本篇博主带来的是Kafka常用脚本介绍及简单的shell操作。
一. Kafka常用脚本
至于怎样查看脚本,我们可以查看Kafka/bin目录,下图标记即为常用的脚本
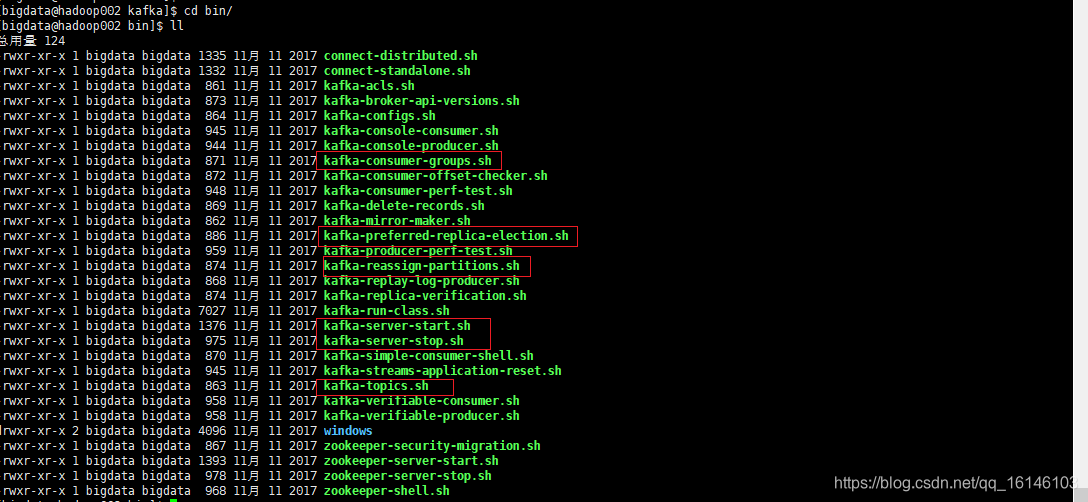
- 1.kafka-topics.sh:对topic进行增删改查
- 2.kafka-server-start.sh:启动脚本
- 3.kafka-server-stop.sh:关闭脚本
- 4.kafka-consumer-groups.sh:展示所有的消费者组的信息 ,消费者消费的分区也会在这个脚本内显示出来
- 5.kafka-reassign-partitions.sh:重新分配partitions
- 6.kafka-preferred-replica-election.sh:每个partitions leader的重新分配
- 7.kafka-console-consumer.sh:消费者控制台 / 常用测试
- 8.kafka-console-producer.sh:生产者控制台 / 常用测试
二. 简单的shell操作
- 1. 查看当前服务器中的所有topic
[bigdata@hadoop002 kafka]$ bin/kafka-topics.sh --zookeeper hadoop002:2181 --list
- 2. 创建topic
[bigdata@hadoop002 kafka]$ bin/kafka-topics.sh --zookeeper hadoop002:2181 --create --replication-factor 3 --partitions 1 --topic first
Created topic "first".
[bigdata@hadoop002 kafka]$ bin/kafka-topics.sh --zookeeper hadoop002:2181 --create --replication-factor 2 --partitions 3 --topic second
// 再次查看
[bigdata@hadoop002 kafka]$ bin/kafka-topics.sh --zookeeper hadoop002:2181 --list
first
- 选项说明:
–topic 定义topic名
–replication-factor 定义副本数
–partitions 定义分区数
- 3. 查看topic详细信息
[bigdata@hadoop002 kafka]$ bin/kafka-topics.sh --zookeeper hadoop002:2181 --describe --topic second

- 3. 修改topic分区个数(只能能加不能减少否则会报错)
① 如果减少会报错
[bigdata@hadoop002 kafka]$ bin/kafka-topics.sh --zookeeper hadoop002:2181 --alter --topic second --partitions 2 // 再次以两个为例

② 正确写法
[bigdata@hadoop002 kafka]$ bin/kafka-topics.sh --zookeeper hadoop002:2181 --alter --topic second --partitions 5
这时我们再次查看

