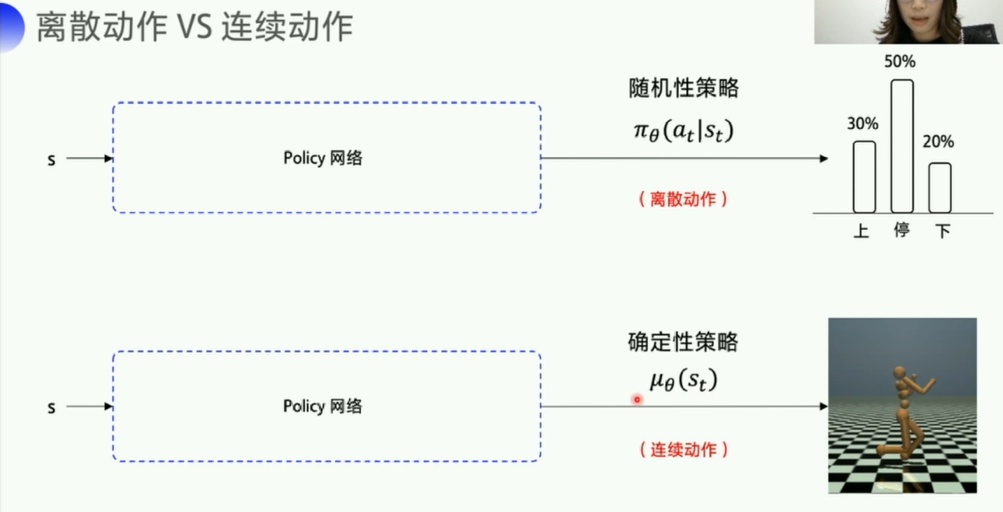
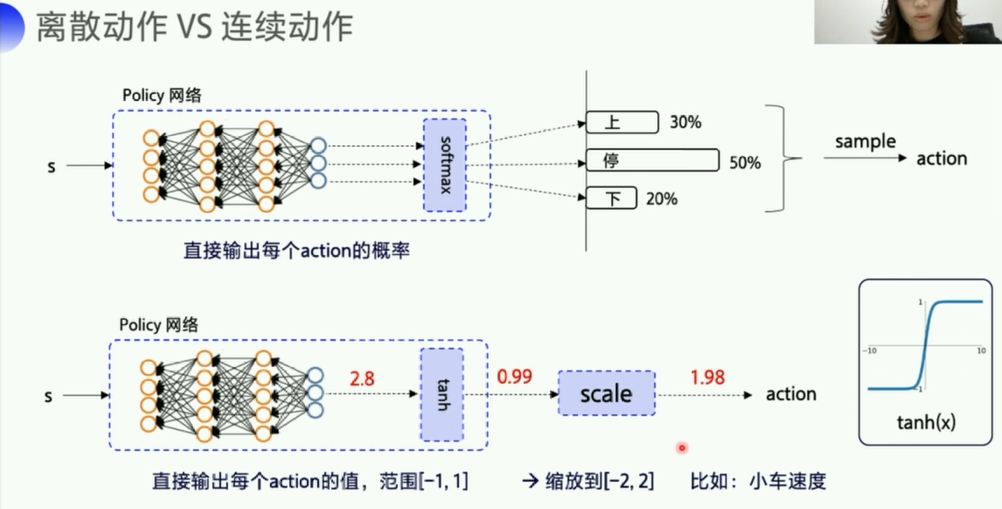
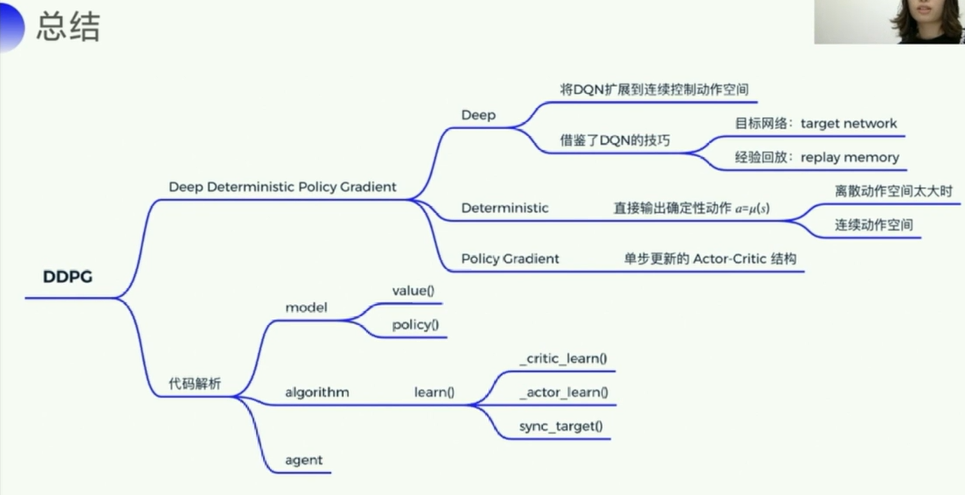
1. 离散动作 vs 连续动作
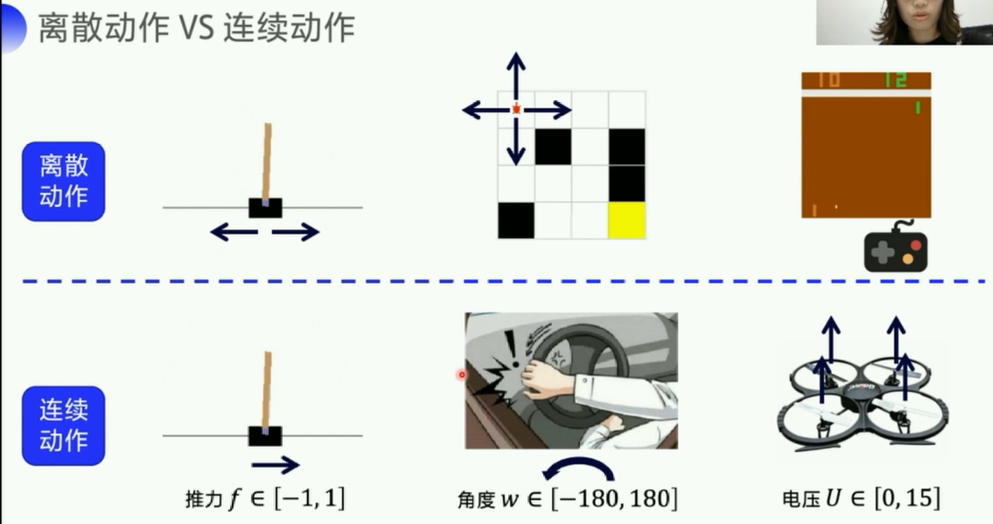
个人理解:
- 离散:可数(整数表示的)
- 连续:不可数(小数/浮点数表示的)
2. DDPG
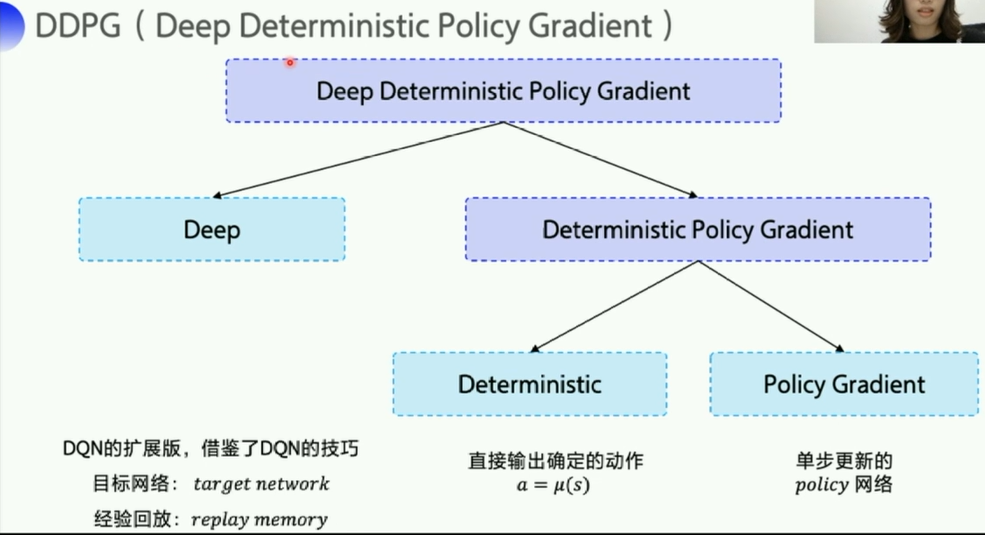
