1 :Python历史与特点
2:Python的模块、包与库
3:Python输入输出
5:Python详解数据结构
6:Python迭代对象与迭代器
7:Python推导式与序列解包
Python中常见的数据结构有主要的三类容器。
- 序列(如列表、元组、字符串)
- 映射(如字典)
- 集合(set)
一丶序列
在Python中,把大量数据按次序排列而形成的集合体称为序列。Python中的字符串、列表和元组数据类型都是序列。在Python中,所有序列类型都可以进行某些特定的操作。这些操作包括:
- 索引(indexing)、分片(slicing)、加(adding)、乘(multiplying)以及检查某个元素是否属于序列的成员。
- 除此之外,Python还有计算序列长度、找出最大元素和最小元素的内建函数。
每种元素的增删改查其实都差不多 ,这里只介绍了共有与特点
1. 访问
索引值是从0开始,第二个则是 1,以此类推,从左向右逐渐变大;列表也可以从后往前,索引值从-1开始,从右向左逐渐变小。该访问方式适用于所有序列类型的对象:列表、元组、字符串。

2. 切片
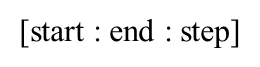
切片操作都是获取索引值位于[start, end)区间内的连续位置上的元素,当步长为1时,step参数可以省略。该切片方式适用于所有序列类型的对象:列表、元组、字符串。‘
下面以list为例
>>> n=list(range(10))
>>> n
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> n[0:10:2] #步长为2,索引值从0开始,每次增长2,但索引值必须小于10。
[0, 2, 4, 6, 8]
>>> n[::3]
[0, 3, 6, 9]
>>> n[7:2:-1] #步长为负数时,start不能小于end值。
[7, 6, 5, 4, 3]
>>> n[11::-2] #11超过范围,实际索引从最后一个元素开始。
[9, 7, 5, 3, 1]
>>> n[::-2] #这里步长为负数,表示在整个列表内,从后往前取值。
[9, 7, 5, 3, 1]
>>> n[::-1]
[9, 8, 7, 6, 5, 4, 3, 2, 1, 0]
>>> n[2:4]=[10,11] #分别更改索引号为2和3的位置上元素值。
>>> n
[0, 1, 10, 11, 4, 5, 6, 7, 8, 9]
>>> n[-5::2]=[-1,-2,-3] #分别更改索引号为-5、-3、-1三个位置上的元素值。
>>> n
[0, 1, 10, 11, 4, -1, 6, -2, 8, -3]
3. 加
序列相加生成新序列
以list为例
>>> vehicle1 = ['train', 'bus', 'car', 'ship']
>>> vehicle2 = ['subway', 'bicycle']
>>> vehicle1 + vehicle2
['train', 'bus', 'car', 'ship', 'subway', 'bicycle']
>>> vehicle1 # vehicle1没有改变
['train', 'bus', 'car', 'ship']
>>> vehicle2
['subway', 'bicycle']
>>> vehicle=vehicle1 + vehicle2 # 生成新列表赋值给变量vehicle
>>> vehicle
['train', 'bus', 'car', 'ship', 'subway', 'bicycle']
>>> vehicle+=['bike'] #复合赋值语句
>>> vehicle
['train', 'bus', 'car', 'ship', 'subway', 'bicycle', 'bike']
4. 乘
原来序列重复n次
以list为例
>>> vehicle1 = ['train', 'bus']
>>> vehicle1*2
['train', 'bus', 'train', 'bus']
>>> vehicle1 #原列表保持不变
['train', 'bus']
>>> vehicle=vehicle1*2 #赋值语句
>>> vehicle
['train', 'bus', 'train', 'bus']
>>> vehicle*=2 #复合赋值语句
>>> vehicle
['train', 'bus', 'train', 'bus', 'train', 'bus', 'train', 'bus']
5. 检查
使用in运算符测试某个元素是否在序列中,避免用index()查找索引位置时由于找不到指定元素而导致的错误。
以list为例
>>> vehicle = ['train', 'bus', 'car', 'subway', 'ship', 'bicycle', 'car']
>>> 'car' in vehicle
True
>>> 'plane' in vehicle
False
>>> vehicle = ['train', 'bus', 'car', 'subway', 'ship', 'bicycle', 'car']
>>> if 'car' in vehicle[3:6]:
print('[3, 6)范围内car位置索引为:',vehicle.index('car',3,6))
else:
print('在[3, 6)范围内没有car')
>>>'在[3, 6)范围内没有car'
二丶字典
字典可通过数据key查找关联数据value。Python中字典的元素没有特殊的顺序,因此不能像序列那样通过位置索引来查找成员数据。但是每一个值都有一个对应的键。字典的用法是通过键key来访问相应的值value,字典的键是不重复的。
