LLVM读书笔记
1.LLVM简介
传统编译器:前端 -> 优化器 -> 后端。

LLVM:多种前端 -> 统一中间代码 -> 面向多种机器的多种后端

· 不同的前端后端使用统一的中间代码LLVM Intermediate Representation (LLVM IR)
· 如果需要支持一种新的编程语言,那么只需要实现一个新的前端
· 如果需要支持一种新的硬件设备,那么只需要实现一个新的后端
· 优化阶段是一个通用的阶段,它针对的是统一的LLVM IR,不论是支持新的编程语言,还是支持新的硬件设备,都不需要对优化阶段做修改
广义LLVM:整个LLVM架构;
狭义LLVM:LLVM后端(代码优化、目标代码生成等)
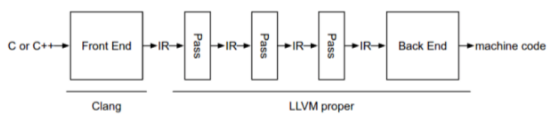
在本报告中参考的LLVM代码中,LLVM框架的前端使用的是Clang,所以框架可以概括为下图。
2.词法分析器
功能:将用户输入的字符串切分成为“语元(token)”,然后再做进一步处理。
LLVM实现:编译器第一个步骤是词法分析(Lexical analysis)。词法分析器读入组成源程序的字节流,并将他们组成有意义的词素(Lexeme)序列。对于每个词素,词法分析器产生词单元(token)作为输出,并生成相关符号表。词法库包含了几个紧密相连的类,他们涉及到词法和C源码预处理。
1)保留字定义:有我们熟悉的”if”,”include”等。
PPKEYWORD(if)
PPKEYWORD(ifdef)
PPKEYWORD(ifndef)
PPKEYWORD(elif)
PPKEYWORD(else)
PPKEYWORD(endif)
PPKEYWORD(defined)
// C99 6.10.2 - Source File Inclusion.
PPKEYWORD(include)
PPKEYWORD(__include_macros)
// C99 6.10.3 - Macro Replacement.
PPKEYWORD(define)
PPKEYWORD(undef)
// C99 6.10.4 - Line Control.
PPKEYWORD(line)
// C99 6.10.5 - Error Directive.
PPKEYWORD(error)
// C99 6.10.6 - Pragma Directive.
PPKEYWORD(pragma)
// GNU Extensions.
PPKEYWORD(import)
PPKEYWORD(include_next)
PPKEYWORD(warning)
PPKEYWORD(ident)
PPKEYWORD(sccs)
PPKEYWORD(assert)
PPKEYWORD(unassert)
// Clang extensions
PPKEYWORD(__public_macro)
PPKEYWORD(__private_macro)
...
2)Token类的部分定义
class Token {
/// The location of the token. This is actually a SourceLocation.
unsigned Loc;
// Conceptually these next two fields could be in a union. However, this
// causes gcc 4.2 to pessimize LexTokenInternal, a very performance critical
// routine. Keeping as separate members with casts until a more beautiful fix
// presents itself.
/// UintData - This holds either the length of the token text, when
/// a normal token, or the end of the SourceRange when an annotation
/// token.
unsigned UintData;
/// PtrData - This is a union of four different pointer types, which depends
/// on what type of token this is:
/// Identifiers, keywords, etc:
/// This is an IdentifierInfo*, which contains the uniqued identifier
/// spelling.
/// Literals: isLiteral() returns true.
/// This is a pointer to the start of the token in a text buffer, which
/// may be dirty (have trigraphs / escaped newlines).
/// Annotations (resolved type names, C++ scopes, etc): isAnnotation().
/// This is a pointer to sema-specific data for the annotation token.
/// Eof:
// This is a pointer to a Decl.
/// Other:
/// This is null.
void *PtrData;
/// Kind - The actual flavor of token this is.
tok::TokenKind Kind;
/// Flags - Bits we track about this token, members of the TokenFlags enum.
unsigned short Flags;
3)Lexer
///Lexer-This provides a simple interface that turns a text buffer into a
///stream of tokens.This provides no support for file reading or buffering,
///or buffering/seeking of tokens,only forward lexing is supported.It relies
///on the specified Preprocessor object to handle preprocessor directives,etc.
class Lexer:public PreprocessorLexer{
friend class Preprocessor;
void anchor()override;
//===--------------------------------------------------------------------===//
//Constant configuration values for this lexer.
