hdu 4825链接

题目意思很简单,就是要求最大异或值的数。
我们可以从二进制的最高位开始选择,不断的排除一些数。我们先假设存在某些数字的二进制数是与当前查找的数不一样的,我们进入这一部分数进行查找,以此重复,不断排除一部分数,最后找到最佳的数。
如果在查找的过程中某一位不存在不相同的数,我们就只能从相同的数中查找了。
总结一句就是优先查找不同的。
#include<iostream>
#include<cstring>
#include<cstdio>
using namespace std;
typedef unsigned int ui;//unsigned int防止出现爆int.
const int N1 = 4e6 + 10;
ui trie[N1][2], tot, flag[N1];
void build_trie(ui x) {//建立字01字典树的过程。
int root = 0;
for(int i = 31; i >= 0; i--) {题意不超过2^32,从32位开始,其实也可以30,但是不要超过31,如果用int.
int u = x >> i & 1;
if(!trie[root][u]) trie[root][u] = ++tot;
root = trie[root][u];
}
flag[root] = x;//这个节点标记为这个数的值。
}
ui find_max(ui x) {//找到与之匹配的异化值最大的数。
int root = 0;
for(int i = 31; i >= 0; i--) {
int u = x >> i & 1;//取出这一位的二进制数。
if(trie[root][!u])//优先进入与之不同的二进制数位。
root = trie[root][!u];
else root = trie[root][u];
}
return flag[root];//返回查找的最优答案。
}
int main() {
// freopen("D:\\Code\\ce.txt", "r", stdin);
ui t, a, n, m;
scanf("%u", &t);
for(int k = 1; k <= t; k++) {
printf("Case #%d:\n", k);
tot = 0;
memset(trie, 0, sizeof trie);//多组读入,注意清零。
scanf("%u %u", &n, &m);
for(int i = 0; i < n; i++) {
scanf("%u", &a);
build_trie(a);
}
for(int i = 0; i < m; i++) {
scanf("%u", &a);
printf("%u\n", find_max(a));
}
}
return 0;
}
hdu 1251链接

这题应该比上题还简单,直接上代码了。
#include<iostream>
#include<cstring>
#include<cstdio>
using namespace std;
const int N = 3e6 + 10;
int trie[N][26], flag[N], tot;
char s[20];
void build_trie() {
int root = 0, n = strlen(s);
for(int i = 0; i < n; i++) {
int u = s[i] - 'a';
if(!trie[root][u]) trie[root][u] = ++tot;
root = trie[root][u];
flag[root]++;//单词经过的节点,加一。