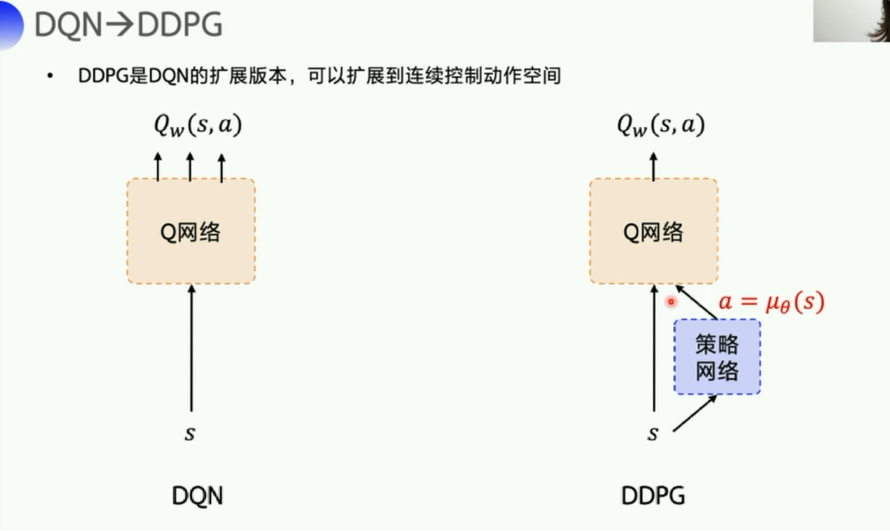
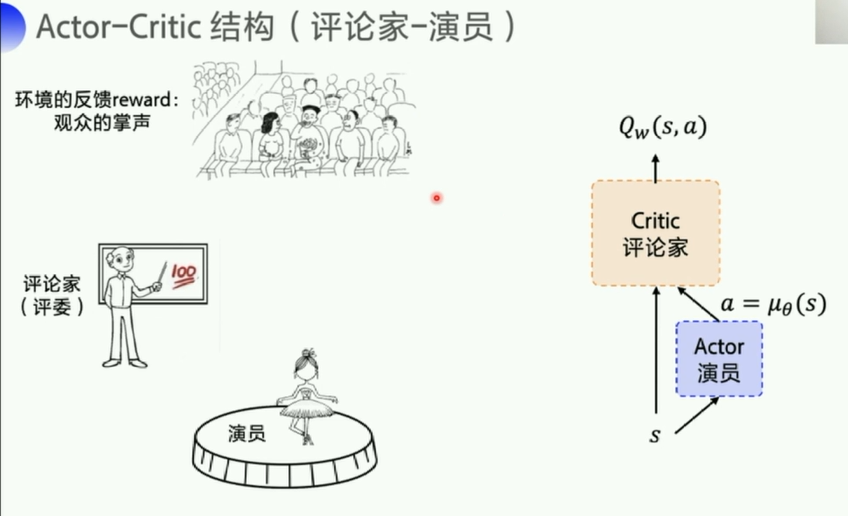
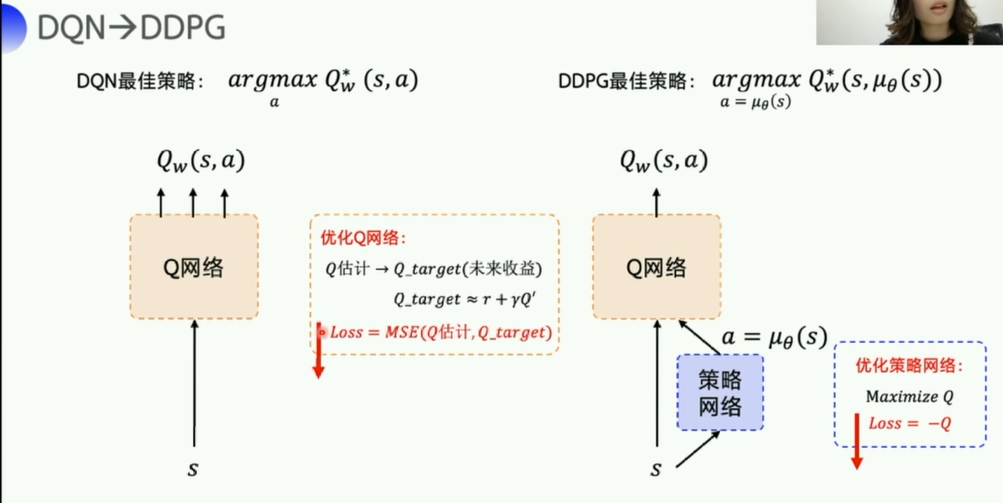
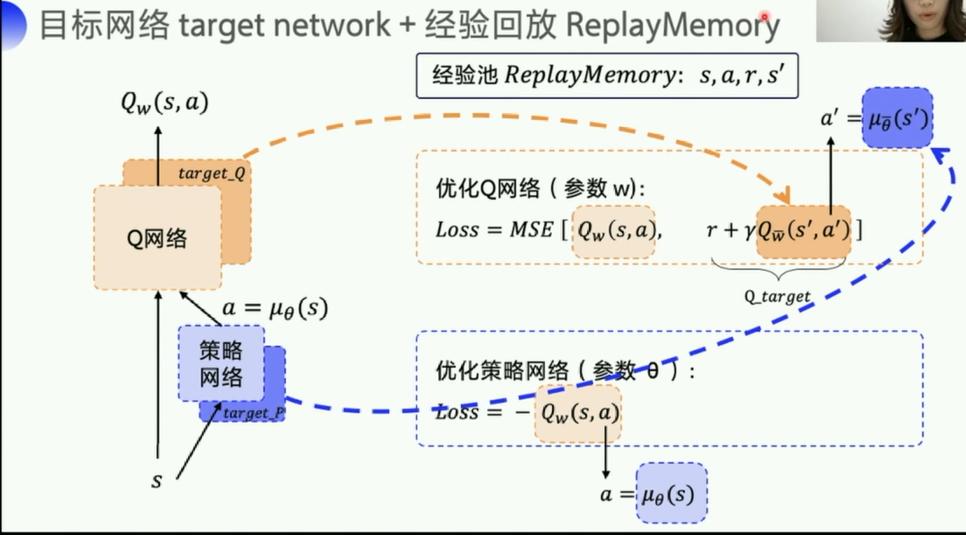
这里一共有四个网络,Q网络以及它的target_Q网络,策略网络以及它的target_P网络,两个target是为了稳定计算,每隔一段时间复制一下参数,投入到评估网络使用。
- target_Q是为了稳定计算