//Start of the buffer.
const char*BufferStart;
//End of the buffer.
const char*BufferEnd;
//Location for start of file.
SourceLocation FileLoc;
//LangOpts enabled by this language(cache).
LangOptions LangOpts;
//True if lexer for_Pragma handling.
bool Is_PragmaLexer;
4)关键代码实现
Lex:
Lexer *Lexer::Create_PragmaLexer(SourceLocation SpellingLoc,
SourceLocation ExpansionLocStart,
SourceLocation ExpansionLocEnd,
unsigned TokLen, Preprocessor &PP) {
SourceManager &SM = PP.getSourceManager();
// Create the lexer as if we were going to lex the file normally.
FileID SpellingFID = SM.getFileID(SpellingLoc);
const llvm::MemoryBuffer *InputFile = SM.getBuffer(SpellingFID);
Lexer *L = new Lexer(SpellingFID, InputFile, PP);
// Now that the lexer is created, change the start/end locations so that we
// just lex the subsection of the file that we want. This is lexing from a
// scratch buffer.
const char *StrData = SM.getCharacterData(SpellingLoc);
L->BufferPtr = StrData;
L->BufferEnd = StrData+TokLen;
assert(L->BufferEnd[0] == 0 && "Buffer is not nul terminated!");
// Set the SourceLocation with the remapping information. This ensures that
// GetMappedTokenLoc will remap the tokens as they are lexed.
L->FileLoc = SM.createExpansionLoc(SM.getLocForStartOfFile(SpellingFID),
ExpansionLocStart,
ExpansionLocEnd, TokLen);
// Ensure that the lexer thinks it is inside a directive, so that end \n will
// return an EOD token.
L->ParsingPreprocessorDirective = true;
// This lexer really is for _Pragma.
L->Is_PragmaLexer = true;
return L;
}
3.语法分析器和AST
1)ParseAST:clang的Parser是由clang::ParseAST执行的。语法分析器是使用递归下降(recursive-descent)的语法分析。
void clang::ParseAST(Preprocessor &PP, ASTConsumer *Consumer,
ASTContext &Ctx, bool PrintStats,
TranslationUnitKind TUKind,
CodeCompleteConsumer *CompletionConsumer,
bool SkipFunctionBodies) {
std::unique_ptr<Sema> S(
new Sema(PP, Ctx, *Consumer, TUKind, CompletionConsumer));
// Recover resources if we crash before exiting this method.
llvm::CrashRecoveryContextCleanupRegistrar<Sema> CleanupSema(S.get());
ParseAST(*S.get(), PrintStats, SkipFunctionBodies);
}
void clang::ParseAST(Sema &S, bool PrintStats, bool SkipFunctionBodies) {
// Collect global stats on Decls/Stmts (until we have a module streamer).
if (PrintStats) {
Decl::EnableStatistics();
Stmt::EnableStatistics();
}
// Also turn on collection of stats inside of the Sema object.
bool OldCollectStats = PrintStats;
std::swap(OldCollectStats, S.CollectStats);
// Initialize the template instantiation observer chain.
// FIXME: See note on "finalize" below.
initialize(S.TemplateInstCallbacks, S);
ASTConsumer *Consumer = &S.getASTConsumer();
std::unique_ptr<Parser> ParseOP(
new Parser(S.getPreprocessor(), S, SkipFunctionBodies));
Parser &P = *ParseOP.get();
llvm::CrashRecoveryContextCleanupRegistrar<const void, ResetStackCleanup>
CleanupPrettyStack(llvm::SavePrettyStackState());
PrettyStackTraceParserEntry CrashInfo(P);
// Recover resources if we crash before exiting this method.
