1.排序二叉树
排序二叉树(BST)也称二叉查找树,排序二叉树或者是一棵空树,或者是一棵具有下列特性的非空二叉树:
(1)若左子树非空,则左子树上所有结点关键字值小于根节点的关键字值.
(2)若右子树非空,则右子树上所有结点关键字值大于根节点的关键字值.
(3)左、右子树本身分别是一棵排序二叉树。
根据排序二叉树的定义,左子树结点值<根节点值<右子树结点值,对排序二叉树进行中序遍历,可以得到一个递增的序列。
(1)查找操作代码如下:
//search函数查找二叉查找树中数据域为x的结点
void search(node* root,int x){
if(root == NULL){
printf("search faiiled\n");
return;
}
if(x == root->data ){
printf("%d", root->data ); //查找成功,访问之
}
else if(x < root->data ){
search(root->lchild, x);
}
else{
search(root->rchild, x);
}
}
2.插入操作代码如下:
//insert函数将在二叉树中插入一个数据域为x的新节点
void insert(node* &root, int x){
if(root == NULL){ //空树,说明查找失败,即插入位置
root = newNode(x);
return root;
}
if(x == root->data ) return; //查找成功,说明结点存在,直接返回
else if(x < root->data ){
insert(root->lchild );
}
else insert(root->rchild );
}
3.排序二叉树的建立代码如下:
node* Create(int data[], int n){
node* root = NULL; //新建空根节点root
for(int i=0; i<n; i++){
insert(root, data[i]); //将data[0]~data[i-1]插入二叉树中
}
return root; //返回根节点
}
4.排序二叉树的删除
把以排序二叉树中比结点权值小的最大结点称为该结点的前驱,而把比结点权值大的最小结点称为后继。显然,结点的前驱就是该结点左子树中的最右结点(也就是从左子树根节点开始不断沿着rchild往下直到rchild为NULL时的结点),而结点的后继则是该结点右子树的最左结点(也就是从右子树根节点开始不断沿着lchild往下直到lchild为NULL时的结点)。下面两个函数用来寻找以root为根的树中最大或最小权值的点,用以辅助寻找结点的前驱和后继。
//寻找以root为根节点的树中的最大权值点
node* findMax(node* root){
while(root->rchild != NULL){
root = root->rchild ;//不断往右,直到没有右孩子
}
return root;
}
//寻找以root为根节点的树中的最小权值点
node* findMin(node* root){
while(root->lchild != NULL){
root = root->lchild ;//不断往左,直到没有左孩子
}
return root;
}
假设决定用结点N的前驱P来替换N,于是就把问题转换为在N的左子树中删除结点P,就可以递归下去,直到递归到一个叶子结点,就可以直接把它删除了。
因此删除操作的基本思路如下:
(1)如果当前结点root为空,说明不存在权值为给定权值x的结点,直接返回。
(2)如果当前结点root的权值恰好为给定的权值x,说明找到了想要删除的结点,此时进入删除处理。
a)如果当前结点root不存在左右孩子,说明是叶子结点,直接删除。
b)如果当前结点root存在孩子结点,那么在左子树中寻找前驱pre,然后让pre的数据覆盖root,接着在左子树中删除结点pre。
c)如果当前结点root存在有孩子,那么在右子树中寻找结点后继next,然后让next的数据覆盖root,接着在右子树中删除结点next。
(3)如果当前结点root的权值大于给定的权值x,则在左子树中递归删除权值为x的结点。
(4)如果当前结点root的权值小于给定的权值x,则在右子树中递归删除权值为x的结点。删除操作代码如下:
void deleteNode(node* &root, int x){
if(root == NULL) return; //不存在权值为x的结点
if(x == root->data ){ //找到欲删除结点
if(root->lchild == NULL && root->rchild == NULL){
root = NULL; //把root地址设为NULL,父节点就引用不到它了
}
else if(root->lchild != NULL ){ //左子树不为空
node *pre = findMax(root->lchild); //找root的前驱
root->data = pre->data ; //用前驱覆盖root
deleteNode(root->lchild, pre->data ); //在左子树中删除结点pre
}
else{
node *next = findMin(root->rchild); //找root的后继
root->data = pre->data ; //用后继覆盖root
deleteNode(root->rchild, next->data ); //在右子树中删除结点next
}
}