Q_target中的 Q w ˉ ( s ′ , a ′ ) Q_{\bar{w}}(s^{'},a^{'}) Qwˉ(s′,a′),而其中的 a ′ = μ θ ( s ′ ) a^{'}=\mu_{\theta}(s^{'}) a′=μθ(s′)则是由策略网络里的那个target_P网络来稳定计算的。 - Q w ˉ ( s ′ , a ′ ) Q_{\bar{w}}(s^{'},a^{'}) Qwˉ(s′,a′) 这里的w加了一个横线就是为了和前面的那个区分开。
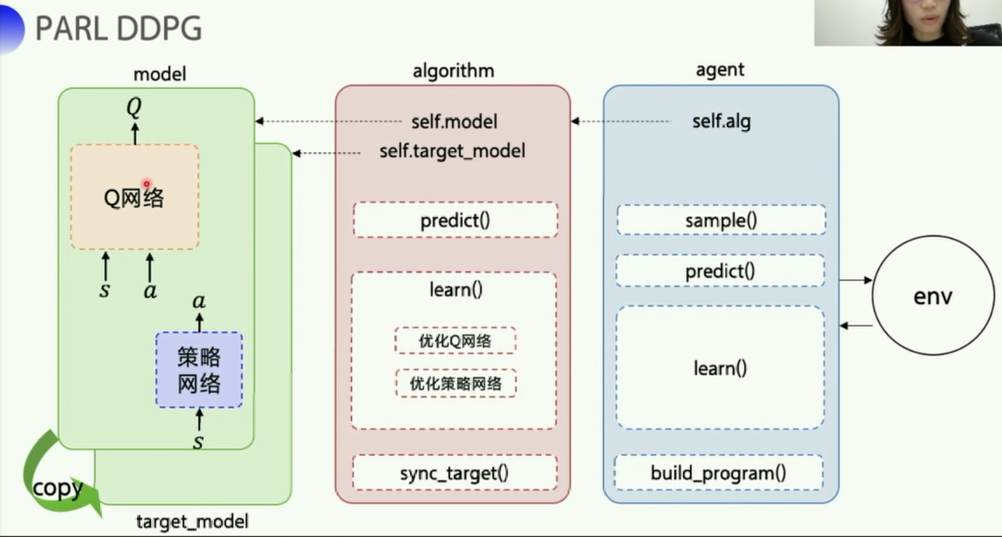