这时,有的同学会问配置的文件存储在哪个位置。不知道同学们还记不记得配置Kafka时,有一个logs文件夹。我们要的东西就存储在那里。
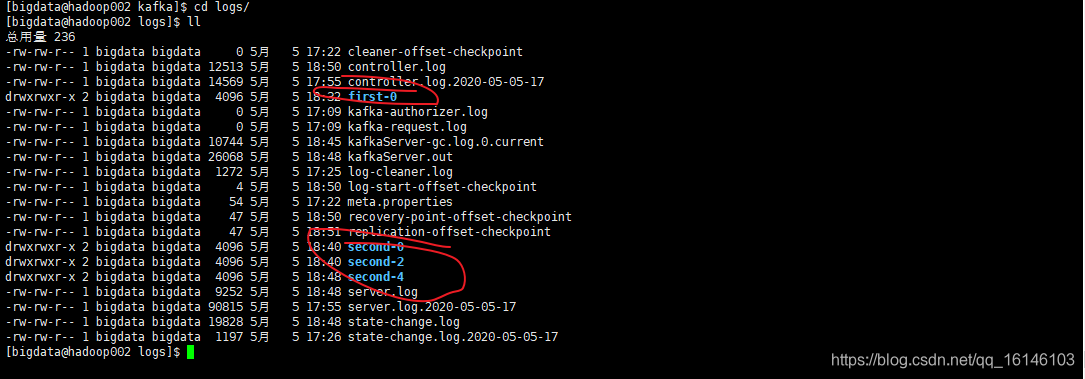
- 4. 删除topic
[bigdata@hadoop002 kafka]$ bin/kafka-topics.sh --zookeeper hadoop002:2181 --delete --topic second
需要server.properties中设置delete.topic.enable=true否则只是标记删除或者直接重启。
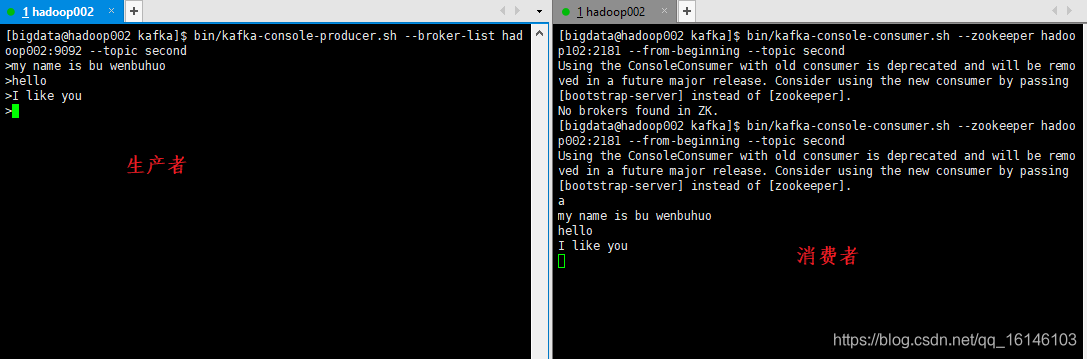
- 5. 发送消息
[bigdata@hadoop002 kafka]$ bin/kafka-console-producer.sh --broker-list hadoop002:9092 --topic second
- 6. 接收信息
[bigdata@hadoop002 kafka]$ bin/kafka-console-consumer.sh --zookeeper hadoop102:2181 --from-beginning --topic second
--from-beginning:会把first主题中以往所有的数据都读取出来。根据业务场景选择是否增加该配置。
- 7. 查看正在生产者的信息
[bigdata@hadoop003 kafka]$ bin/kafka-consumer-groups.sh --bootstrap-server hadoop002:9092 --list
// 显示详细信息
[bigdata@hadoop003 kafka]$ bin/kafka-consumer-groups.sh --bootstrap-server hadoop002:9092 --describe --group console-consumer-xxxxx
本次的分享就到这里了,

^ _ ^ ❤️ ❤️ ❤️
码字不易,大家的支持就是我坚持下去的动力。点赞后不要忘了关注我哦!