文章目录
一、Maxcompute在优酷的应用
1.1 优酷业务的特点

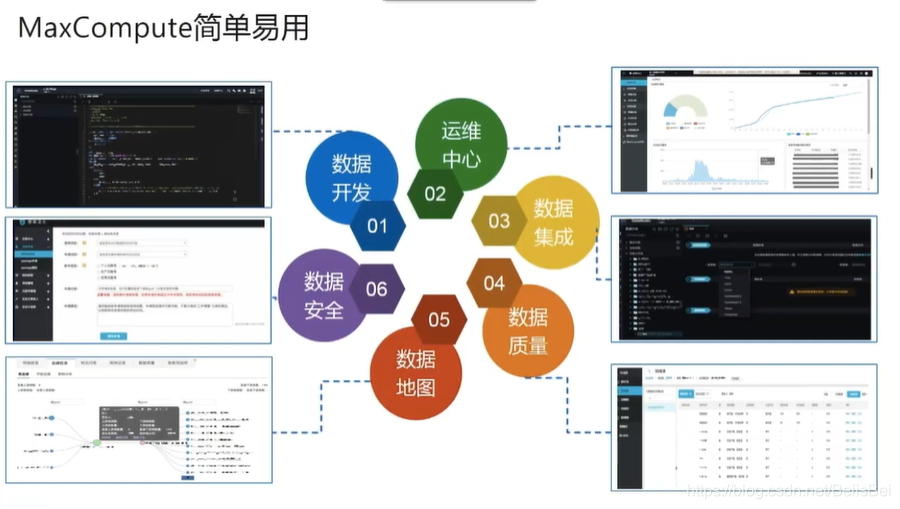
1.2 Maxcompute 简单易用
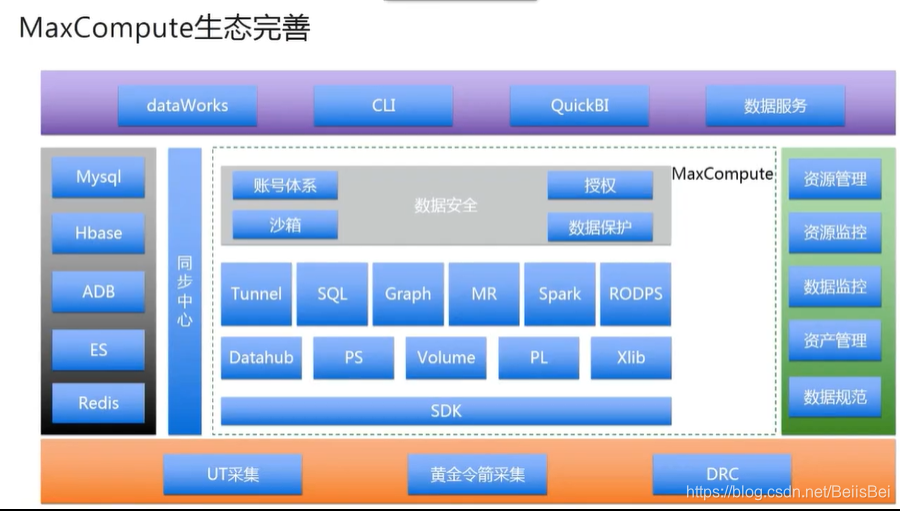
1.3 Maxcompute 生态完善
1.4 Maxcompute 性能强悍

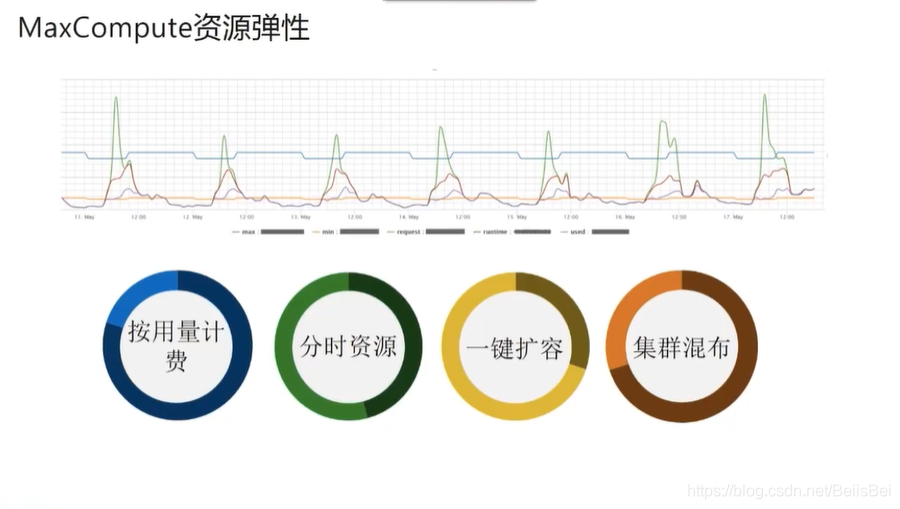
1.5 MaxCompute 资源弹性