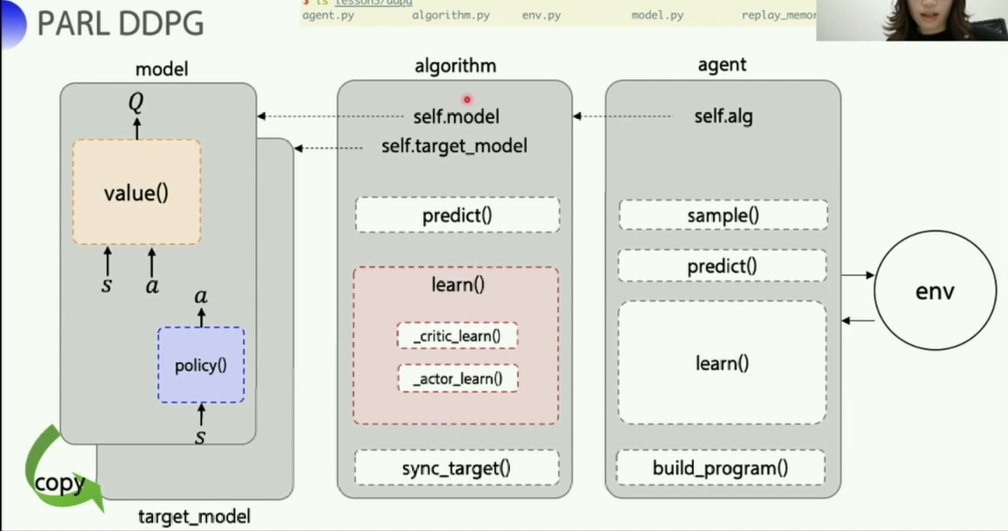
- 策略网络对应的是
model.py中的演员Actor类(ActorModel),有一个policy函数, - Q网络对应的是评论家类(
CriticModel类),有一个value函数
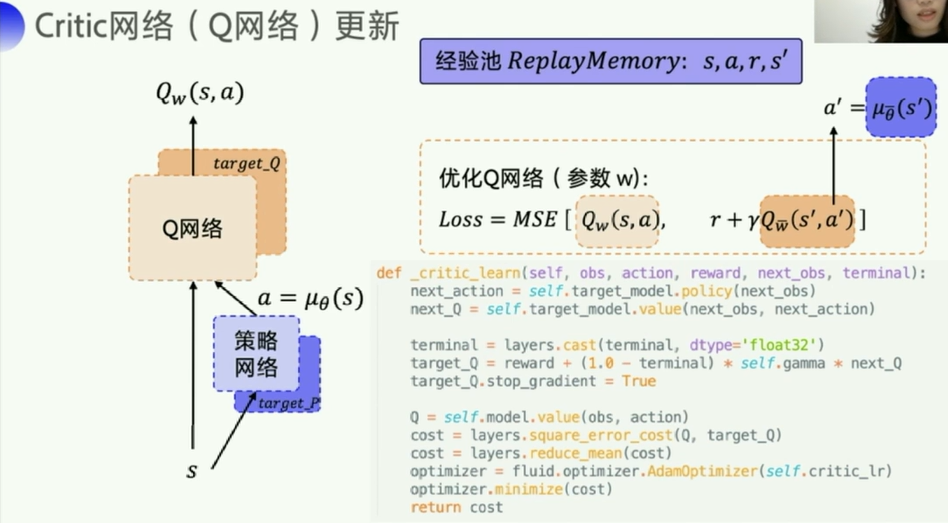


DQN里是硬更新,每次直接把 Q w Q_w Qw网络的所有参数全部给 Q w ˉ Q_{\bar{w}} Qwˉ, μ θ \mu_{\theta} μθ同理。