llvm::CrashRecoveryContextCleanupRegistrar<Parser>
CleanupParser(ParseOP.get());
S.getPreprocessor().EnterMainSourceFile();
ExternalASTSource *External = S.getASTContext().getExternalSource();
if (External)
External->StartTranslationUnit(Consumer);
// If a PCH through header is specified that does not have an include in
// the source, or a PCH is being created with #pragma hdrstop with nothing
// after the pragma, there won't be any tokens or a Lexer.
bool HaveLexer = S.getPreprocessor().getCurrentLexer();
if (HaveLexer) {
llvm::TimeTraceScope TimeScope("Frontend");
P.Initialize();
Parser::DeclGroupPtrTy ADecl;
for (bool AtEOF = P.ParseFirstTopLevelDecl(ADecl); !AtEOF;
AtEOF = P.ParseTopLevelDecl(ADecl)) {
// If we got a null return and something *was* parsed, ignore it. This
// is due to a top-level semicolon, an action override, or a parse error
// skipping something.
if (ADecl && !Consumer->HandleTopLevelDecl(ADecl.get()))
return;
}
}
// Process any TopLevelDecls generated by #pragma weak.
for (Decl *D : S.WeakTopLevelDecls())
Consumer->HandleTopLevelDecl(DeclGroupRef(D));
Consumer->HandleTranslationUnit(S.getASTContext());
// Finalize the template instantiation observer chain.
// FIXME: This (and init.) should be done in the Sema class, but because
// Sema does not have a reliable "Finalize" function (it has a
// destructor, but it is not guaranteed to be called ("-disable-free")).
// So, do the initialization above and do the finalization here:
finalize(S.TemplateInstCallbacks, S);
std::swap(OldCollectStats, S.CollectStats);
if (PrintStats) {
llvm::errs() << "\nSTATISTICS:\n";
if (HaveLexer) P.getActions().PrintStats();
S.getASTContext().PrintStats();
Decl::PrintStats();
Stmt::PrintStats();
Consumer->PrintStats();
}
}
2)AST:提供了多种类,用于:表示C AST、C类型、内建函数和一些用于分析和操作AST的功能(visitors、漂亮的打印输出等)。其类的源码定义在 lib/AST 中。其中重要的AST节点有:
Type:顾名思义是用来保存“种类”的,例如结构体定义时 typedef 语句定义的结构体种类信息。Type类及其派生类是AST中非常重要的一部分。通过ASTContext访问Type(clang/ast/ASTContext.h),在需要时他隐式的唯一的创建他们。Type有一些不明显的特征:1)他们不捕获类似const或volatile类型修饰符(See QualType);2)他们隐含的捕获typedef信息。一旦创建,type将是不可变的。
Decl:表示Declaration声明。上面的type类型是用来保存种类信息,而这里的Decl则是用来保存变量、函数、结构等内容的。
class TranslationUnitDecl : public Decl, public DeclContext {
ASTContext &Ctx;
/// The (most recently entered) anonymous namespace for this
/// translation unit, if one has been created.
NamespaceDecl *AnonymousNamespace = nullptr;
explicit TranslationUnitDecl(ASTContext &ctx);
virtual void anchor();
public:
ASTContext &getASTContext() const { return Ctx; }
NamespaceDecl *getAnonymousNamespace() const { return AnonymousNamespace; }
void setAnonymousNamespace(NamespaceDecl *D) { AnonymousNamespace = D; }
static TranslationUnitDecl *Create(ASTContext &C);
// Implement isa/cast/dyncast/etc.