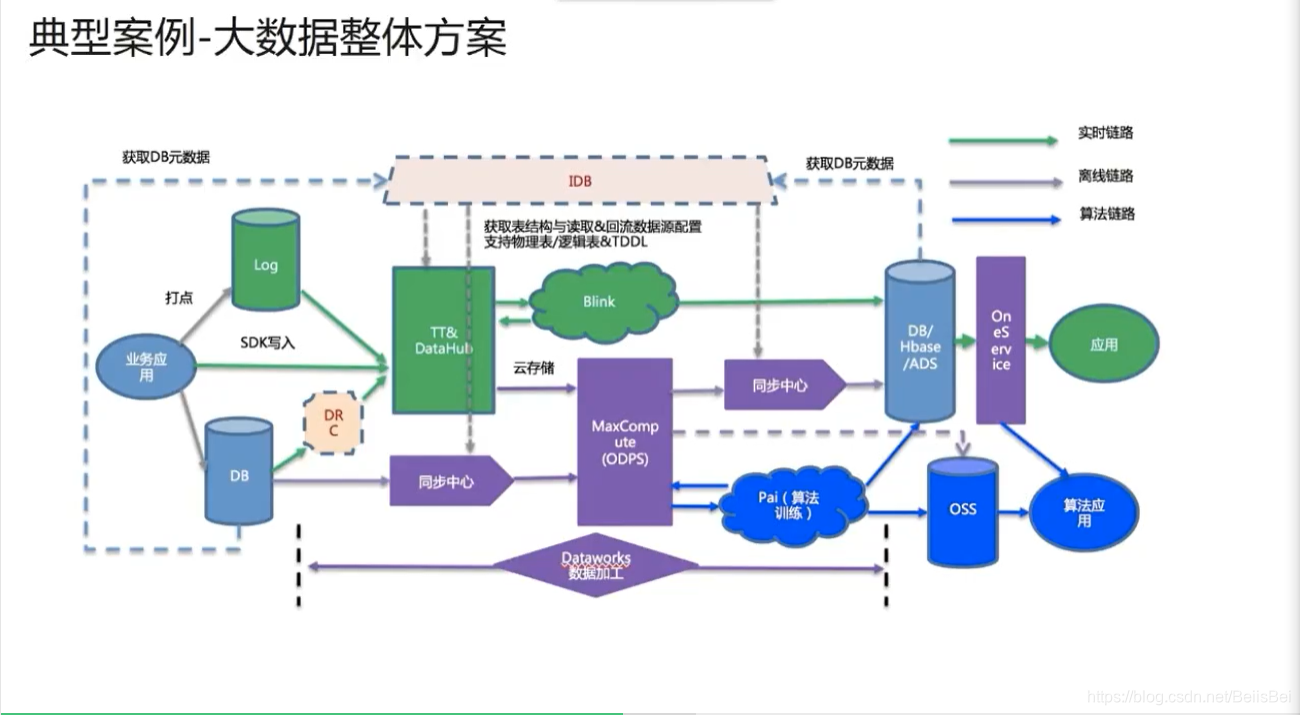
1.6 大数据整体方案
1.7 数据分层
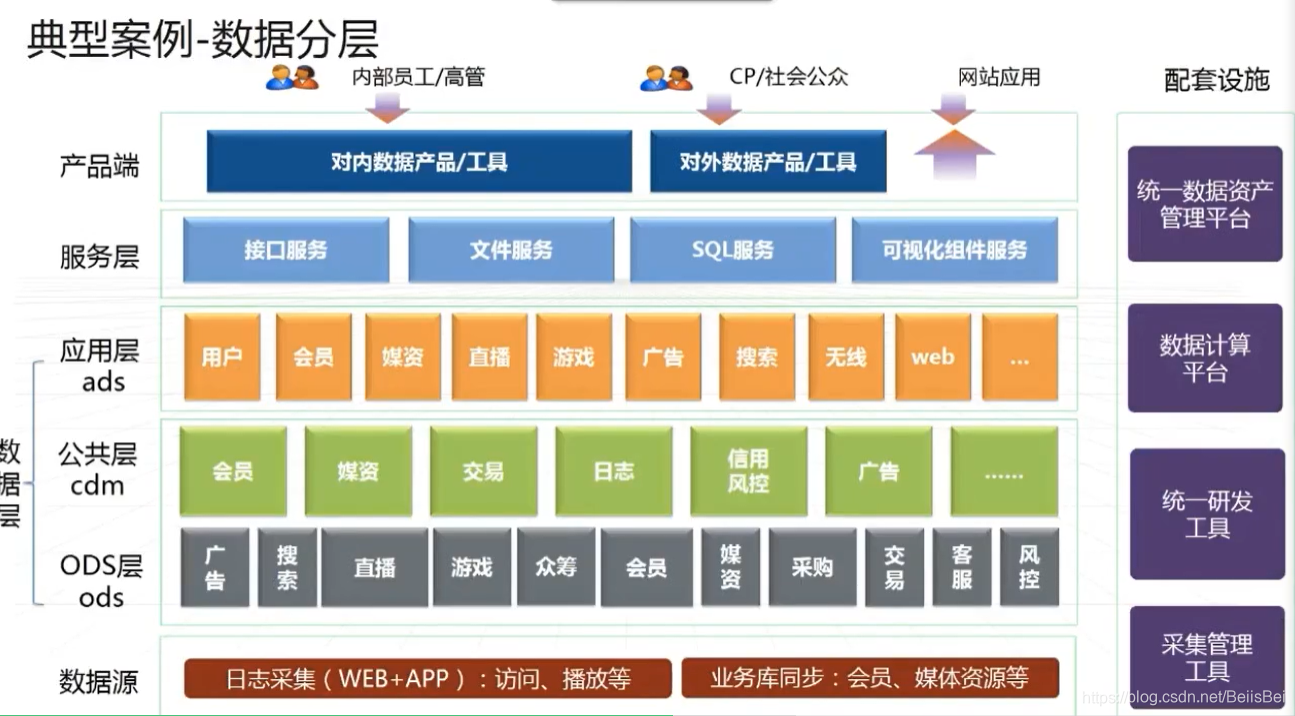
数据中台,从ODS层 ——> CDM层 ——> ADS层
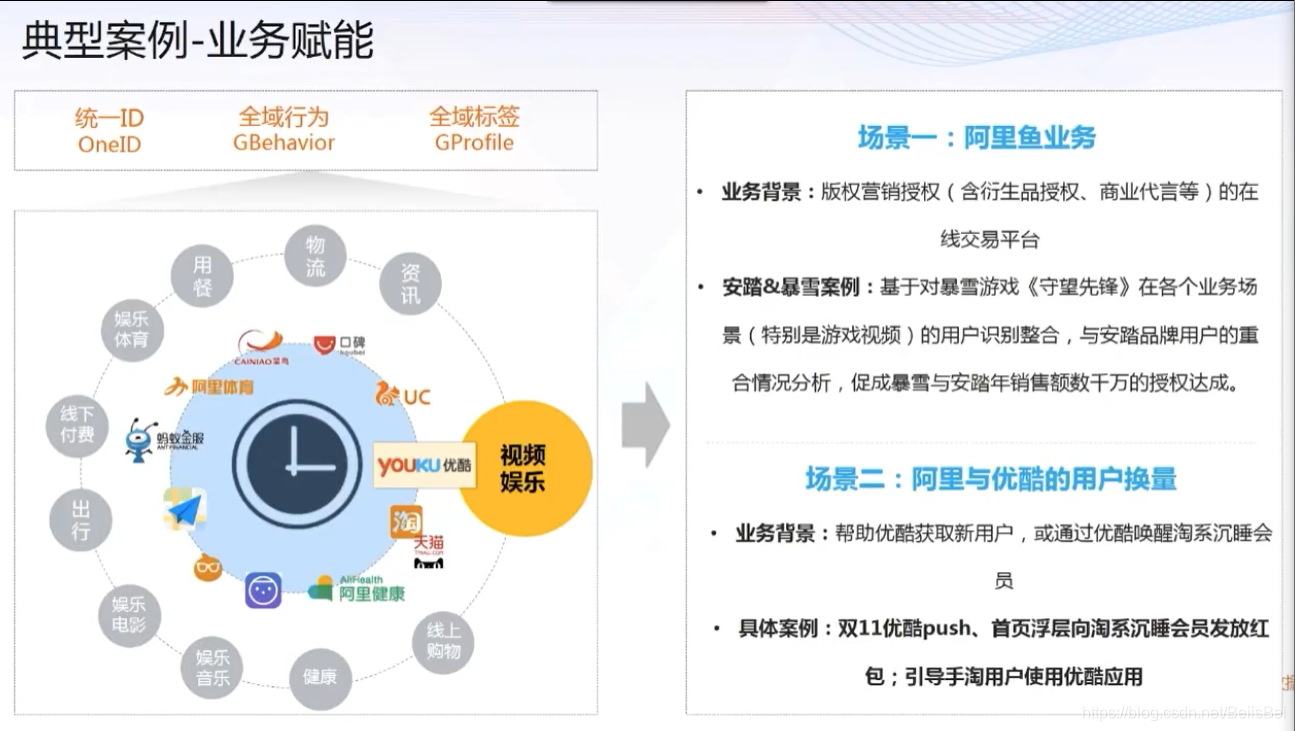
1.8 业务赋能
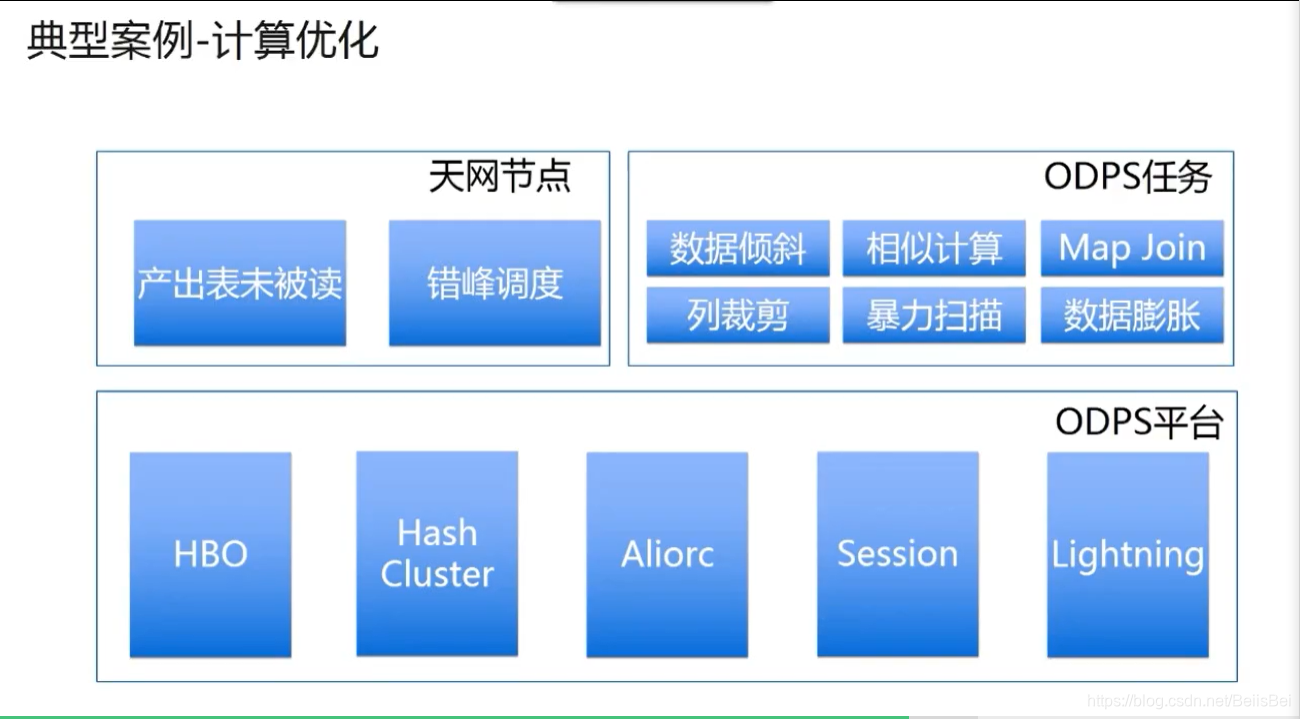
1.9 计算优化
