一、模型选择
1.1 模型的选择
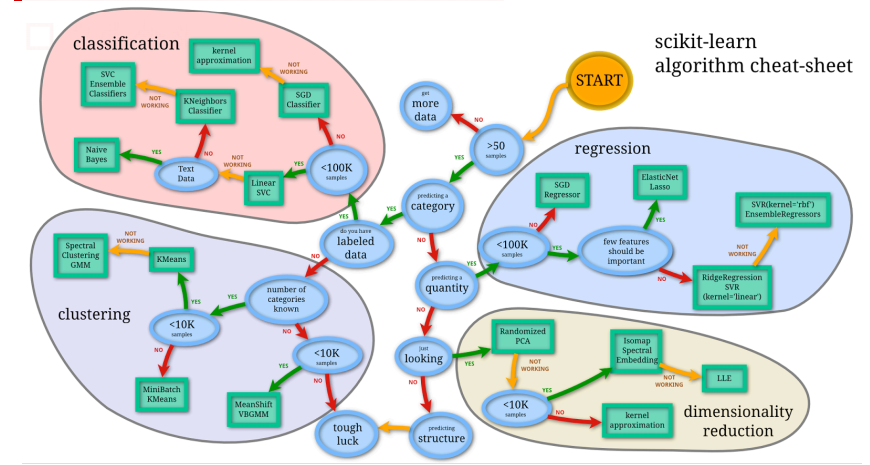
确定场景,划分为模型能解决的问题
根据样本大小确定模型,不是所有的样本都可以用DL/复杂模型,需要人工总结小样本数据的规律或采集更多的数据
注意数据形态,包括语音、图像、文本等
1.2 超参数的选择
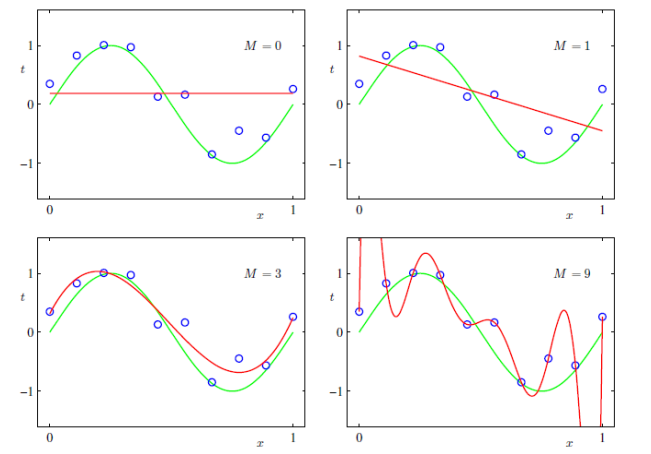
确定了某类模型之后,模型中可调的参数会影响模型的效果,可以通过交叉验证的方法来确定好的参数。
数据集被分为三部分:训练集、验证集、测试集
训练集:模型的训练
验证集:参数/模型的选择
测试集:模型效果的评估
扫描二维码关注公众号,回复: 2369262 查看本文章
交叉验证:基本思想就是将原始数据(dataset)进行分组,一部分做为训练集来训练模型,另一部分做为测试集来评价模型
作用:
- 用于评估模型的预测性能,尤其是训练好的模型在新数据上的表现,可以在一定程度上减小过拟合
- 从有限的数据中获取尽可能多的有效信息
不同方法:
留出法:随机将数据分为三组即可
不过如果只做一次分割,它对训练集、验证集和测试集的样本数比例,还有分割后的数据和原始数据集的分布是否相同等因素比较敏感,不同的划分会得到不同的最优模型,而且分成三个集合后,用于训练的数据更少了。
k折交叉验证:将训练数据随机分成k份,每次选择一份做验证集,其余k-1份做训练集,重复k次,得到k个验证结果,取平均最为评估效果的标准。一般建议k=10
通过对 k 个不同分组训练的结果进行平均来减少方差,因此模型的性能对数据的划分就不那么敏感。
参数的选择
K较小(比如2,也就是用一半的数据来训练,此时数据太少,模型复杂,会过拟合)的情况时偏差较低,方差较高,过拟合;K较高的情况时,偏差较高,方差较低,欠拟合;
最佳的模型参数取在中间位置,该情况下,使得偏置和方差得以平衡,模型针对于非样本数据的泛化能力是最佳的。
模型的选择
对不同的模型进行k折交叉验证,选择结果较好的模型。
特征的选择
通过交叉验证来进行特征的选择,对比不同的特征组合对于模型的预测效果
留一法:留一法就是每次只留下一个样本作为测试集,如果有m个样本,则要进行 m 次训练和预测。
BoostStrapping法:即在含有 m 个样本的数据集中,每次随机挑选一个样本,再放回到数据集中,再随机挑选一个样本,这样有放回地进行抽样 m 次,组成了新的数据集作为训练集。
工业界其实利用随机切分较多,因为工业的数据量很大。
二、模型效果优化
2.1 不同模型状态的处理