而DDPG采取的是一种更为平滑的方式,软更新,每次只更新一点点。如公式所示,用了一个 τ \tau τ,来控制每次 w w w或者 θ \theta θ更新的幅度。
也是为了让Q网络这个参数的更新更加稳定(属于工程/代码上的一种小trick吧)

3. 大作业


https://github.com/PaddlePaddle/RLSchool也是百度做的一个环境,目前暂时只有电梯环境和四轴飞行器这两个环境。


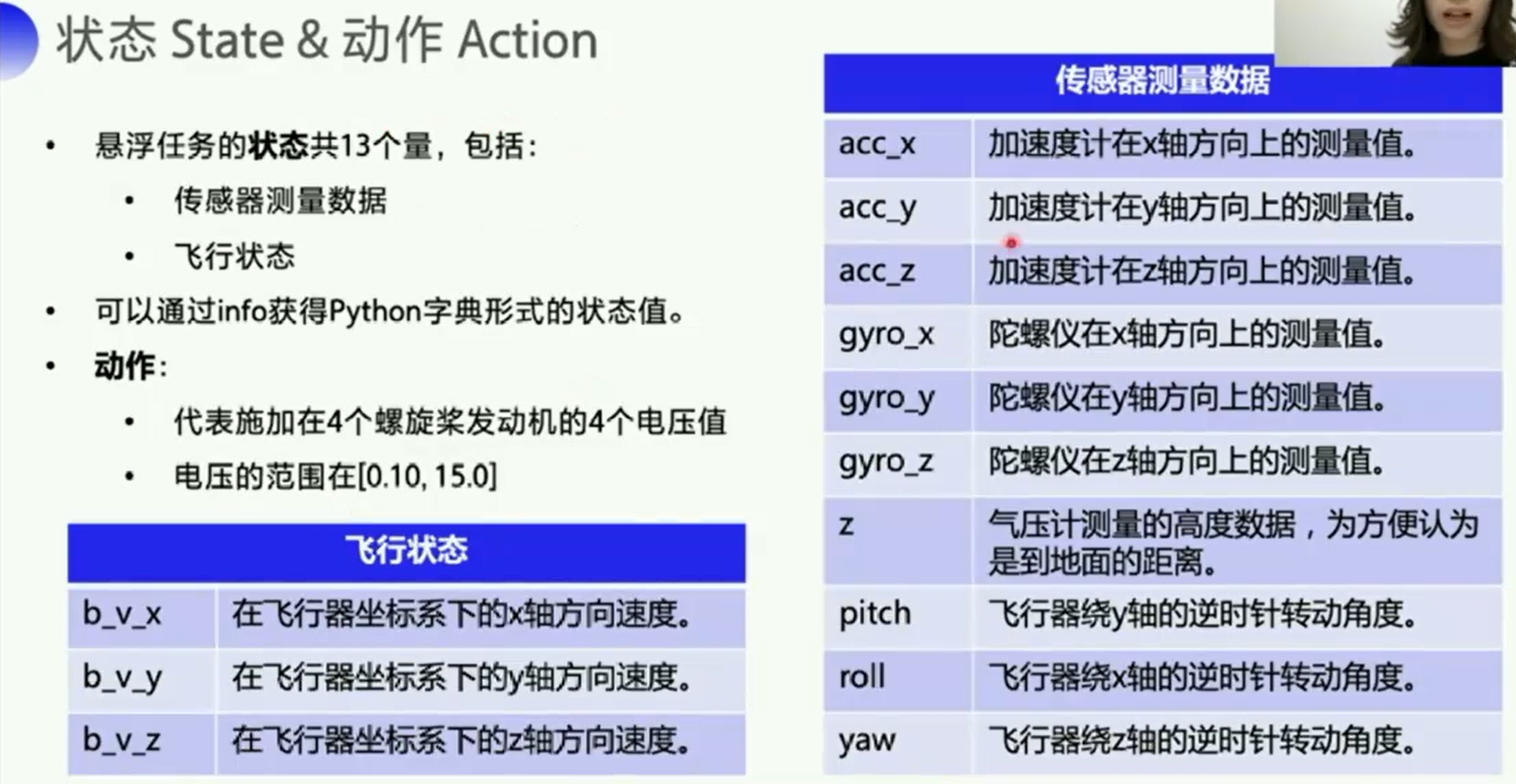
4. 创意赛


相关的代码实现:
在PaddleRL课程页面的讨论区:终极复现项目 提交区(讨论请移步灌水区~)