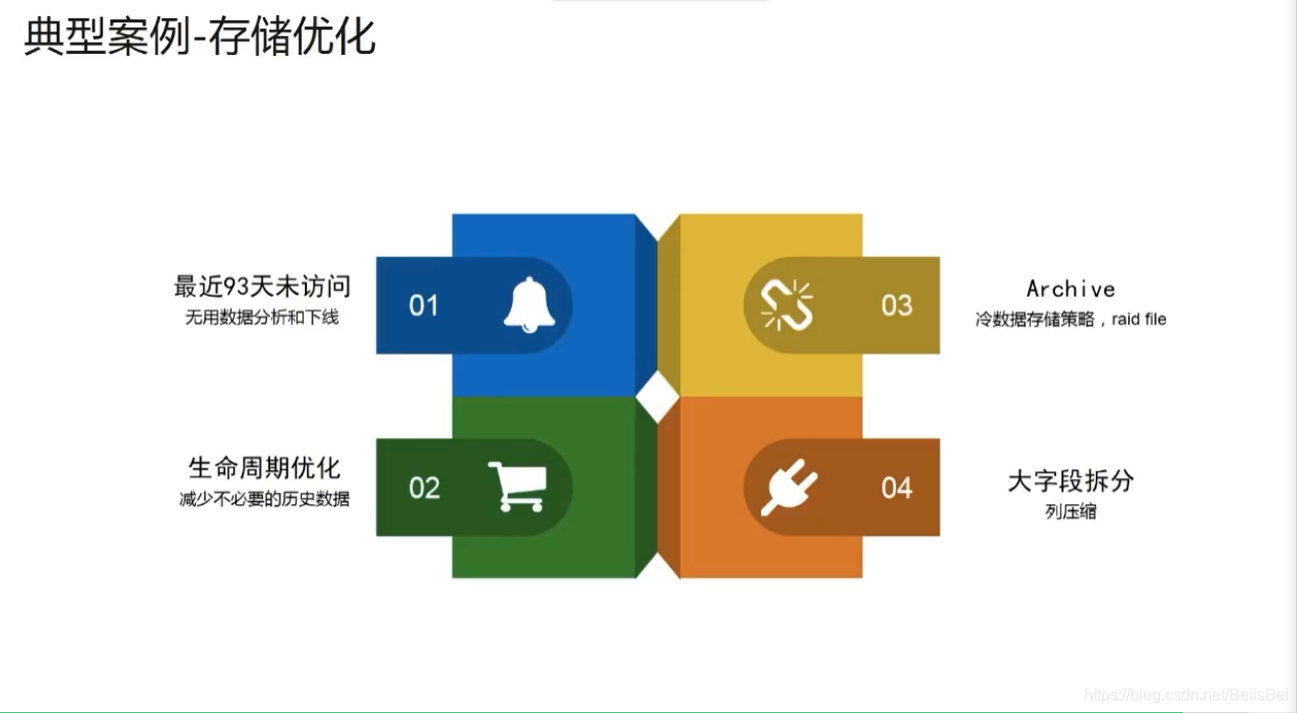
1.10 存储优化
二、斗鱼 MaxCompute + Hadoop 混搭大数据架构实践
2.1 自建集群的发展瓶颈

2.2 大数据上云的挑战
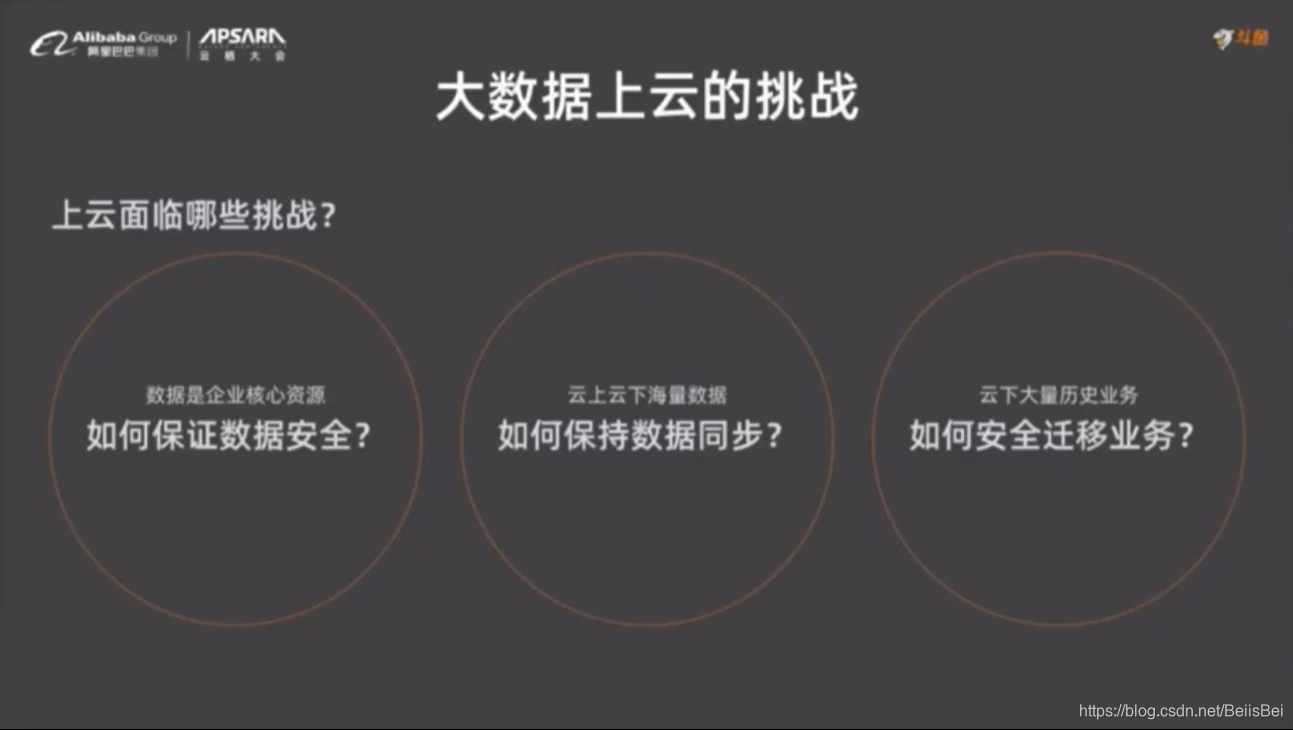
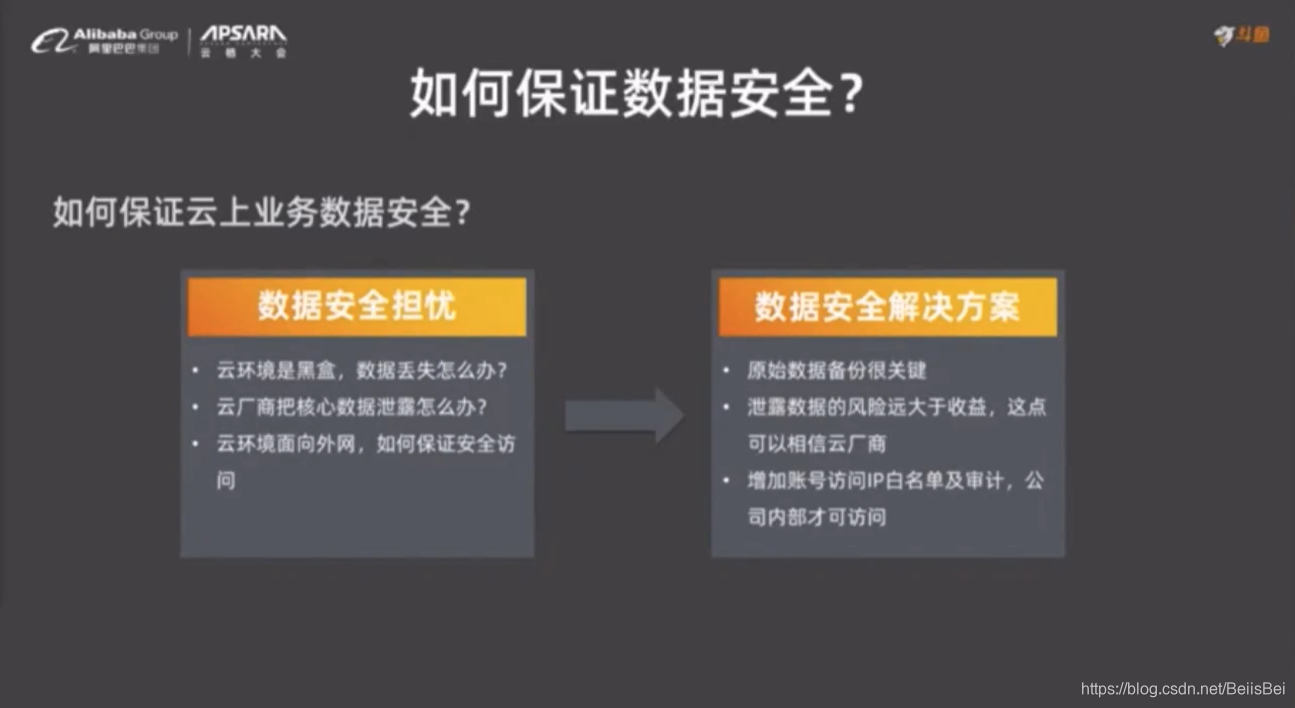
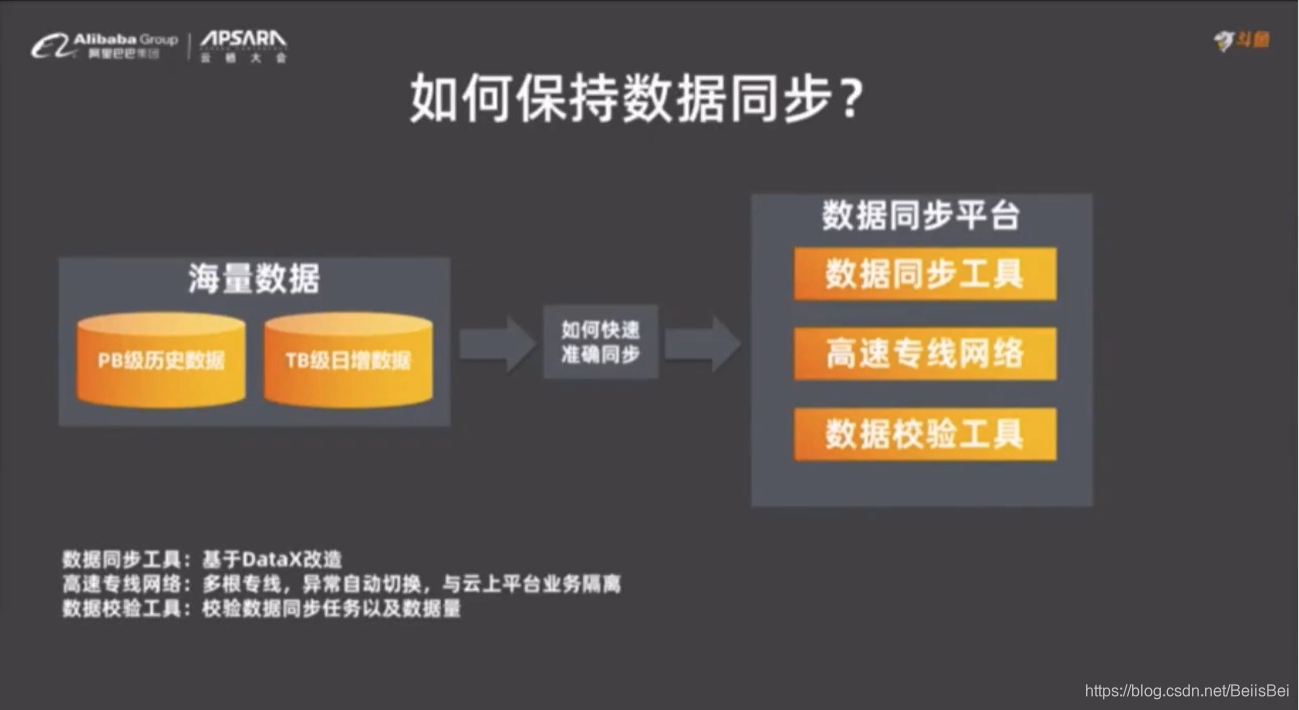


