代理(Proxy)
代理(Proxy)是一种特殊的网络服务,你可以把它当成一个中转站。例如当我们访问某个网站特别慢或者无法访问的时候,那么就可以使用合适的代理来访问。首先代理服务器访问网站,然后代理服务器再将访问到的数据传给我们。在爬虫中可以使用IP代理来隐藏自己的真实IP地址,以达到反反爬或者其他的目的。
获取代理IP
网络上有许多网站可以获得免费的代理IP,例如西刺代理,快代理等网站,但这些网站中的代理IP质量良莠不齐,但可以通过筛选来获得可以使用的IP。下面我们就通过爬取西刺代理来创建一个自己的IP代理池。
网站分析
和以前一样,先分析网站。我们翻到最下面,点击第二页后观察到URL由https://www.xicidaili.com/wt变为https://www.xicidaili.com/wt/2,点击第三页后发现URL变为https://www.xicidaili.com/wt/3。这样我们便发现了网站的规律,仅需改变URL最后一位数字即可改变当前的页数。
使用Chrome浏览器自带的检查功能,观察网页所需的请求头(详见第一篇博客),如下:
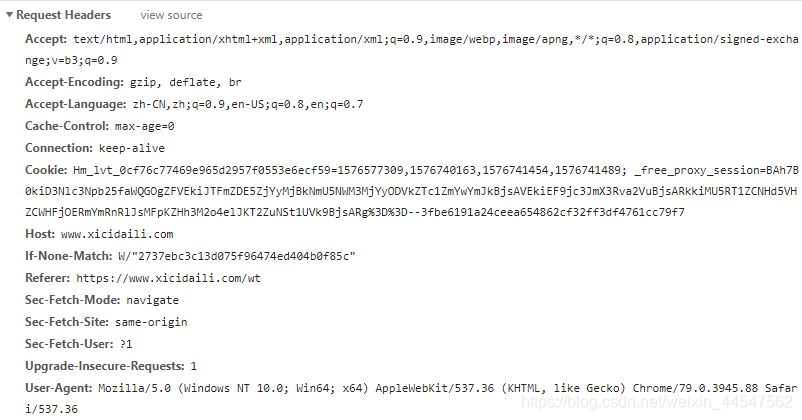
提取主要信息可以设置爬虫请求头为:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.79 Safari/537.36',
'Host':'www.xicidaili.com'
}
获取页面
定义获取页面函数
import requests
from bs4 import BeautifulSoup
def get_page(url,params=None,headers=None,proxies=None,timeout=None):
response = requests.get(url, headers=headers, params=params, proxies=proxies, timeout=timeout)
page = BeautifulSoup(response.text, 'lxml')
print("解析网址:",response.url)
print("响应状态码:", response.status_code)
return page
然后即可使用此函数爬取页面
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.79 Safari/537.36',
'Host':'www.xicidaili.com'
}
url = 'https://www.xicidaili.com/wt'
page = get_page(url,headers=headers)
页面分析
因为使用普通的页面分析较难获取代理IP地址,因此我们使用上一篇教学博客正则表达式来获取代理IP。
先观察页面源码的字符串形式,使用
page.text
得到输出如下:

我们需要得到IP地址和端口,即
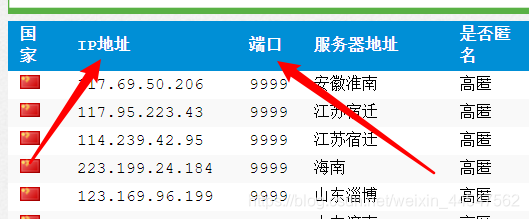
观察源码可知我们需要获得的代理IP都是形如191.163.23.34\n9999的形式,使用正则表达式则可以概括为r'\d+\.\d+\.\d+\.\d+\n\d+'。使用如下代码获取代理IP。
import re
ip_list = re.findall(r'\d+\.\d+\.\d+\.\d+\n\d+',page.text)
print(ip_list)
得到结果如下:
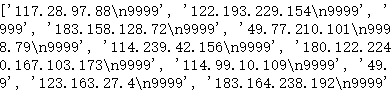
显然不是我们想要的结果,但是我们只需将\n替换为:即可,如下:
IP = []
for ip in re.findall(r'\d+\.\d+\.\d+\.\d+\n\d+',page.text):
IP.append(re.sub(r'\n',':',ip))
print(IP)
得到结果如下:

此时即得到我们想要的代理IP。
观察到第二页的IP代理验证时间已经是十几小时之前了,后面的验证时间更久,由于IP代理非常容易失效,故只爬取第一页的代理IP即可。
所有代码如下:
IP = []
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.79 Safari/537.36',
'Host':'www.xicidaili.com'
}
for i in range(1):
url = "https://www.xicidaili.com/wt/"+str(i+1)+"/"
page = get_page(url,headers=headers)
for ip in re.findall(r'\d+\.\d+\.\d+\.\d+\n\d+',page.text):
IP.append(re.sub(r'\n',':',ip))
如果实在是想爬取其他页面,只需将循环改变即可。
现在我们就获得了一个有许多代理IP的代理池。
筛选代理IP
上面我们获取到的代理IP中有绝大部分是无效的,有的甚至只能使用几分钟,下面就将能使用的代理IP保存到ProxyPool中,将不能使用的代理IP删除。
方法很简单,随机选取代理IP,然后尝试使用IP代理访问http://httpbin.org/ip网站,观察是否能成功。如果访问成功便获取现在使用的IP,观察IP代理是否成功使用。
import random
ProxyPool = []
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.79 Safari/537.36',
'host': 'httpbin.org'
}
for i in range(len(IP)):
print('代理池的大小为{}'.format(len(IP)))
ranint = random.randint(0,len(IP)-1)
ip = IP[ranint]
proxies = { "http" : "http://" + ip}
try:
page = get_page('http://httpbin.org/ip', headers=headers, proxies=proxies, timeout=2.5)
print("随机选择的ip为:",ip)
now_ip = re.search(r'\d+\.\d+\.\d+\.\d+' ,page.text)
print('成功使用代理IP:', now_ip.group())
ProxyPool.append(IP[ranint])
except:
pass
IP.pop(ranint)
print('筛选后的代理池大小为{}'.format(len(ProxyPool)))
得到输出如下:

通过筛选我们最终从100个代理IP中获得了11个可用的代理IP,且筛选后的代理池中的代理IP也在逐渐失效中。
爬虫系列
Python爬虫小白教程(一)—— 静态网页抓取
Python爬虫小白教程(二)—— 爬取豆瓣评分TOP250电影
Python爬虫小白教程(三)——使用正则表达式分析网页
Python爬虫小白教程(四)—— 反反爬之IP代理池
Python爬虫小白教程(五)—— 多线程爬虫