python 第三天学习了list(列表)、dictionary(字典)、file(读写文件)的基础语法,具体如下:
一、List(列表)
python 中,list是一个有序的对象集合
1.创建列表
只要把逗号分隔的不同的数据相使用方括号([ ])括起来即可 下标(角标、索引)从0开始,最后一个元素的下标可以写-1

2.添加新的元素
list.append() ,在list末尾增加一个元素,如:

list.insert(n,'胖妞'),在指定的位置添加数据,如果指定的位置不存在,则添加在列表的最后。

list1.extend(list2)合并两个list list2中仍有元素
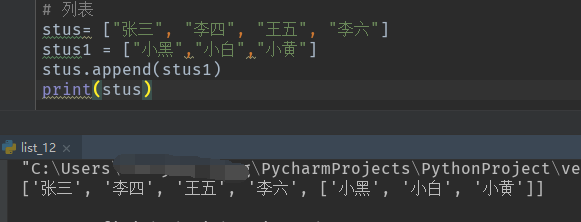
3.查看列表中的值
print(list) 遍历列表
等价于 for i in list:
print( i )
list[n] 使用下标索引来访问列表中的值,同样你也可以使用方括号的形式截取字符
list.count( **) 查看某个元素在这个列表中的个数,如果该元素不存在,那么返回0
list.index (**) 找到这个元素的角标,如果有多个,返回第一个,如果找一个不存在的元素会报错
4.删除list 中的元素
list.pop() 删除最后一个元素
list.pop( n) 指定下标,删除指定的元素,如果删除一个不存在的元素会报错
list.remove(**) 删除list里面的一个元素,有多个相同的元素,删除第一个
list.poop() 有返回值
list.remove() 无返回值
del list[n] 删除指定下标对应的元素
del list 删除整个列表,list 删除后无法访问
list.clear() 删除列表中的所有数据
5.排序和反转
list.reverse() 将列表反转
list.sort() 排序,默认升序
list.sort( reverse = true) 降序排列
注: list 中有字符串、数字时,不能排序,排序针对同类型
6.列表操作的函数
a. len (list) 列表元素个数
b. max(list) 返回列表元素最大值
c.min (list) 返回列表元素最小值
d.list(seq) 将元组转换为列表
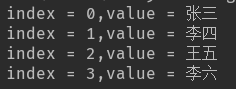
e. enumerate 用法(打印元素对应的下标)
同时取下标,元素

结果如下:
7.循环和切片
a.循环
for i in list:
print(i)
b.切片(list 取值的一种方法)
name[n:m] 切片是不包含后面那个元素的值(顾头不顾尾)
name[:m] 如果切片前面一个值缺省的话,从开头开始取
name[n:] 如果切片后面的值缺省的话,取到末尾
name[:] 如果全部缺省,取全部
name[n:m:s] s:步长 隔多少个元素取一次 ( 步长是正数,从左往右取;步长是负数,从右往左取)
(注:切片同样适用于字符串,字符串也有下标)
8. 复制list
list.coopy()
二.字典
Python 字典是另一种可变容器模型,且可存储任意类型对象,如字符串、数字、元组等其他容器模型。优点:取值方便,速度快
1.创建字典
字典由键(key)和对应值( value) 成对组成。字典也被称作关联数组或哈希表。

注:
每个键与值 用冒号(:),每对用逗号,每对用逗号分割,整体放在花括号中({ })
健必须独一无二,但值则不必。
值可以取任何数据类型,但 键 必须是不可变的,如字符串,数组或元组
2.字典取值
dict[ 'key' ] 如果写了不存在的值会报错
dict.get('key') 如果写了不存在的值,返回None 是什么都没有
dict.get(‘key’,'not find') 如果找不到存在的值,返回‘not find’
dict1.keys() # 获取所有的key 值
dict1.values() # 获取所有的value 值
遍历字典,如下:
for k,v in dict.items()

3.修改字典
dict1["name"] = "胖妞22" # 如果使用这个方法,可以修改原来的值
4. 增加元素
dict1["name"] = "胖妞" dict1.setdefault("class", "双子座") # 如果使用setdefault,key已经存在了,就不会修改原来的值了
5. 删除
dict.pop("name") # 必须要传值,因为字典是无序的
del dict["age"]
dict.popitem() # 随机删除一个元素
dict.clear() # 清空
6. 更新
dict.update(dict2) 把dict2中的数据更新到dict1中
三、文件
文件操作对编程语言的重要性不用多说,数据持久保存。
1.文件操作:
os.mknod("test.txt") 创建空文件
fp = open("test.txt",w) 直接打开一个文件,如果文件不存在则创建文件
fp .read() 读文件
fp .write() 写文件
2. 文件打开模式:
w 以写方式打开,
a 以追加模式打开 (从 EOF 开始, 必要时创建新文件)
r+ 以读写模式打开
w+ 以读写模式打开 (参见 w )
a+ 以读写模式打开 (参见 a )
rb 以二进制读模式打开
wb 以二进制写模式打开 (参见 w )
ab 以二进制追加模式打开 (参见 a )
rb+ 以二进制读写模式打开 (参见 r+ )
wb+ 以二进制读写模式打开 (参见 w+ )
ab+ 以二进制读写模式打开 (参见 a+ )
3.读文件
fp.read([size]) #size为读取的长度,以byte为单位
fp.readline([size]) #读一行,如果定义了size,有可能返回的只是一行的一部分
fp.readlines([size]) #把文件每一行作为一个list的一个成员,并返回这个list。其实它的内部是通过循环调用readline()来实现的。如果提供size参数,size是表示读取内容的总长,也就是说可能只读到文件的一部分。
4.写文件
fp.write(str) #把str写到文件中,write()并不会在str后加上一个换行符
fp.writelines(seq) #把seq的内容全部写到文件中(多行一次性写入)。这个函数也只是忠实地写入,不会在每行后面加上任何东西。
5.关闭文件
fp.close() #关闭文件(这个很重要)。python会在一个文件不用后自动关闭文件,不过这一功能没有保证,最好还是养成自己关闭的习惯。 如果一个文件在关闭后还对其进行操作会产生ValueError
今天的学习笔记就写到这里,文件还有很多操作,还需要自己研究学习,后期学习了,会再来分享。 ……^ _ ^……