Hive 窗口函数 ,像 rank() ,MaxCompute 不支持,需要确定哪些业务可以迁到云上,哪些不可以。


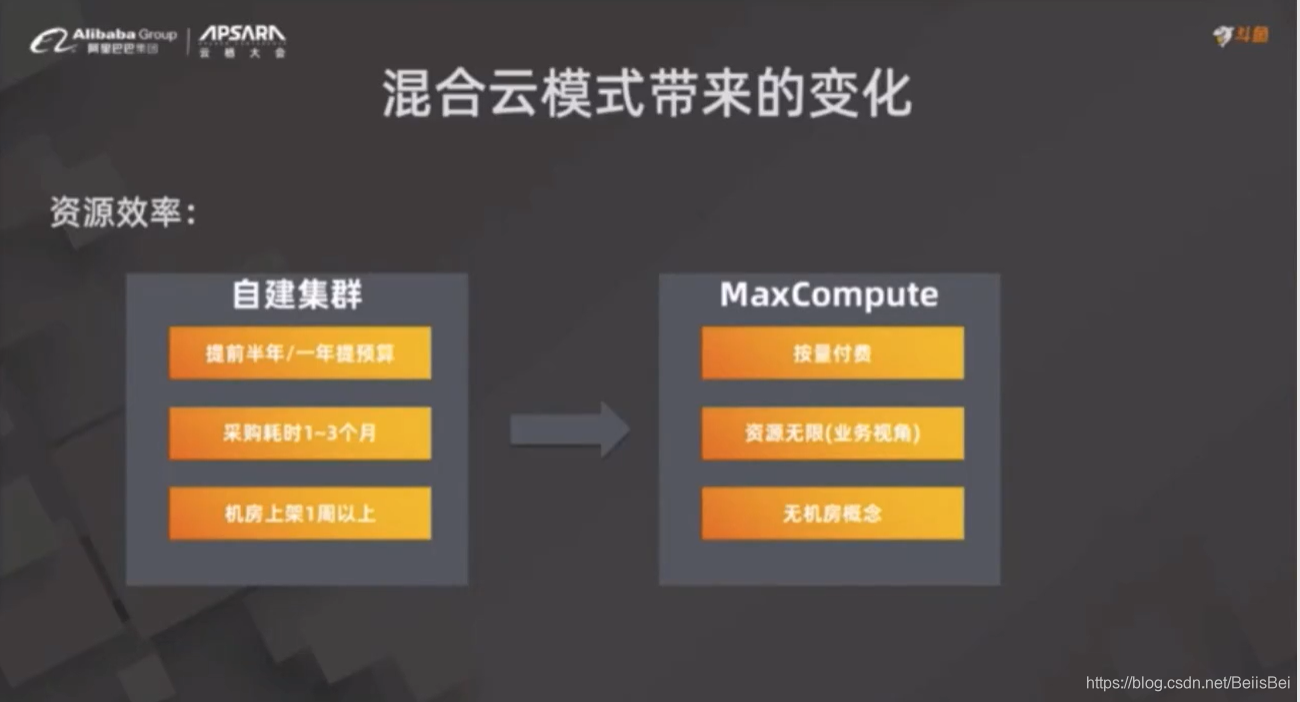
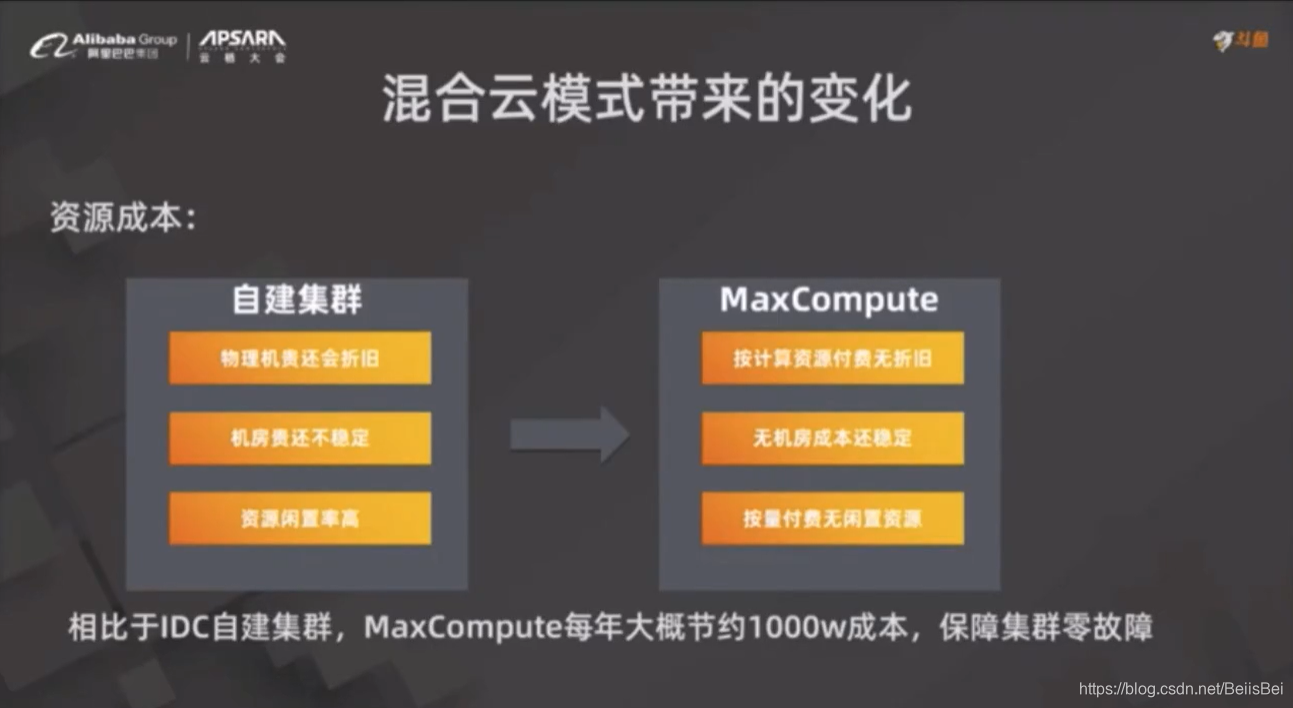
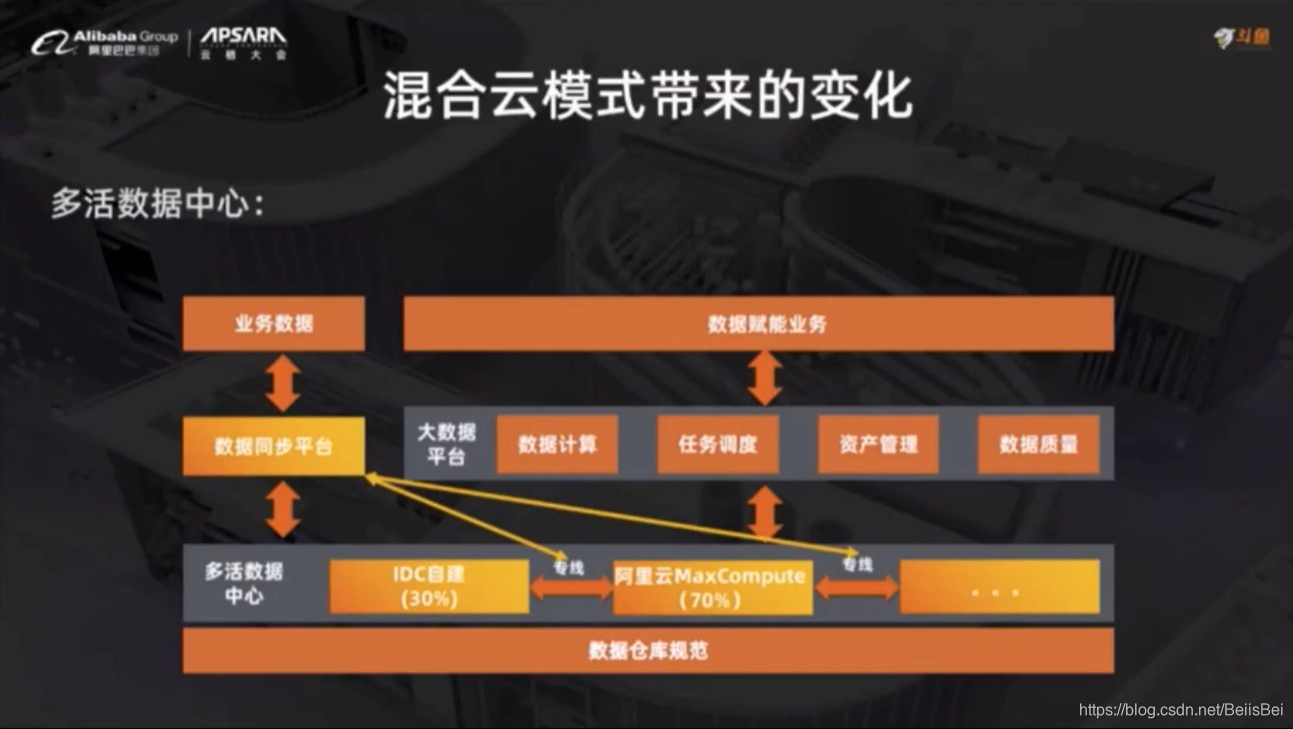
2.3 混合云模式带来的变化



三、MaxCompute SQL 优化
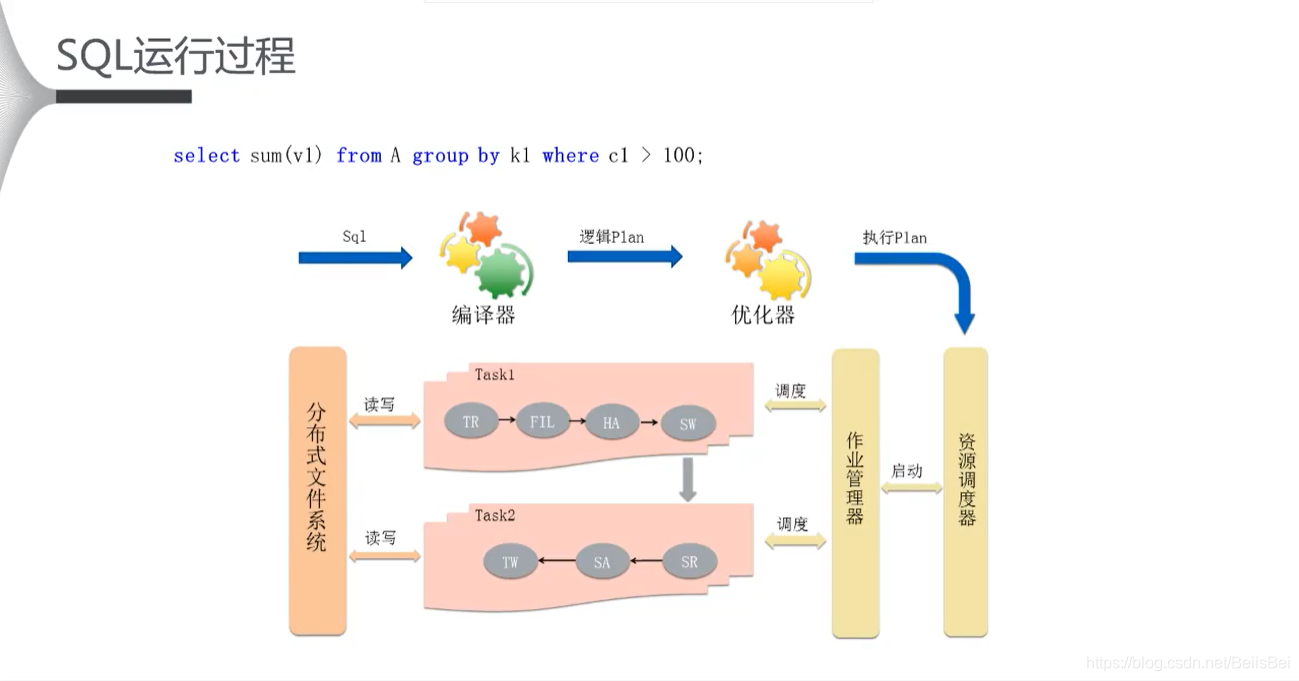
