cnt = 0
data_root = './data/result'
if not os.path.exists(data_root):
os.makedirs(data_root)
with torch.no_grad():
for i, (inputs, labels) in enumerate(val_dataloaders):
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
for j in range(inputs.size()[0]):
inp = inputs.cpu().data[j].numpy().transpose((1, 2, 0))
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
inp = std * inp + mean
inp = np.clip(inp, 0, 1)
inp = inp*255.0
cv2.putText(inp, class_names[preds[j]], (30, 30),
cv2.FONT_HERSHEY_COMPLEX, 1.5, (0, 0, 255), thickness=2)
cv2.imwrite(os.path.join(data_root, str(cnt)+'.jpg'), inp)
cnt += 1
visualize_model(model)
#plot loss and acc
plt.figure()
plt.subplot(1,2,1)
plt.plot(np.arange(len(train_loss)), np.array(train_loss))
plt.xlabel('epoches')
plt.ylabel('loss')
plt.subplot(1,2,2)
plt.plot(np.arange(len(train_acc)), np.array(train_acc), label='train acc')
plt.plot(np.arange(len(val_acc)), np.array(val_acc), label='val acc')
plt.xlabel('epoches')
plt.ylabel('acc')
plt.legend()
plt.savefig('./data/loss_acc.jpg')