前言
在使用爬虫的时候,很多网站都有一定的反爬措施,甚至在爬取大量的数据或者频繁地访问该网站多次时还可能面临ip被禁,所以这个时候我们通常就可以找一些代理ip来继续爬虫测试。下面就开始来简单地介绍一下爬取免费的代理ip来搭建自己的代理ip池:
本次爬取免费ip代理的网址:http://www.ip3366.net/free/
提示:以下是本篇文章正文内容,下面案例可供参考
一、User-Agent
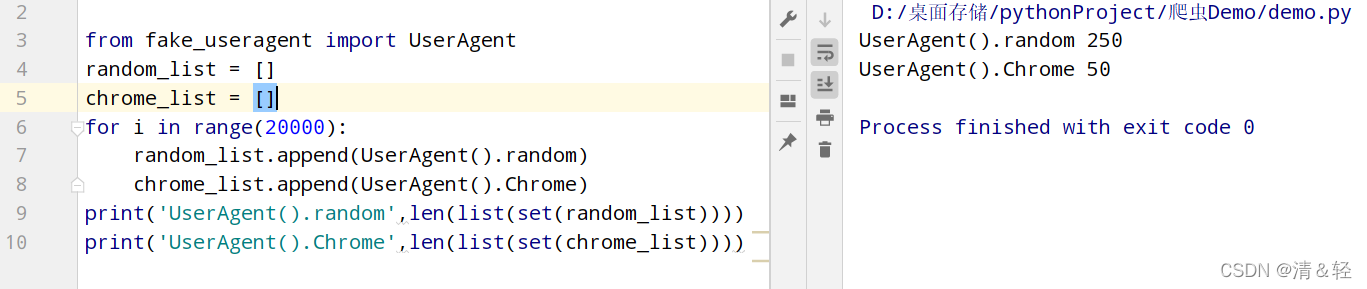
在发送请求的时候,通常都会做一个简单的反爬。这时可以用fake_useragent模块来设置一个请求头,用来进行伪装成浏览器,下面两种方法都可以。
from fake_useragent import UserAgent
headers = {
# 'User-Agent': UserAgent().random #常见浏览器的请求头伪装(如:火狐,谷歌)
'User-Agent': UserAgent().Chrome #谷歌浏览器
}
二、发送请求
response = requests.get(url='http://www.ip3366.net/free/', headers=request_header())
# text = response.text.encode('ISO-8859-1')
# print(text.decode('gbk'))
三、解析数据
我们只需要解析出ip、port即可。
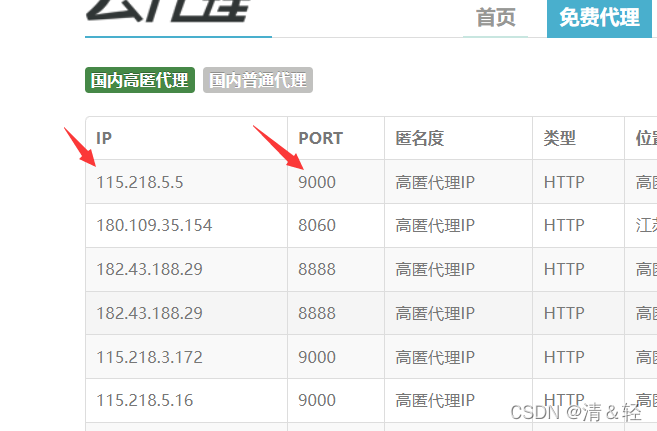
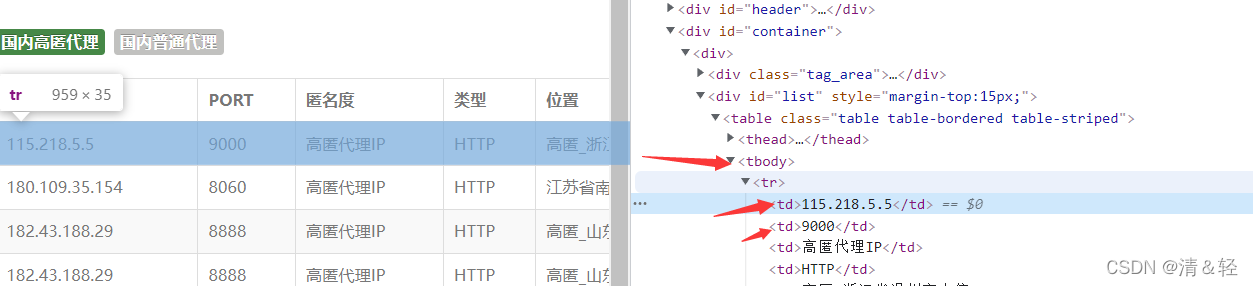
使用xpath解析(个人很喜欢用)(当然还有很多的解析方法,如:正则,css选择器,BeautifulSoup等等)。
#使用xpath解析,提取出数据ip,端口
html = etree.HTML(response.text)
tr_list = html.xpath('/html/body/div[2]/div/div[2]/table/tbody/tr')
for td in tr_list:
ip_ = td.xpath('./td[1]/text()')[0] #ip
port_ = td.xpath('./td[2]/text()')[0] #端口
proxy = ip_ + ':' + port_ #115.218.5.5:9000
四、构建ip代理池,检测ip是否可用
#构建代理ip
proxy = ip + ':' + port
proxies = {
"http": "http://" + proxy,
"https": "http://" + proxy,
# "http": proxy,
# "https": proxy,
}
try:
response = requests.get(url='https://www.baidu.com/',headers=request_header(),proxies=proxies,timeout=1) #设置timeout,使响应等待1s
response.close()
if response.status_code == 200:
print(proxy, '\033[31m可用\033[0m')
else:
print(proxy, '不可用')
except:
print(proxy,'请求异常')
五、完整代码
import requests #导入模块
