注:原文中的代码是在spark-shell中编写执行的,本人的是在eclipse中编写执行,所以结果输出形式可能会与这本书中的不太一样。
首先将用户数据u.data读入SparkContext中,然后输出第一条数据看看效果,代码如下:
val sc = new SparkContext("local", "ExtractFeatures")
val rawData = sc.textFile("F:\\ScalaWorkSpace\\data\\ml-100k\\u.data")
println(rawData.first())
注意:第一行代码我创建了spark上下文,如果你是在spark-shell中运行代码,它会自动创建好spark上下文,名字为sc,我是在eclipse中编写代码,所以需要自己编写代码创建spark上下文,我们可以看到有如下输出:

每条数据是由“\t”分隔的,我们现在要取出每条数据,然后再取到每条数据的前三个元素,即用户ID,电影ID,用户给电影的评分,代码如下:
val rawRatings = rawData.map(_.split("\t").take(3))
rawRatings.first().foreach(println)
可以看到类似如下的输出:

接下来我们将使用spark内置的MLlib库来训练我们的模型。先来看看有哪些方法可以使用,需要什么参数作为输入。首先我们导入内置库文件ALS:
import org.apache.spark.mllib.recommendation.ALS
接下来的操作是在spark-shell中完成的。在控制台下输入ALS.(注意ALS后面有一个点)加上tap键:

我们将要使用到的方法是train方法。
如果我们输入ALS.train,会返回一个错误,但是我们可以从这个错误中看看这个方法的细节:
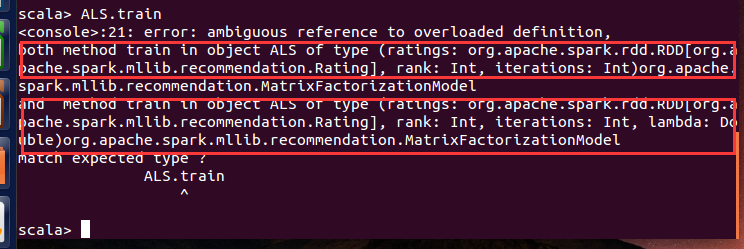
可以看到,我们最少要提供三个参数:ratings,rank,iterations,第二个方法还需要另外一个参数lambda。我们先来看看参数rating的类Rating:
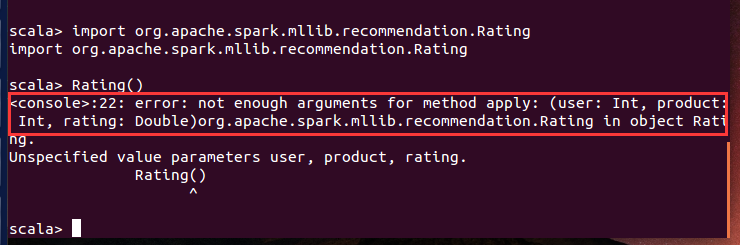
我们可以看到,我们需要向ALS模型提供一个包含Rating的RDD,Rating将user id,movie id(就是这里的product)和rating封装起来。我们将在评分数据集(rating dataset)上使用map方法,将ID和评分的数组转换成Rating对象:
val ratings = rawRatings.map {
case Array(user, movie, rating) =>
Rating(user.toInt, movie.toInt, rating.toDouble)
}
println(ratings.first())
输出如下:

现在我们得到了一个Rating类型的RDD。