方差和偏差的权衡,也就是过拟合和欠拟合的权衡
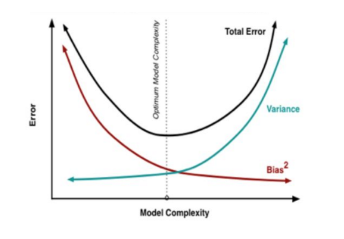
方差:形容一个模型的稳定性的,也就是参数分布的离散情况,如果参数分布很离散,说明模型很不稳定,参数幅值波动很大,会发生过拟合。
偏差:形容预测结果和真实结果的偏离程度的,如果偏差太大说明预测结果和真实结果差距很大,即模型的学习能力太弱,会发生欠拟合。
如何降低方差:对模型降维、增加样本输入、正则化
如何降低偏差:对模型升维、增加特征维度
模型状态验证工具——学习曲线(learning curve)
学习曲线:训练样本数——准确率的关系
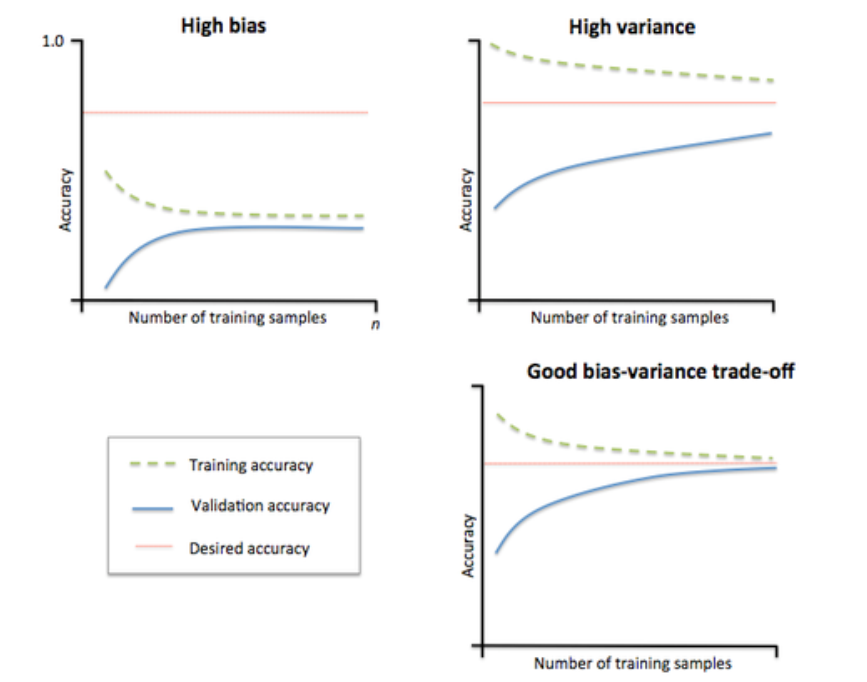
简述:
随着训练样本数的增大,训练集的准确率会降低,而验证集的准确率会增大。
因为如果是10个数据,模型将其记住就好了,不用学习底层规律,但验证集的准确率会很低;
如果有100个数据,模型稍微学到了一些规律,但是不全面,此时训练集的准确率会降低,但是验证集的准确率会有升高;
如果有10000个数据,模型基本上学到了样本和标签间的规律,训练集准确率还会下降,但是验证集的准确率会上升;
如果训练数据达到了10w个,模型的训练准确率降低的空间已经很小了,正常情况下,训练数据集和验证数据集的准确率会很接近。
在高bias情况下如何处理:
之所以出现高偏差是因为模型太过简单,没有能力学习到样本的底层规律,所以训练集和验证集的准确率都会很低。
在高variance情况下如何处理:
之所以会出现高方差是因为,模型太过复杂,学习太过,在训练集的准确率较好,但是在验证集上的泛化能力较差,验证集的准确率较低,两个准确率相差较大。
2.2 线性模型的权重分析