}
}
int find_sum() {
int root = 0, n = strlen(s);
for(int i = 0; i < n; i++) {
int u = s[i] - 'a';
if(!trie[root][u]) return 0;//出现一个字母在字典中不匹配,立即返回查找不到。
root = trie[root][u];
}
return flag[root];//返回这个节点有多少单词经过
}
int main() {
// freopen("D:\\Code\\ce.txt", "r", stdin);
while(gets(s)) {
if(s[0] == 0)
break;
build_trie();
}
while(gets(s))
printf("%d\n", find_sum());
return 0;
}
hdu 1247链接
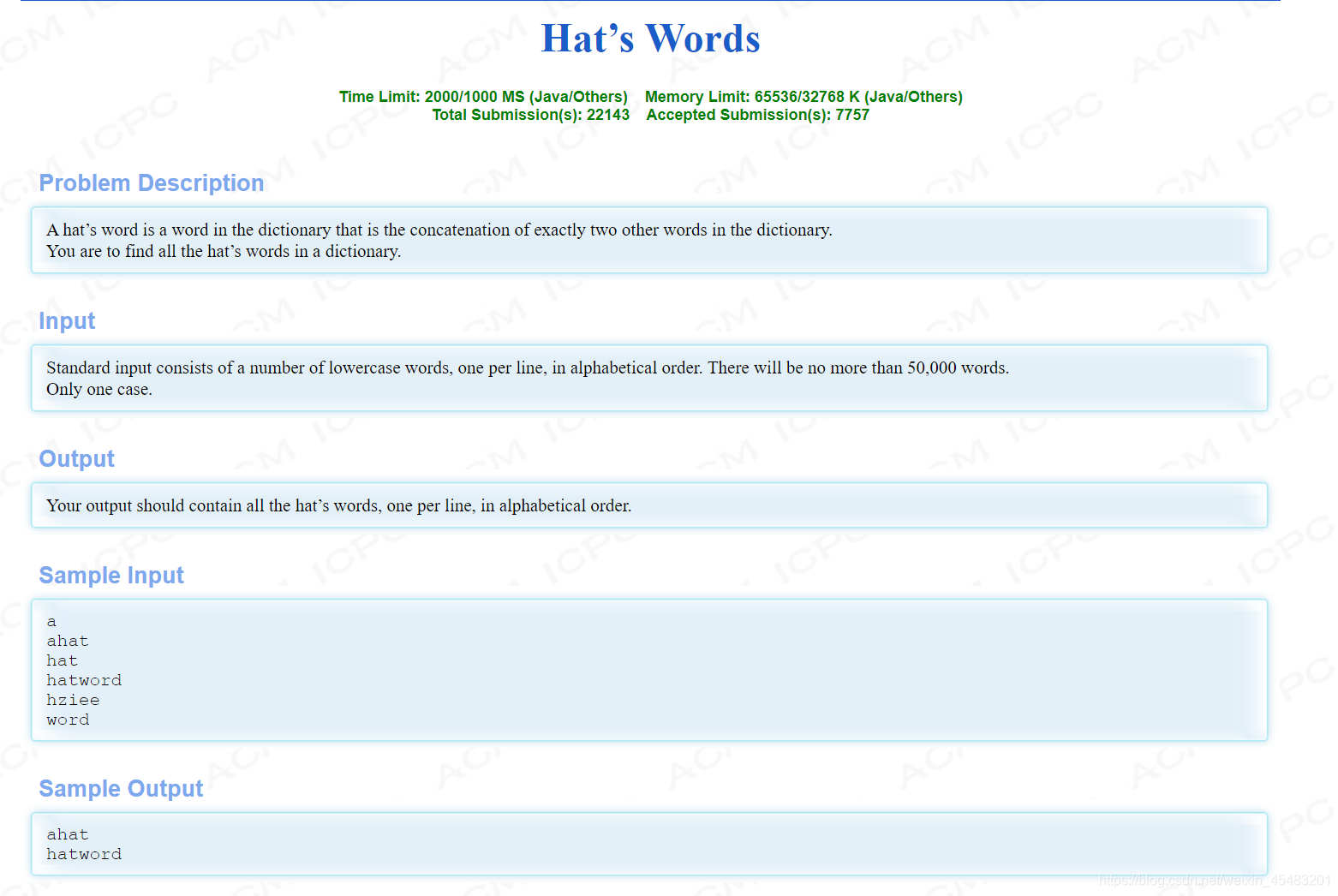
这题应该是比上两题更难一点,具体看代码详解吧。
#include<iostream>
#include<cstdio>
#include<cstring>
using namespace std;
const int N1 = 5e6 + 10, N2 = 5e4 + 10;
int trie[N1][26], is_word[N1], tot;
string str[N2];
void build_trie(string s) {//建字典树。
int root = 0, n = s.size();
for(int i = 0; i < n; i++) {
int u = s[i] - 'a';
if(!trie[root][u]) trie[root][u] = ++tot;
root = trie[root][u];
}
is_word[root] = 1;//标记这个节点有单词。
}
bool judge_tail(string s, int pos) {//判断后缀是否是一个单词,pos是后缀的起始位置。
int root = 0, n = s.size();
for(int i = pos; i < n; i++) {
int u = s[i] - 'a';
if(!trie[root][u]) return false;
root = trie[root][u];
if(is_word[root] && i == n - 1)//整个需要判断的后缀是否是一个单词。
return true;
}
return false;
}
bool judge_front(string s) {//这里判断单词的前缀是否是一个单词。
int root = 0, n = s.size();
for(int i = 0; i < n; i++) {
int u = s[i] - 'a';
if(!trie[root][u]) return false;//有一个字母没有查找到,返回失败。
root = trie[root][u];
if(is_word[root] && judge_tail(s, i + 1))//前缀是一个单词,接下来就是判断后缀是否是一个单词。
return true;
}
return false;
}
int main() {
// freopen("D:\\Code\\ce.txt", "r", stdin);
int n = 0;
while(cin >> str[n])
build_trie(str[n++]);
for(int i = 0; i < n; i++)