else if(root->data > x){
deleteNode(root->lchild, x);//在左子树中删除x
}
else{
deleteNode(root->rchild, x); //在 右子树中删除x
}
}
2.平衡二叉树
平衡二叉树(AVL)仍然是一棵排序二叉树,在其基础上增加了"平衡",即对AVL树的任意结点来说,其左子树与右子树的高度之差的绝对值不超过1,其中左子树与右子树的高度之差称为平衡因子。
只要能随时保证每个结点平衡因子的绝对值不超过1,AVL的高度就始终能保持O(logn)级别,由于需要对每个结点都得到平衡因子,因此需要在树的结构中加入一个变量height,用来记录以当前结点为根节点的子树的高度。
节点描述代码如下:
struct node{
int v, height; //v为数据域,height为高度
node* lchild, rchild; //左指针域,右指针域
};
新建一个结点:
node* newNode{
node* Node = new node; //新建一个node型变量的地址空间
Node->v = v;
Node->lchild = Node->rchild =NULL;
Node->height = 1;
return node;
}
通过getHeight函数得到结点root所在子树的当前高度:
int getHeight(node* root){
if(root == NULL) return 0;
else return root->height;
}
计算结点root所在子树的平衡因子:
int getBanlanceFactor(node* root){
return getHeight(root->lchild) - getHeight(root->rchild );
}
结点root所在子树的height等于其左子树的height与右子树的height的较大值加1,可以用过updateHeight函数来更新结点root的height。
void updateHeight(node* root{
root->height = max(getHeight(root->lchild ),getHeight(root->rchild) )+1;
}
平衡二叉树的查找、AVL树的建立与排序二叉树操作是一样的,就是插入操作不一样,因为需要插入的时候考虑平衡因子。
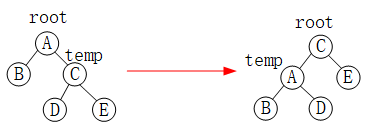
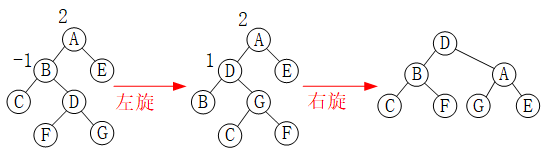
如下图所示,A的平衡因子为-1,当在A的右孩子的右子树E上插入结点,A的平衡因子就为-2,就需要进行平衡旋转。因为平衡二叉树是一种特殊的排序二叉树,A、C、D的权值满足:A<D<C;
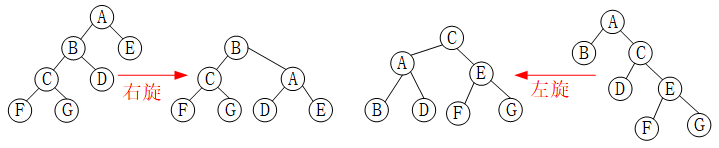
假设指针root指向结点A,temp指针指向结点C,左旋的过程如下:
(1)让C的左子树D成为A的右子树;
(2)让A成为C的左子树;
(3)将根节点设为结点C。
左旋代码:
//左旋
void L(node* &root){
node* temp = root->rchild ; //root指向结点A,temp指向结点B
root->rchild = temp->lchild;
temp-lchild = root;
updateHeight(root);
updateHeight(temp);
root = temp;
}
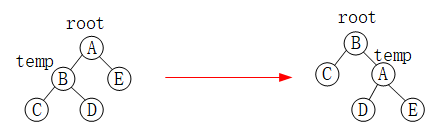
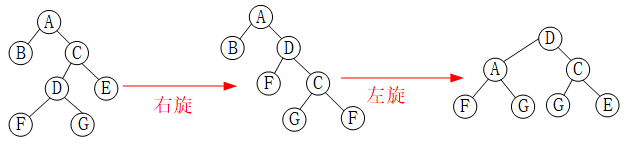
如下图所示,A的平衡因子为1,当在A的左孩子的左子树C上插入结点,A的平衡因子就为2,就需要进行平衡旋转。因为平衡二叉树是一种特殊的排序二叉树,A、B、D的权值满足:B<D<A;
假设指针root指向结点A,temp指针指向结点B,右旋的过程如下:
(1)让B的右子树D成为A的左子树;
(2)让A成为B的右子树;
(3)将根节点设为结点B。
右旋代码:
//右旋
void R(node* &root){
node* temp = root->lchild; //root指向结点B,temp指向结点A
root->lchild = temp->rchild;
temp->rchild = root;
updateHeight(root);
updateHeight(temp);
root = temp;
}
由于需要从插入的结点开始从下往上判断结点是否失衡,因此需要在每个insert函数之后更新当前子树的高度,并在这之后根据树型是LL型、LR型、RR型、RL型来进行平衡操作。
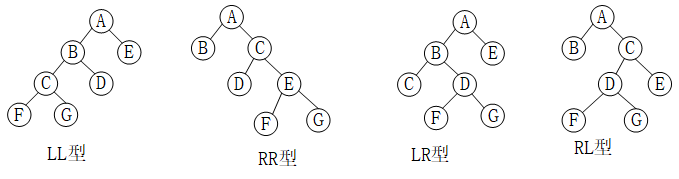
考虑LL型,将C为根节点的子树看作一个整体,然后以结点A作为root进行右旋,便可以达到平衡,如下图所示。
考虑RR型,将以E为根节点的子树看作一个整体,然后以结点A为root进行左旋,便可以达到平衡,如下图所示。
考虑LR型,先忽略结点A,以结点B为root进行左旋,就可以把情况转化为LL型,然后按上面LL型的做法进行一次右旋即可平衡。
考虑RL型,可以先忽略结点A,以D结点为root进行右旋,把情况转化为RR型,然后按上面RR型的做法进行一次左旋即可达到平衡。
//插入权值为v的结点
void insert(node* &root, int v){
if(root == NULL){
root = newNode(v);