static bool classof(const Decl *D) { return classofKind(D->getKind()); }
static bool classofKind(Kind K) { return K == TranslationUnit; }
static DeclContext *castToDeclContext(const TranslationUnitDecl *D) {
return static_cast<DeclContext *>(const_cast<TranslationUnitDecl*>(D));
}
static TranslationUnitDecl *castFromDeclContext(const DeclContext *DC) {
return static_cast<TranslationUnitDecl *>(const_cast<DeclContext*>(DC));
}
};
DeclContext:保存上下文。程序中每个声明都存在于某一个声明上下文中,类似翻译单元、名字空间、类或函数。Clang中的声明上下文是由类DeclContext类进行描述:各种AST节点声明上下文均派生于此(TranslationUnitDecl、NamespaceDecl、RecordDecl、FunctionDecl等)。
4.语义分析
语义分析通过符号表确保代码没有违反语言定义
5.IR
根据LLVM的结构可知,在进行语义分析之后,clang应生成中间代码,这一过程被称为LLVM IR。其基本语法包括以下几点:
注释以分号 ; 开头
全局标识符以@开头,局部标识符以%开头
alloca,在当前函数栈帧中分配内存
i32,32bit,4个字节的意思
align,内存对齐
store,写入数据
load,读取数据
LLVM IR有3种表示形式(本质是等价的)
text:便于阅读的文本格式,类似于汇编语言,拓展名.ll, $ clang -S -emit-llvm main.m
memory:内存格式
bitcode:二进制格式,拓展名.bc, $ clang -c -emit-llvm main.m
我们以text形式编译并查看一个简单程序的中间结果。
; Function Attrs: noinline nounwind optnone ssp uwtable
define void @test(i32, i32) #2 {
%3 = alloca i32, align 4
%4 = alloca i32, align 4
%5 = alloca i32, align 4
store i32 %0, i32* %3, align 4
store i32 %1, i32* %4, align 4
%6 = load i32, i32* %3, align 4
%7 = load i32, i32* %4, align 4
%8 = add nsw i32 %6, %7
%9 = sub nsw i32 %8, 3
store i32 %9, i32* %5, align 4
ret void
}
6.后端部分
编译器前端产生IR指令(如我们之前使用的clang),优化器通过在IR指令上完成优化,并将这些与平台无关的IR指令转化成具体设备相关的指令,例如x86汇编或arm。故LLVM的后端部分包括代码优化与生成目标程序(代码)两个部分。根据LLVM后端官方文档,将LLVM分为以下几个部分分别学习。
1)指令选择(InstructionSelection)
指令选择将内存中的设备无关的IR指令转换成设备相关的DAG(Directed Acycle Graph,SelectionDAG)节点。在内部,这一阶段转换三地址结构的IR到DAG。每个BasicBlock对应一个DAG,即所有的BasicBlock对应不同的DAG。使用DAG算法是对允许代码生成器使用树模式匹配(tree-based pattern-matching)的指令选择很重要,并不仅仅是基于树。在这个阶段完成后,所有的LLVM IR的DAG节点全部转换成目标节点,也就是,代表及其指令的节点而不是LLVM IR指令。
2)指令调度(InstructionScheduling)
为了尽可能的使用指令级的并行操作,使用指令调度来对指令的执行顺序进行性能优化。指令调度主流技术使用的是一种贪婪启发式算法,称之为表调度。值得注意的是,一般来说在后端中不止出现一次指令调度,这是因为在进行寄存器分配(Registerallocation)的前后,代码使用的寄存器个数通常不同,所以需要多次进行指令调度以保证性能。
3)寄存器分配(Registerallocation)
寄存器分配将输入的任意数目的寄存器重新分配为符合硬件要求的有限个数寄存器。多数编译器寄存器分配的主要算法有图着色算法。LLVM根据同的选项有4种不同的寄存器分配算法:
Pbqp
Greedy:贪心算法。
Basic
Fast
4)代码发行(Codeemission)
将指令转化成MCInst,并最终生成汇编代码或二进制代码。
获取target machine的代码:(llvm/lib/Target/TargetMachineC.cpp)
LLVMTargetRef LLVMGetFirstTarget() {
if (TargetRegistry::targets().begin() == TargetRegistry::targets().end()) {
return nullptr;
}
const Target *target = &*TargetRegistry::targets().begin();
return wrap(target);
}
LLVMTargetRef LLVMGetNextTarget(LLVMTargetRef T) {
return wrap(unwrap(T)->getNext());
}
LLVMTargetRef LLVMGetTargetFromName(const char *Name) {
StringRef NameRef = Name;
auto I = find_if(TargetRegistry::targets(),
[&](const Target &T) { return T.getName() == NameRef; });
return I != TargetRegistry::targets().end() ? wrap(&*I) : nullptr;
}