2.3 Bad-case分析

2.4 模型融合
模型融合:把独立的学习器组合起来的结果
如果独立的学习器为同质,称为基学习器(都为SVM或都为LR)
如果独立的学习器为异质,称为组合学习器(将SVM+LR组合)
为什么要进行模型融合:
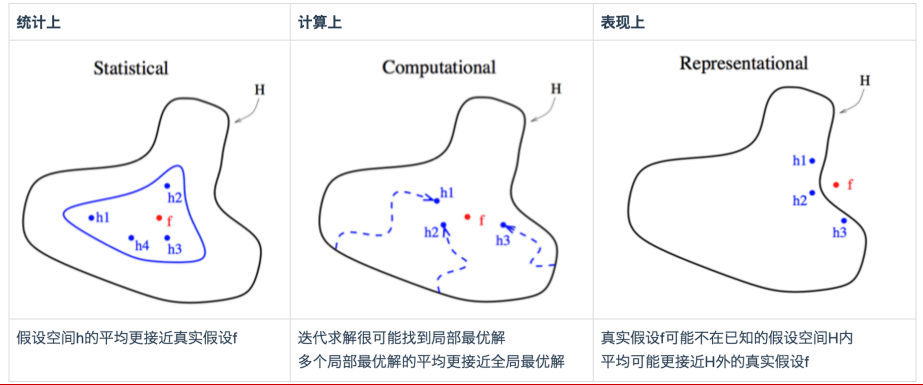
将几个独立学习器的结果求平均,在统计、计算效率、性能表现上都有较好的效果。
统计上:假设空间中几个学习器的假设函数的平均更接近真实的假设f
计算上:迭代求解可能落入局部最优解,但是多个局部最优解的平均更接近全局最优解
损失函数有可能不是光滑的,不同的初始点和学习率可能有不同的局部最小,将其平均能得到更好的。
性能表现上:真实的假设函数f可能不在已知的假设空间H内,学习器的平均更可能接近H外的真实假设H
如果模型本身就不具备表达场景的能力,那么无论怎么搜索H都不会搜到。
模型融合的例子:
1、Bagging



2、Stacking
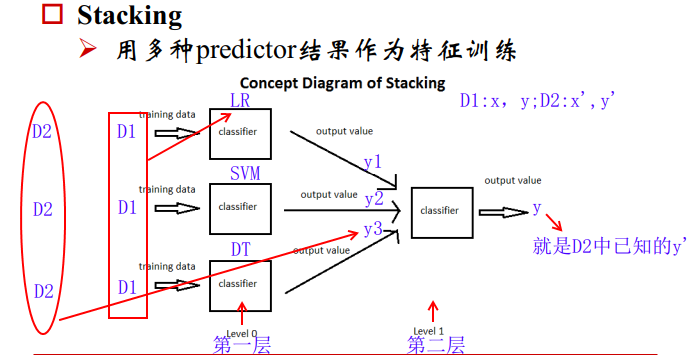
- 将训练集划分为两个正交集D1(x,y),D2(x’,y’)
- 利用D1来学习三个模型,假设分别为LR,SVM,DT
- 利用第二份数据D2的x分别作为第一层学到的三个模型的输入,得到预测值y1,y2,y3,将其组合可以得到预估的输出
- 已有真实输出的标签y’,可以学习到如何从预估的 ,来学习如何得到真实的y
第一层的数据:为了训练得到三个模型
第二层的数据:为了用三个模型来预测输出,得到的输入送入线性分类器得到最终的预估 ,再不断的训练模型使得模型的预估和真实的 最接近
之所以将数据分成两组,是为了避免过拟合
3、Adaboost



4、Gradient Boosting Tree
解决回归问题
通过不断的拟合预测和真实的残差来学习,也就是每次迭代尽量拟合损失函数在当前情况下的负梯度,构建的树是能使得损失函数降低最多的学习器,来解决回归问题,调整后也能解决分类问题。