初始化
d={}
d=dict()
dict(1='one',2='two')
keys=[1,2,3]
vals=[4,5,6]
d=zip(keys,vals)
formkeys([1,2,3])
val全为none
key可以是不可地修改类型的数据(数值,字符串,元组),列表不行,因为列表是可变的
value 可以对应任何类型
字典是无序的,显示次序由字典内部的存储结构决定
字典操作
len(a):返回键值对的数量
a[key]:键为key的value
a[2]=‘Two’ :存在就修改为Two,没有就添加这样的键值对
del(a[2]) :删除键为2
del a:删除字典
2 in a :查找是否key2是否在字典 a中
字典方法
-
a.keys():将字典a中的键以可迭代的dict_keys对象返回
-
a.values():将字典a中的值以可迭代的dict_values对象返回
-
a.items():所有的键和值以dict_items对象返回,每个键值对组成一个元组,
-
a.setdefault(2):存在2返回key2的value,没有就插入key:2,value:None
-
a.update(b):将b中的字典放入a,如果存在就更新,不存在就添加
-
a.clear():变成空字典
-
a.pop(6):删除key 6 ,pop至少一个参数
-
a.popitem():删除最后一个键值对
-
a.get(6):返回key 6的1 value,不存在返回none,注:a.get(6,‘my’) 没有找到就返回my
遍历字典
for i in a: // for i in a.keys() 一样的效果
print(i,a[i])
for i in a.values(): // for i in a.keys() 一样的效果
print(i,a[i])

转换
list(a) :将字典a的键变为list
list(a.keys()) :将字典a的键变为list
list(a.values()) :将字典a的值变为list
list(a.items()) :将字典a的键值对变为list
tuple(a) :将字典a的键变为tuple
tuple(a.keys()) :将字典a的键变为tuple
tuple(a.values()) :将字典a的值变为tuple
tuple(a.items()) :将字典a的键值对变为tuple
三丶集合
集合是一组用“{”和“}”括起来的无序不重复元素,元素之间用逗号分隔。元素可以是各种类型的不可变对象。Python提供了集合类型set,用于表示大量无序元素的集合。
1. 初始化
a=set()
a={} 这个是字典
2. 集合运算
并交
并集:创建一个新的集合,该集合包含两个集合中的所有元素。
交集:创建一个新的集合,该集合为两个集合中的公共部分。
>>> vehicle1={'train','bus','car','ship'}
>>> vehicle2={'subway','bicycle','bus'}
>>> vehicle1|vehicle2 #并集
{'car', 'ship', 'bicycle', 'train', 'bus', 'subway'}
>>> vehicle1&vehicle2 #交集
{'bus'}
差
差集:A-B表示集合A与B的差集,返回由出现在集合A中但不出现在集合B中的元素所构成的集合。
>>> vehicle1={'train','bus','car','ship'}
>>> vehicle2={'subway','bicycle','bus'}
>>> vehicle1-vehicle2
{'car', 'ship', 'train'}
>>> vehicle2-vehicle1
{'bicycle', 'subway'}
对称差
对称差:返回由两个集合中那些不重叠的元素所构成的集合。
>>> vehicle1={'train','bus','car','ship'}
>>> vehicle2={'subway','bicycle','bus'}
>>> vehicle1^vehicle2
{'ship', 'car', 'bicycle', 'train', 'subway'}
子集和超集
如果集合A的每个元素都是集合B中的元素,则集合A是集合B的子集。超集是仅当集合A是集合B的一个子集,集合B才是集合A的一个超集。
- A<=B,检测A是否是B的子集;
- A<B,检测A是否是B的真子集;
- A>=B,检测A是否是B的超集;
- A>B,检测A是否是B的真超集;
- A |= B将B的元素并入A中。
>>> vehicle1={'train','bus','car','ship'}
>>> vehicle2={'car','ship','bike'}
>>> vehicle2<vehicle1
False
>>> vehicle2>vehicle1
False
>>> vehicle1|=vehicle2
>>> vehicle1
{'car', 'ship', 'train', 'bus', 'bike'}
Python中同样以面向对象方式实现集合类型的运算。
- union()方法相当于并集运算。intersection()方法相当于交集运算。update()方法相当于集合元素合并运算,注意与union()方法的区别。
- difference()方法相当于差集运算。
- symmetric_difference方法相当于对称差运算。
- issubset()方法用于判断是否子集。issuperset()方法用于判断是否超集。