if(judge_front(str[i]))
cout << str[i] << endl;
return 0;
}
Poj 3764链接
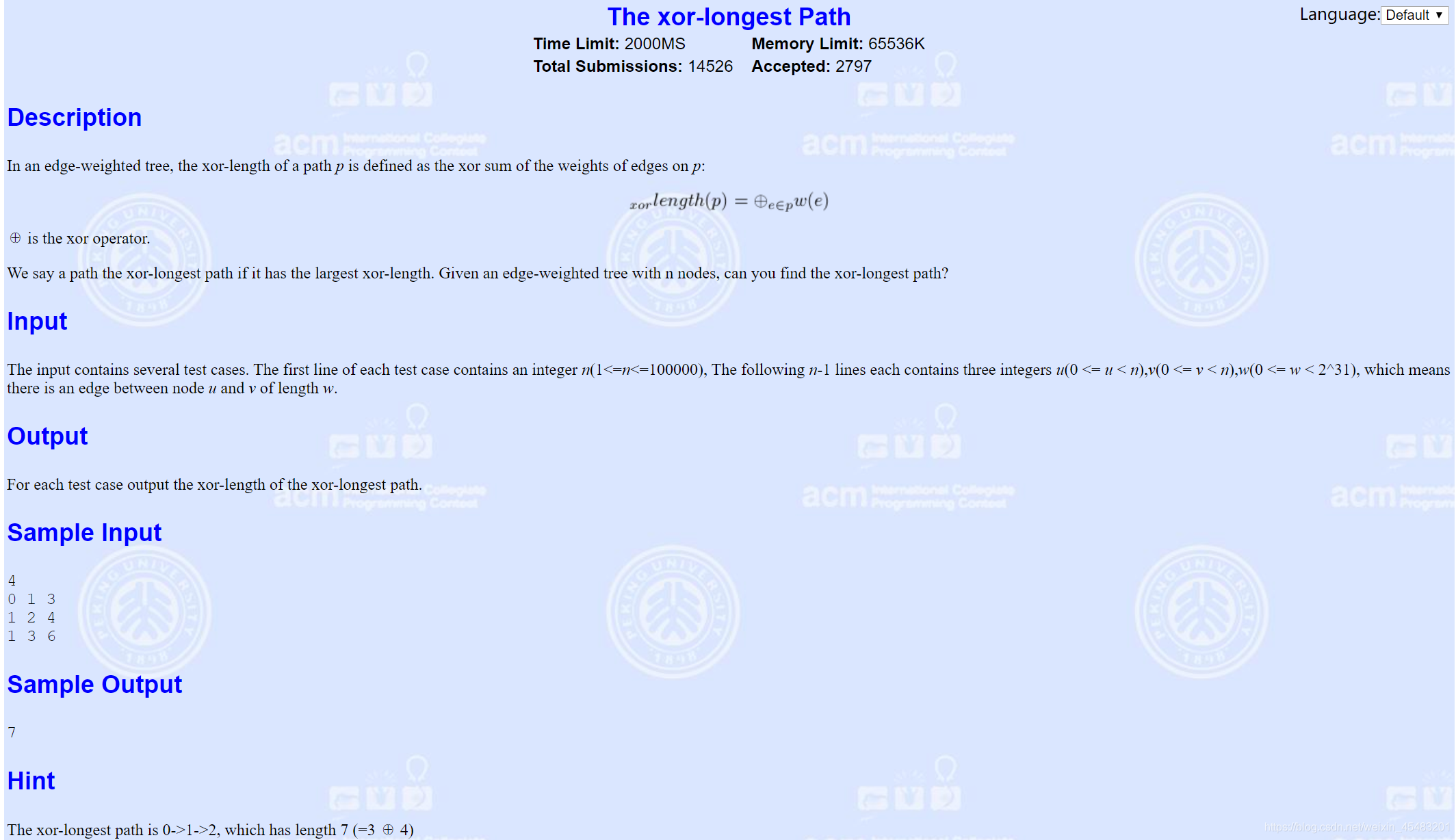
这题应该是这几题里面最难的题了,但是却又跟第一题有点类似。
#include<iostream>
#include<algorithm>
#include<cstring>
#include<cstdio>
using namespace std;
const int N1 = 2e5 + 10, N2 = 4e6 + 10;
int trie[N2][2], tot, cnt, n, head[N1], a[N1];
struct Edge {//链式向前星。
int to, next, value;
}edge[N1];
void add(int x, int y, int value) {//存图的过程
edge[cnt].to = y;
edge[cnt].value = value;
edge[cnt].next = head[x];
head[x] = cnt++;
}
void dfs(int u, int fa, int sum) {//通过dfs得到每个节点到根节点的异或值。
a[u] = sum;
for(int i = head[u]; i; i = edge[i].next) {
if(edge[i].to != fa) dfs(edge[i].to, u, sum ^ edge[i].value);
}
}
void build_trie(int x) {//建立字典树。
int root = 0;
for(int i = 30; i >= 0; i--) {
int u = x >> i & 1;
if(!trie[root][u]) trie[root][u] = ++tot;
root = trie[root][u];
}
}
int find_max(int x) {//查找最大值。
int root = 0, ans = 0;
for(int i = 30; i >= 0; i--) {
int u = x >> i & 1;
if(trie[root][!u]) {
ans += (1 << i);//如果走这里的话,我们可以得到答案的这一位是1,或者我们可以像第一题一样现在建立字典树的时候记录下节点的值然后在返回这个最大值,最后再和当前查找的异或。
root = trie[root][!u];
}
else root = trie[root][u];
}
return ans;
}
int main() {
while(scanf("%d", &n) != EOF) {
tot = 0, cnt = 1;
memset(trie, 0, sizeof trie);
memset(head, 0, sizeof head); //多组输入, 清零。
for(int i = 1; i < n; i++) {
int x, y, v;
scanf("%d %d %d", &x, &y, &v);
add(x, y, v);
add(y, x, v);
}
dfs(0, 0, 0);
for(int i = 0; i < n; i++)//得到异或值后,开始建字典树。
build_trie(a[i]);
int ans = 0;
for(int i = 0; i < n; i++)
ans = max(ans, find_max(a[i]));
printf("%d\n", ans);
}
return 0;
}