3.1 SQL 成本计算
- 计算成本 <- 读取IO数据量 * SQL复杂度
- SQL 复杂度:Join / Group By / Order By / Distinct / window func / Insert into
因此,优化SQL的过程,实际上就是要尽可能减少IO读取,尽可能减少计算资源使用,尽可能降低SQL复杂度,尽可能提升运行速度。
3.2 SQL IO 读取优化
3.2.1 表分区优化
- 建立分区表
Create Table t1 (...) partitioned by (pt string,region string)
分区层数不要太多
- 分区裁剪
避免全表扫描,减少资源浪费
Case:where pt = xxx and region = xxx
分区尽量按层级顺序剪裁
分区值尽量常量化,避免不可确定值,如UDF
分区值尽量避免引用列的表达式计算或者子查询
- 写分区
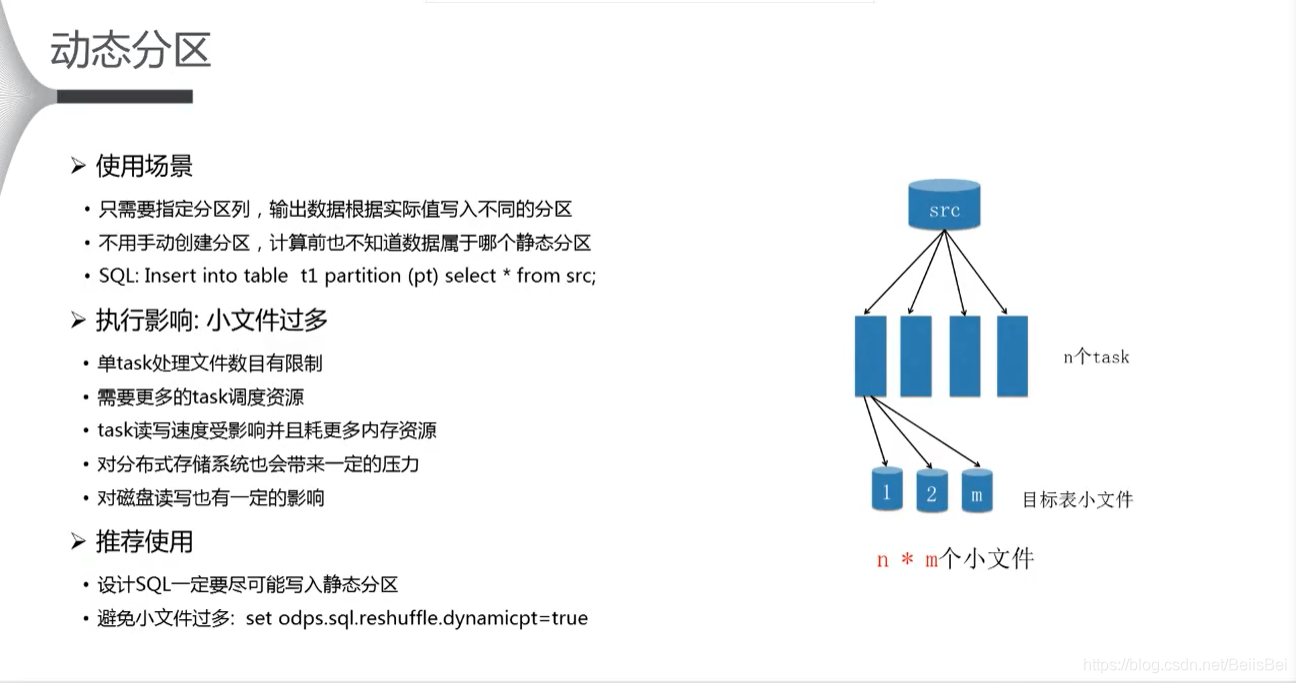
写入静态分区,优化数据存储
避免动态分区,防止小文件过多和计算长尾