return ;
}
if(v < root->v){//v比根节点的权值小
insert(root->lchild); //往左字树插入
updateHeight(root); //更新树高
if(getBalanceFactor(root) ==2){
if(getBalanceFactor(root) == 1){ //LL型
R(root);
}
else if(getBalanceFactor(root) == -1){
L(root->lchild);
R(root);
}
}
}
else{ //v比根节点的权值大
insert(root->rchild, v); //往右子树插入
updateHeight(root); //更新树高
if(getBalanceFactor(root) ==-2) {
if(getBalanceFactor(root->rchild) ==-1){
L(root);
}
else if{
R(root->rchild);
L(root);
}
}
}
}
3.线索二叉树
线索二叉树基本概念
遍历二叉树就是以一定的规则将二叉树中的结点排列成一个线性序列,从而得到二叉树结点的各种遍历序列,其实质就是对一个非线性结构进行线性化操作,使在这个访问序列中每一个结点(除第一个结点和最后一个结点)都有一个直接前驱和直接后继。
传统的链式存储仅能体现一种父子关系,不能直接得到结点在遍历中的前驱和后继,利用二叉链表大量空链域存放指向其直接前驱和后继的指针,则可以更方便地运用某些二叉树操作算法,引入线索二叉树是为了加快查找结点前驱和后继的速度。
线索二叉树的存储结构描述如下:
typedef struct ThreadNode{
int data; //数据元素
struct ThreadNode *lchild, *rchild; //左、右孩子指针
int ltag, rtag; //左右线索标志
}ThreadNode, *ThreadTree;
以这种结点结构构成的二叉链表作为二叉树的存储结构,叫做线索链表,其中指向前驱和后继的指针,叫做线索。加上线索的二叉树叫做线索二叉树,对二叉树以某种次序遍历使其变为线索二叉树的过程叫做线索化。
线索二叉树的构造
对二叉树的线索化,就是遍历一次二叉树,在遍历的过程中,检查当前结点前驱左、右指针域是否为空,若为空,将它们改为指向前驱结点或后继结点的线索。
以中序线索二叉树的建立为例,指针pre指向中序遍历时上一个刚刚访问过的结点,用它来表示各结点访问的前后关系。
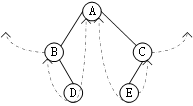
//中序遍历对二叉树线索化的递归算法
void Inthread(ThreadTree &p, ThreadTree &pre){
if(p != NULL){
InThread(p->lchild, pre); //递归,线索化左子树
if(p->lchihld == NULL){ //左子树为空,建立前驱线索
p = p->lchild;
p->ltag = 1;
}
if(pre != NULL && p->rchild == NULL){
pre->rchild = p; //建立前驱结点的后继线索
pre->rtag = 1;
}
pre = p; // 标记当前结点成为刚刚访问过的结点
InThread(p->rchild, pre); //递归线索化右子树
}
}
//通过中序遍历建立中序线索二叉树
void CreateInThread(ThredTree T){
ThreadTree pre= NULL;
if(T != NULL){ //非空二叉树,线索化
InThread(T, pre); //线索化二叉树
pre->rtag = 1;
pre->rchild = NULL; //处理遍历的最后一个结点
}
}
有时为了方便,仿照线性表的存储结构,在二叉树的线索链表上添加一个头结点,并令其lchild域的指针指向二叉树的根节点,其rchild域的指针指向中序遍历时访问的最后一个结点;反之,令二叉树中序序列中的第一个结点的lchild域的指针和最后一个结点rchild域的指针均指向头结点。这好比为二叉树建立一个双向线索链表,既可以从第一个结点起顺后继进行遍历,也可从最后一个结点起顺前驱进行遍历。
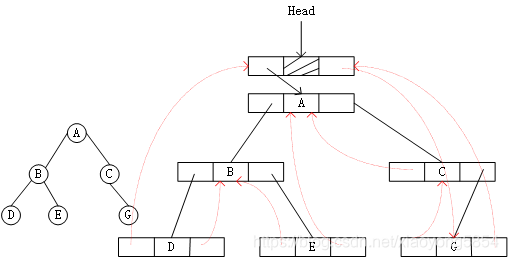
3.线索二叉树的遍历
中序线索化二叉树主要是为访问运算服务的,这种遍历不再需要借助栈,因为它的结点中隐含了线索二叉树的前驱和后继信息。利用线索二叉树,可以实现二叉树遍历的非递归算法,不含头结点的线索二叉树的遍历算法如下:
//求中序线索二叉树中中序序列下的第一个结点
ThreadNode *Fisrtnode(ThreadNode *p){
while(p->ltag == 0) p = p->lchild; //最左下结点
return p;
}
//求中序线索二叉树中结点p在中序序列下的后继结点
ThreadNode *Nextnode(ThreadNode *p){
if(p->rtag ==0) return Firstnode(p->rchild);
else return p->rchild; //rtag == 1直接返回后继线索
}
//不包含头结点的中序线索二叉树的中序遍历算法
void Inorder(ThreadNode *T){
for(ThreadNode *p = Firstnode(T); p != NULL; p = NextNode(p)){
visit(p);
}
}