from lxml import etree
from fake_useragent import UserAgent
#简单的反爬,设置一个请求头来伪装成浏览器
def request_header():
headers = {
# 'User-Agent': UserAgent().random #常见浏览器的请求头伪装(如:火狐,谷歌)
'User-Agent': UserAgent().Chrome #谷歌浏览器
}
return headers
'''
创建两个列表用来存放代理ip
'''
all_ip_list = [] #用于存放从网站上抓取到的ip
usable_ip_list = [] #用于存放通过检测ip后是否可以使用
#发送请求,获得响应
def send_request():
#爬取7页,可自行修改
for i in range(1,8):
print(f'正在抓取第{
i}页……')
response = requests.get(url=f'http://www.ip3366.net/free/?page={
i}', headers=request_header())
text = response.text.encode('ISO-8859-1')
# print(text.decode('gbk'))
#使用xpath解析,提取出数据ip,端口
html = etree.HTML(text)
tr_list = html.xpath('/html/body/div[2]/div/div[2]/table/tbody/tr')
for td in tr_list:
ip_ = td.xpath('./td[1]/text()')[0] #ip
port_ = td.xpath('./td[2]/text()')[0] #端口
proxy = ip_ + ':' + port_ #115.218.5.5:9000
all_ip_list.append(proxy)
test_ip(proxy) #开始检测获取到的ip是否可以使用
print('抓取完成!')
print(f'抓取到的ip个数为:{
len(all_ip_list)}')
print(f'可以使用的ip个数为:{
len(usable_ip_list)}')
print('分别有:\n', usable_ip_list)
#检测ip是否可以使用
def test_ip(proxy):
#构建代理ip
proxies = {
"http": "http://" + proxy,
"https": "http://" + proxy,
# "http": proxy,
# "https": proxy,
}
try:
response = requests.get(url='https://www.baidu.com/',headers=request_header(),proxies=proxies,timeout=1) #设置timeout,使响应等待1s
response.close()
if response.status_code == 200:
usable_ip_list.append(proxy)
print(proxy, '\033[31m可用\033[0m')
else:
print(proxy, '不可用')
except:
print(proxy,'请求异常')
if __name__ == '__main__':
send_request()
总结
以上就是要讲的内容,很简单,但希望可以帮助到大家。