【参考环境】
- 1星环境:简单的弹跳和接球游戏:
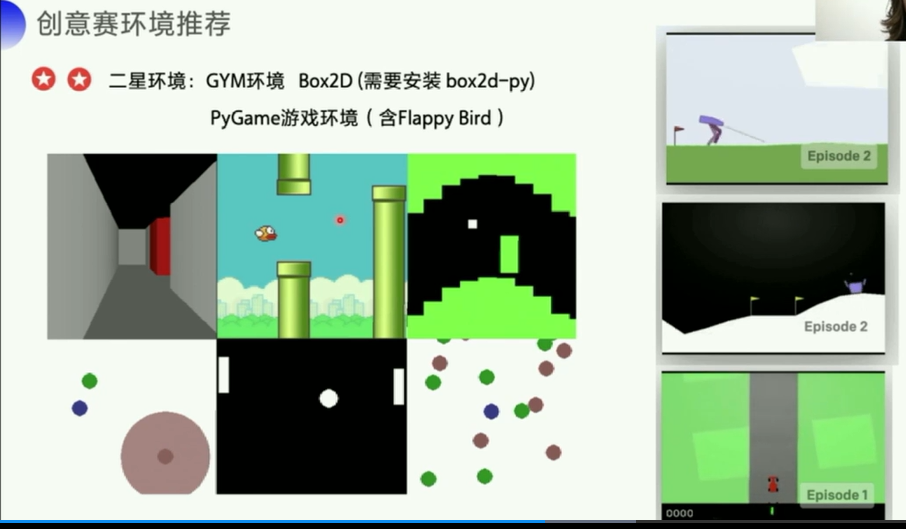
https://github.com/shivaverma/Orbit - 2星环境:GYM环境 Box2D (需要安装 box2d-py):
https://gym.openai.com/envs/#box2d - PyGame游戏环境(含Flappy Bird):
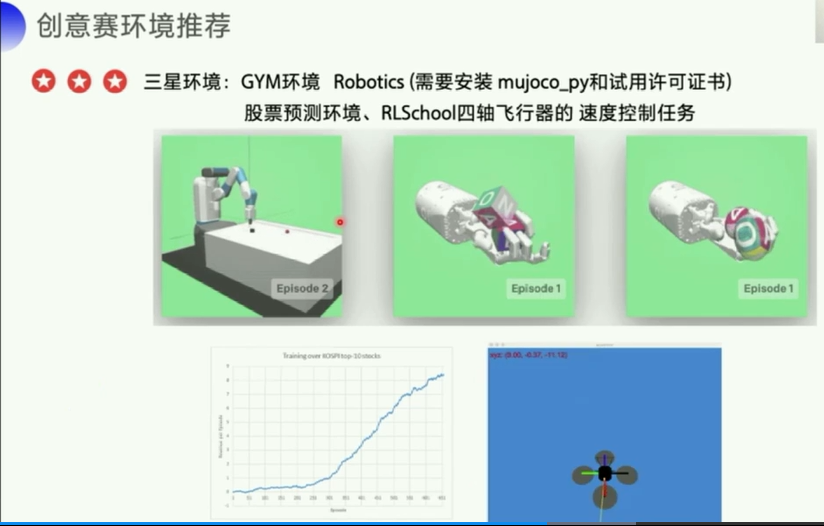
