一、理论基础
考虑如图1所示的一个变换,即将点P经过一个运算映射f映射成点Q。下面解释如果现在已知了P和Q的坐标,应该如何求出这个变换f

写成矩阵形式
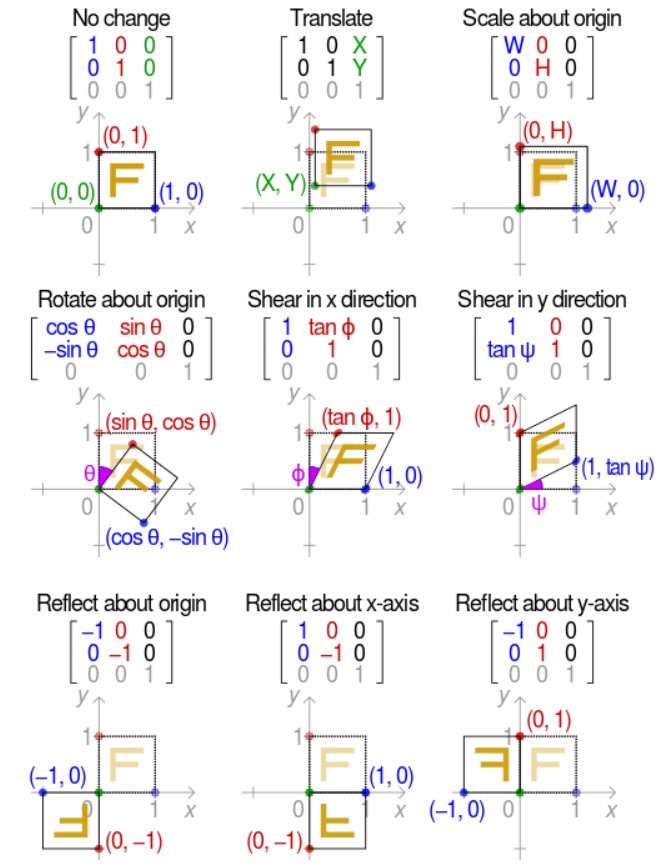
二维坐标的变化用三维矩阵的原因是要增加一个偏移量t的维度,否则t无法表现在映射关系f中。为了更深刻地理解第三维度,将其和线性变换作对比。线性变换的特点是:①变换前后,直线仍然是直线②变换前后,原点位置不变。 给出线性变换的变换矩阵:
将(0,0)代入显然原点位置不变。将
=(1,0)以及
=(0,1)代入可以得到一组新的由变换矩阵完全决定的基底,因此线性变换就是保持原点位
置不变,将两条坐标轴(基底)进行变换,得到一个变换后新的坐标轴,原坐标系所有点被这个变换矩阵映射到新坐标系的对应点,而加入了第三维度偏移量之后的变换过程就可能使坐标原点发生平移,因此可能涵盖更多的变换,图3总结了三维度变换的可能情况。
二、算法实现
在OpenCV中,可使用cv2.warpAffine()进行操作。其中的参数Matrix就是变换矩阵,不过这里用户提供给cv2.warpAffine()的变换矩阵只要是
一个2×3的矩阵即可,也就是包含以下参数的矩阵:
因为所有变换矩阵的第三行都是确定的,该方法可以自动添加。
下面进行测试检验:
import cv2
import numpy as np
img = cv2.imread(r'C:\Users\91398\Desktop\test.jpg',1)
imgHeight = img.shape[0]
imgWidth = img.shape[1]
mat = np.float32([[1,0,0],[0,1,0]])
dstImg = cv2.warpAffine(img,mat,(imgWidth,imgHeight))
cv2.imshow('src.jpg',dstImg)
cv2.waitKey(0)
cv2.destroyAllWindows()
这个代码段给出的就是原图像如图3(i),这点可以从2×3的变换矩阵系数看到。现在对其逆时针翻转90°,修改mat参数即可,得到图3(ii)可以发现其完全变黑,观察算法理论知,这是因为整个图片被旋转到了画布之外。对旋转90°的变换矩阵增加一点y分量,也即旋转后再将y轴平移一个距离,可看到图像出现,这也证明了之前的黑色是因为图像出现在画布外。



从上面的操作可以看出,虽然给cv2.warpAffine()传递一个变换矩阵,确实可以做到图像的各种变换,但每次操作都可能要进行横轴或纵轴的平移,这是很不方便的,因此在此基础上引入了一些新的方法:
cv2.getRotationMatrix2D((x_center,y_center),theta,scaling=1)
这个方法可以得到一个自定义旋转中心的变换矩阵,免去了旋转+平移的操作
cv2.getAffineTransform(pos1,pos2)
这个方法可以得到一个未知关系的变换矩阵,因为很大一部分变换并不能明确地使用图3的某种变换来实现,但我们已经知道变换前后的某三组点,那么可以根据这个方法求出这个变换矩阵,并将其应用于整个图像,使整个图像实现已知三组点的所谓变换。这里强调三组点的原因是二维平面变换矩阵 有6个未知参数,一组点可以产生两个方程,因此需要三组点。可以推广,在三维平面的变换就需要四组点来实现矩阵求解。
三、总结
进行图像仿射变换的关键在于变换矩阵的求解。在简单的平移、旋转等变换时,可以自己手动传入一个变换矩阵,注意这个矩阵得用np.float32格式;也可以用OpenCV自定义中心的方法来实现。对于比较复杂,关系未知的变换,可以找到其中的三组点,用cv2.getAffineTransform()来求解变换矩阵,再传入cv2.warpAffine()