3.2.2 列裁剪、条件过滤
- 只引用有效列
避免 select * from xxx
常量代替引用列,如count© -> count(1) // c not null
- 尽可能 pushdown 过滤条件
where a > 10 and (b > 1 or c < 1)
- Limit N
3.2.3 源表用户
- 合并不同SQL,一读多计算
读取相同源表可合并,节省IO和计算资源
对源表统计多种指标计算或者筛选不同数据处理
避免规模过大,运行时间过长
- Multi Insert ,动态分区,一读多写
同一SQL读取相同源表,系统会优化只读取一次
资源足够,也可以考虑拆分SQL,读取和计算更好并行,资源换时间
- 子查询合并
对于SQL中相同的子查询也会合并成一个源
尽可能保持子查询语句一样,触发合并

3.3 SQL 计算优化









3.4 SQL 整体优化
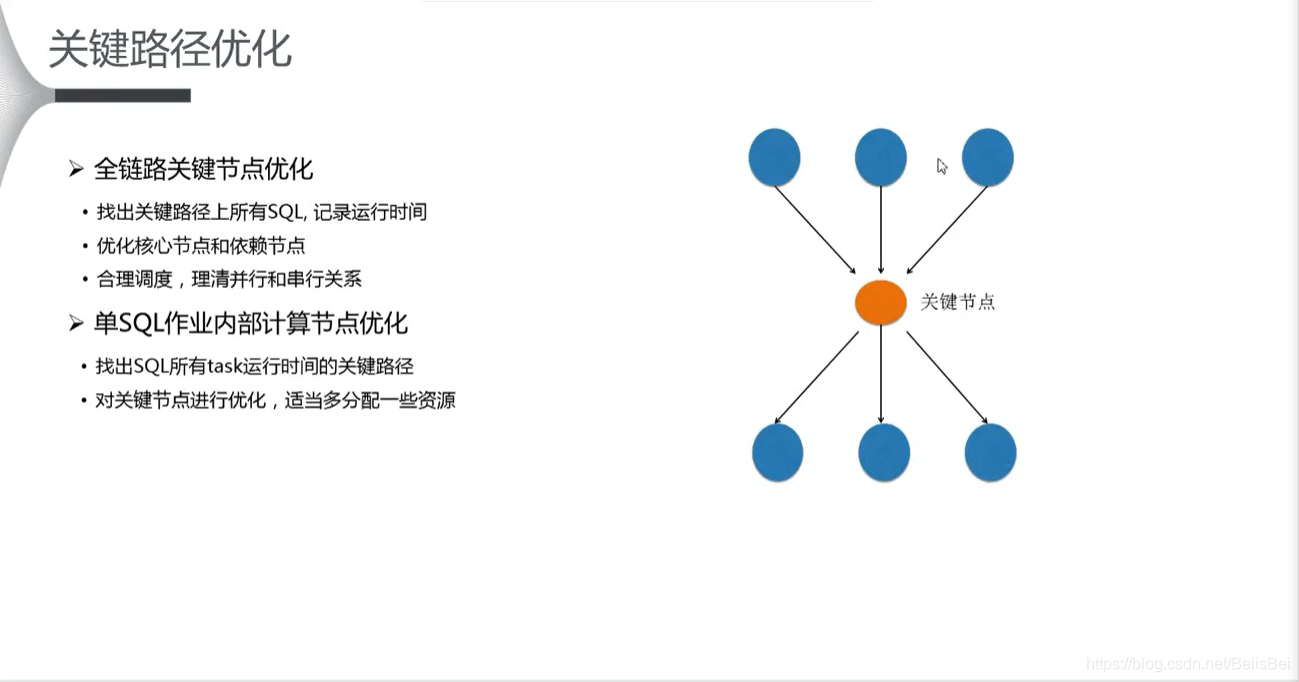
3.4.1 关键路径优化
3.4.2 长周期指标统计优化


3.5 总结