https://github.com/ntasfi/PyGame-Learning-Environment - 3星环境:GYM环境 Robotics (需要安装 mujoco_py和试用许可证书):https://gym.openai.com/envs/#robotics
- 股票预测环境:
https://github.com/kh-kim/stock_market_reinforcement_learning - RLSchool四轴飞行器的 速度控制任务 “velocity_control”:https://github.com/PaddlePaddle/RLSchool/tree/master/rlschool/quadrotor
- 4星环境:RLBench任务环境(使用机械臂完成某一项任务):https://github.com/stepjam/RLBench
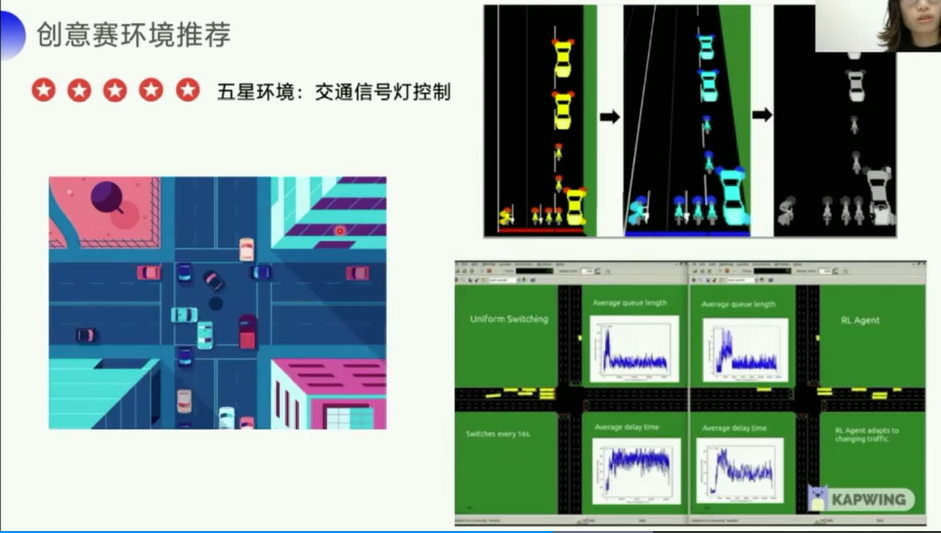
- 5星环境:交通信号灯控制:
https://github.com/Ujwal2910/Smart-Traffic-Signals-in-India-using-Deep-Reinforcement-Learning-and-Advanced-Computer-Vision